



서 론
ILSVRC 2012[1] 이후 지난 10년간 빅데이터의 출현, 반도체 성능 향상 및 딥러닝 모델에 의하여 인공지능을 활용한 이미지 분류, 객체 인식, 물체 추적 등에 큰 진전이 이루어졌다. 그중에서도 이미지 분류기의 경우 얼굴 인식과 같은 특정 분야에서 사람의 인식 능력을 이미 뛰어넘는 등 상당한 발전을 보여주었다. 그럼에도 불구하고 규칙 기반으로 직접 특징(feature)을 추출하는 기존의 이미지 분류기와 딥러닝 기반 이미지 분류기는 설명 가능성이라는 부분에서 태생적으로 큰 차이를 가지고 있는데 이는 인공지능 및 딥러닝의 성능과 별개로 실제 활용 가능성 측면에서 큰 걸림돌로 작용하였다.
특히 지뢰 검출, 감시 정찰, 적군 탐지 등 잘못된 의사결정 하나가 중대한 문제를 초래하는 국방 이미지 분류 상황의 경우 인공지능의 설명 불가능성 문제로 인하여 인공지능보다 Linear Regression이나 Decision-tree, Rule-Base System 등 근거 설명이 가능한 의사결정 방식을 사용할 수밖에 없게 되고 이는 상대적으로 낮은 정확성으로 귀결되어 오히려 더 큰 문제를 일으킬 수 있는 요인으로 작용한다. 이 같은 문제를 극복할 수 있도록 인공지능의 판단 근거를 도출하여 그 활용도를 증대하고자 미국 방위고등연구계획국(DARPA)을 중심으로 설명 가능한 인공지능(eXplainable Artificial Intelligence, XAI) 접근법이 개발 및 확산되었다. 최근에는 Chat-GPT를 비롯하여 빅데이터를 기반으로 한 인공지능이 다양한 산업 분야에서 점점 더 중요해지고 널리 적용되면서 XAI 연구의 필요성이 더욱 커지고 있다.
XAI 연구 초기에는 간단한 인공지능 분류 모델을 설명하기 위하여 내부의 feature가 모델에 미치는 영향을 판단하는 기법인 PDP(Partial Dependence Plot)[2]가 제안되었다. 이는 특정한 feature 값을 선형적으로 변경해 가면서 분류 결과가 어떤 식으로 변해가는지를 그래프로 나타내는 기법으로 간단한 모델을 설명할 수 있지만 높은 모델 복잡도를 가진 딥러닝에서는 적용할 수 없다는 단점이 있다. 이를 극복한 SHAP (SHapley Additive exPlanations)[3]은 게임이론을 기반으로 하여 각 feature 값의 공헌도를 파악하는 방법으로 딥러닝에 적용이 가능하며 일관성 있는 모델 해석을 제공하지만 계산 리소스가 크고 이에 따라 샘플 계산량을 줄일 경우에는 큰 오차가 생길 수 있다. LIME (Local Interpretable Model-agnostic Explanation)[4] 알고리즘은 복잡한 전체 모델보다는 입력 데이터에 초점을 맞추어 딥러닝 모델을 분석하는 방법으로, 이미지를 입력값으로 하는 딥러닝 모델에서 출력값과 연관이 큰 슈퍼픽셀을 찾아 설명할 수 있으며 계산 리소스가 적어 딥러닝 모델의 복잡도가 매우 큰 경우에도 사용이 가능하다는 특징이 있다. 최신의 XAI 알고리즘은 PDP, SHAP, LIME과 같은 대표 알고리즘에 대한 변형 방법을 제외하면 해석 가능한 딥러닝 모델의 설계 등 모델 하나의 해석이 주를 이루는데, 이는 각각의 딥러닝 모델을 깊게 설명하고자 하는 시도라는 측면에서는 의미가 있지만 하나의 XAI 알고리즘을 여러 딥러닝 모델에 적용하는데는 어려움이 따른다. 이에 반해 LIME 알고리즘은 모델과 상관없이 적용할 수 있으므로 여러 딥러닝 모델에 대한 비교 연구가 가능하다는 장점이 있고, 대규모 모델에 대한 설명 가능성 제공이 용이하며 가장 대표적인 XAI 알고리즘임에도 불구하고 국방 데이터에 대한 적용 사례가 없어 본 연구에 활용하였다.
이와 함께 본 논문에서는 ILSVRC 대회 우승을 통해 성능을 인정받고 지속적인 개량이 이루어져 향후 발전 가능성이 높으며, 인셉션 모듈이라는 공통분모가 있어 비교가 용이한 인셉션 네트워크 파생 이미지 분류 딥러닝 모델인 Inception v3[5], Inception v2_resnet[6], Xception[7]의 출력 결과를 시각화하여 인간이 이해할 수 있는 형태로 제시하고 딥러닝 모델의 설명 가능성에 대하여 분석한다. 이를 위해 1. 한 가지 딥러닝 네트워크의 여러 출력값에 대한 분석과 2. 여러 딥러닝 네트워크의 한 가지 출력값에 대한 분석으로 두 가지 실험을 수행하고 실험 결과를 정리하였다. 이 과정에서 각 실험 별로 서로 다른 두 가지의 데이터를 입력하여 데이터에 따른 결과의 편향을 최소화하며 이미지 분류기의 활용도가 높고 설명 가능성과 판단에 대한 근거 수집이 필수적인 국방 분야에서 인공지능 기술 활용 가능성 제고를 위해 입력값으로 공개된 국방 데이터를 활용한다. 이를 통해 설명 가능한 인공지능 기술의 실전 활용 가능성을 탐색하고 어떤 인셉션 파생 네트워크가 국방 데이터에서 더 효과적으로 사용될 수 있는지 알아본다.
관련 연구
2.1 인셉션 네트워크
인셉션 네트워크[8]는 콘볼루션 신경망의 한 종류로, 특히 이미지 분류 분야에서 우수한 성능을 보여주며 대규모 데이터 세트에서 효과적인 학습이 가능한 딥러닝 모델이다. 기존의 딥러닝 모델 대비 인셉션 네트워크의 가장 큰 차별점은 Fig. 1과 같은 인셉션 모듈을 사용했다는 점이다. 인셉션 모듈은 각 레이어의 구성 시 큰 하나의 콘볼루션 커널을 대신하여 작은 커널들을 여러 개 사용하여 각각 다른 콘볼루션 연산을 적용하고 이들을 하나로 합치는 방식으로 작동하는데 이를 통해 기존 딥러닝 모델과 비교해 연산량을 20배가량 줄일 수 있다. 이 방식을 적용하면 파라미터 수의 감소뿐만 아니라 다양한 크기의 커널을 사용하므로 그림 내의 입력 데이터에서 더 많은 특징을 추출할 수 있게 되어 물체 인식 시 크기나 종류의 다양성에 대응하기 유리하다는 장점이 있다.

인셉션 네트워크는 구글에서 개발한 최초 버전인 Inception v1에서 시작하여 추후 문제점을 개선한 다양한 파생 모델이 개발되었다. Inception v2에서는 최초 버전인 Inception v1에서 네트워크가 깊어질수록 연산량과 파라미터 수가 증가하는 문제점을 개선하기 위하여 1x1 콘볼루션을 이용해 feature map을 재조정하는 factorization 방식을 통해 연산량과 파라미터 수를 추가로 감소시킴으로써 효율성 향상을 이룰 수 있었다. 이에 추가로 RMSProp[9]과 같은 기법을 사용하여 모델 개선을 시도한 Inception v3, residual block[10] 구조를 도입한 Inception v2_resnet, Inception v3에 도입된 separable convolution을 더욱 발전시켜 만든 Xception 모델 등이 있다. 이 외에도 다양한 인셉션 파생 네트워크가 제안되었으나 본 논문에서는 앞서 설명한 Inception v3, Inception v2_resnet, Xception 세 개의 모델에 대해 분석하였다.
2.2 XAI 및 LIME 알고리즘
XAI(eXplainable Artificial Intelligence)는 인공지능의 예측 결과를 사람이 이해할 수 있도록 설명할 수 있는 기술이다. 인공지능 모델의 예측 결과를 이해하기 위한 기초적인 방법으로는 모델의 예측 변수들(feature) 값을 임의의 값으로 치환하여 에러가 얼마나 커지는지 판단하는 feature importance가 있다. PDP(Partial Dependence Plot)는 이를 발전시킨 방법으로, feature importance 방법을 여러 개의 데이터에 적용하고 이를 2차원 그래프로 나타내어 이 그래프를 통해 두 변인의 관계를 사람이 이해할 수 있게 된다. 다만, 이 두 방법으로 예측 변수 간의 상대적 중요도를 나타낼 수 있으나 딥러닝과 같은 비교적 복잡한 모델에서는 의미 있는 분석이 어렵다. 딥러닝 모델의 예측 결과를 분석하기 위해서는 각 특성의 기여도에 따라 분해하는 SHAP(SHapley Additive exPlanations), 이미지 분류 모델에서 feature map의 중요도를 해석할 수 있도록 시각화하는 Grad-CAM(Gradient-weighted Class Activation Mapping)[11], 신경망의 각 뉴런이 예측 결과에 기여하는 정도를 계산하는 LRP(Layer-wise Relevance Propagation) [12], 로컬 예측 모델을 사용하여 선택된 데이터 인스턴스에 대한 모델 예측 결과를 설명하는 LIME(Local Interpretable Model-agnostic Explanations) 등이 널리 사용된다. 그중에서도 LIME 알고리즘은 블랙박스로 표현되는 딥러닝 네트워크를 설명할 수 있는 대표적인 알고리즘이다. LIME의 가장 큰 특징은 모델과 관계없이 해석이 가능한(model-agnostic) 알고리즘이라는 점인데 이는 모델의 종류와 무관하게 적용할 수 있어 VGGNet[13], ResNet, InceptionNet, EfficientNet[14]을 비롯한 최근 딥러닝 모델의 복잡성이 크게 증가한 상황에서도 적용할 수 있는 강점으로 작용한다.
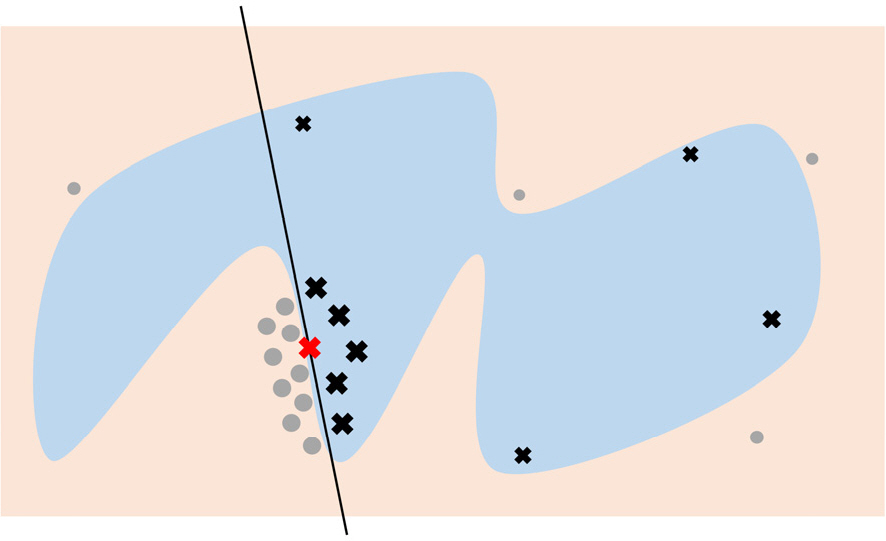
Fig. 2는 LIME 알고리즘을 통해 딥러닝을 이용한 이미지 분류처럼 복잡한 구분 규칙을 가진 경우에 구분 경계를 근사하는 과정을 단순화하여 나타낸 것이다. 그림에서 파란색과 빨간색으로 나뉘는 부분은 결정 경계로 높은 복잡도를 가지고 있다. 이 경우에 LIME은 ‘O’와 ‘X’자 모형의 데이터 여러 개를 생성하여 이들이 파란색에 속하는지 빨간색에 속하는지 판단하여 결정 경계를 찾아내고 이를 근사할 수 있는 검은 실선과 같은 선형 함수를 생성한다. 또 이렇게 생성된 선형 함수를 사용하여 어떤 변수가 중요한 역할을 하는지 파악하고 이를 통해 최종적으로 딥러닝 모델이 어떤 근거로 판단을 내린 것인지 설명할 수 있게 된다.
실험방법
인셉션 네트워크의 설명 가능성을 알아보기 위해 두 가지 실험을 진행하였다. 실험에 앞서 필요한 것 중 하나는 두 개의 실험에 사용될 동일한 입력 데이터를 선정하는 것이다. 이를 통해 실험1, 실험2에서 각 네트워크의 설명 가능성에 대한 비교뿐만 아니라 전체 결과에 대한 종합적인 분석도 가능하게 된다. 본 논문에서는 Fig. 3에 나타낸 국방 데이터로 실험을 수행하였으며 지상무기를 대표하는 전차 이미지(Tank)와 해상무기를 대표하는 항공모함 이미지(Warship)를 활용하였다. 또한, 각각 위키피디아의 대표 이미지를 사용하여 누구나 쉽게 데이터에 접근할 수 있도록 하였고 이에 따라 향후 추가적인 비교 연구가 가능하게 하였다. 입력 이미지는 딥러닝 모델로의 입력을 위해 299x299로 일괄 resize 하였으며 개발환경은 Jupyter Notebook 6.0.3 및 Python 3.8.3, 추가 라이브러리로는 딥러닝 모델 import를 위해 keras 2.4.3 및 tensorflow 2.3.0, 이미지 출력 및 결과 해석을 위하여 matplotlib 3.2.2, scikit-image 0.16.2, lime 0.2.0, numpy 1.18.5를 사용하였다. 이미지 분류 딥러닝 모델 학습에는 약 1400만개의 이미지와 1000개의 클래스를 가지며 이미지 분류 딥러닝에 가장 널리 사용되는 imagenet 데이터를 사용하였다.

실험1은 딥러닝을 통해 나온 이미지 분류 출력값을 살펴보고, 분류 결과가 실제 이미지와 다른 경우에는 어떤 설명 결과가 나오는지 알아보기 위한 실험이다. 이 실험은 Inception v2_resnet으로 수행하였으며, 같은 이미지에 대하여 Inception v2_resnet 분류 결과를 1∼4순위까지 나타낸 후 LIME 알고리즘을 적용하여 그 결과를 분석한다. 실험2는 각 인셉션 파생 네트워크별로 설명 가능성 비교 분석에 초점을 맞춘 실험이다. 여기서는 하나의 이미지에 대해 Inception v3와 Inception v2_resnet, Xception 세 가지 네트워크를 사용하였으며, 각각을 통과하였을 때 나오는 결과와 LIME 알고리즘 출력 결과를 정리하였다.
위 내용을 요약하면, 실험1에서는 한 가지 딥러닝 네트워크의 여러 출력값에 대해 분석하고 실험2에서는 여러 인셉션 파생 네트워크들의 한 가지 출력값에 대해 분석한다. 이를 도식화하여 두 실험에 대한 순서도를 Fig. 4에 나타내었다. 두 실험 모두 동일하게 Image1(Tank), Image2(Warship)를 입력으로 받는다. 실험1에서는 Inception v2_resnet을 통과하여 Top1∼4 결과를 얻은 후 LIME Image Explainer를 이용하여 각각의 출력 결과와 연관되지 않은 superpixel을 제거한 결과를 표시한다. 실험2에서는 Inception v3, Inception v2_resnet, Xception을 통과하여 각각 가장 높은 확률값을 나타낸 결과(Top1)를 얻은 후, LIME Image Explainer를 이용하여 결과를 얻는데 가장 많이 기여한 superpixel을 초록, 가장 적게 기여한 superpixel을 빨강으로 표시하여 같은 그림에 대한 사람의 이해와 인셉션 네트워크의 이해를 비교하고 각 모델 별로 LIME 설명 결과가 어떻게 달라지는지 비교 분석한다.
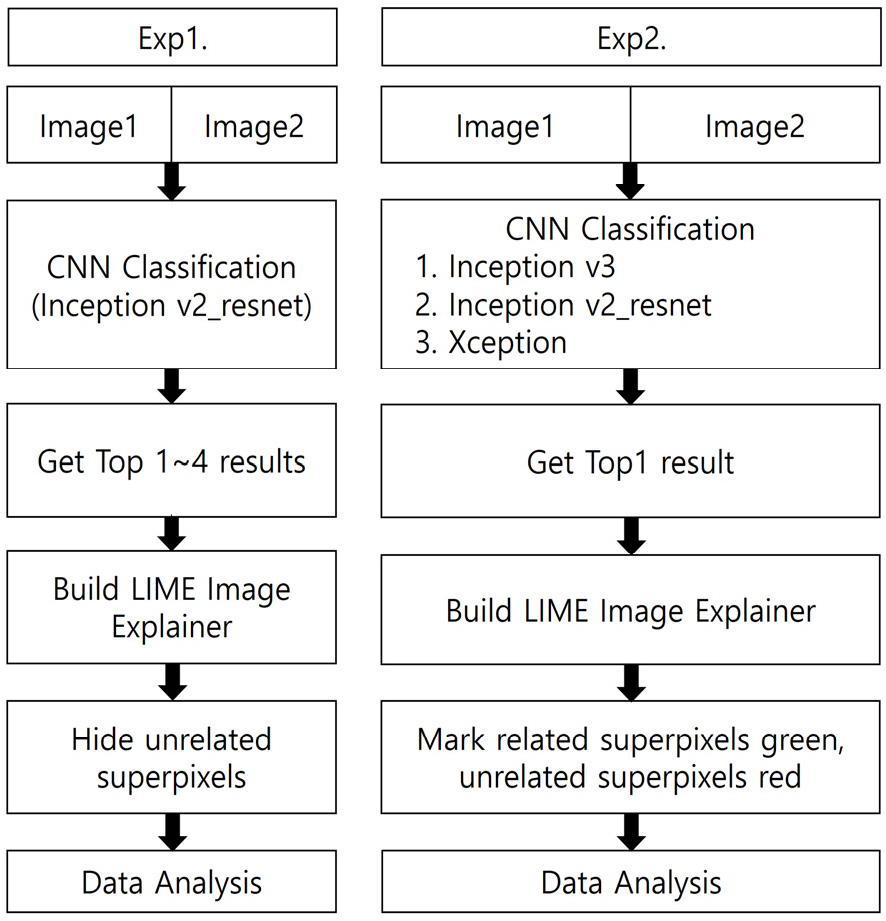
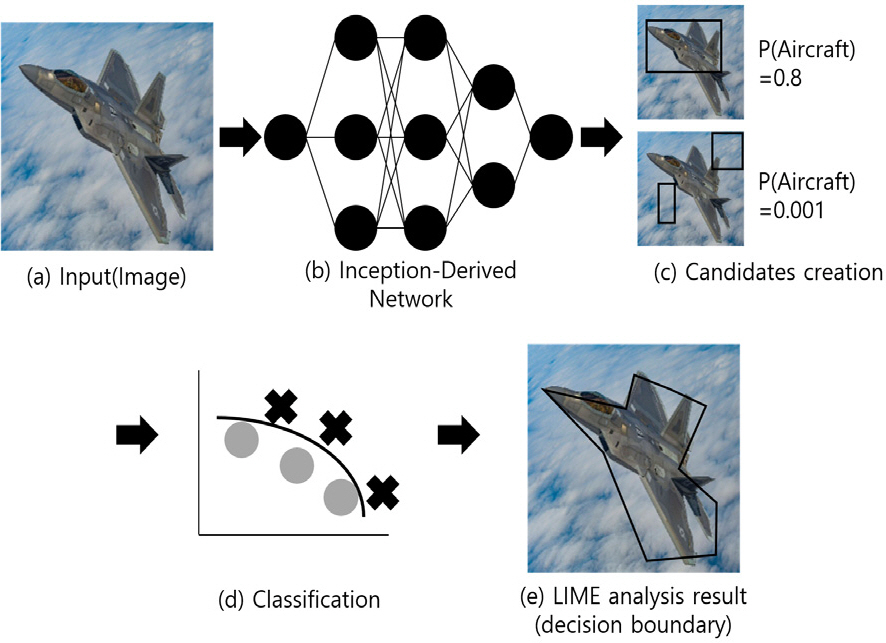
Fig. 5는 실험1, 2에서 제시한 인셉션 네트워크 파생 이미지 분류 딥러닝 모델의 설명 가능성 분석 상세과정을 도식화한 것이다. 우선 (a)와 같이 샘플 이미지(Aircraft)를 입력으로 받은 후, (b)에서 이를 인셉션 파생 네트워크의 입력값으로 하여 이미지 분류 결과를 출력한다. 이후 (c)와 같이 임의의 superpixel을 선택하여 다시 인셉션 파생 네트워크의 입력값으로 하여 딥러닝 이미지 분류 결과를 출력하면 Aircraft 의 대부분을 포함하는 첫 번째 이미지에서는 0.8 정도의 높은 confidence 값이 출력되고 Aircraft를 포함하지 않는 두 번째 이미지에서는 0에 가까운 값이 출력된다. 이 과정에서 Aircraft에 관련된 부분과 관련이 적은 부분으로 선형 분류하는 과정을 여러 번 반복해 가면서 (d)와 같은 선형 분류 모델을 학습하게 된다. 학습된 모델을 바탕으로 분류 확률값에 따라 가중치를 부여하면 (e)와 같은 결정 경계를 얻을 수 있게 되며, 최종적으로 이미지 전체 중 검은색 선 안쪽이 Aircraft와 관련성이 높다는 해석을 얻을 수 있게 된다.
실험결과 및 분석
4.1 실험1 결과 및 분석
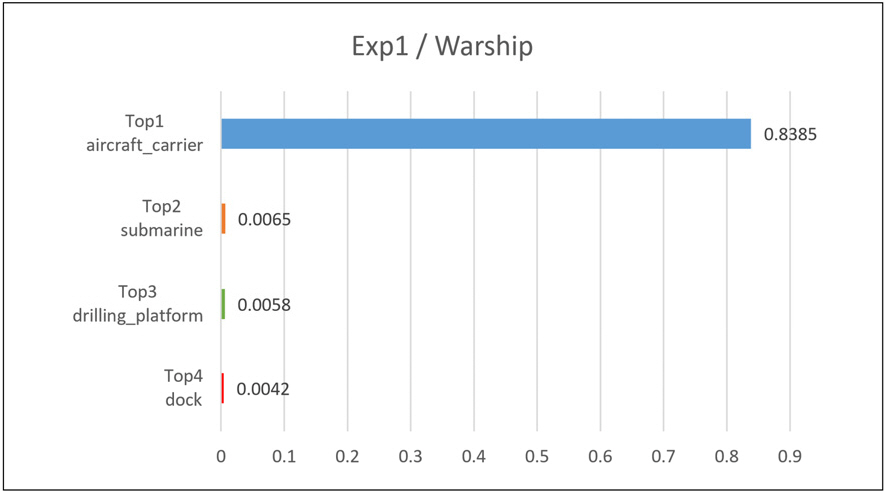
첫 번째 실험에서 Inception v2_resnet의 출력 결과는 Fig. 6, 7과 같다. Image1의 경우 Top1 classification은 tank, Top2 classification은 cannon으로 정확한 이미지 분류가 수행되었음을 확인하였다. 이에 반해 Top3, Top4의 경우 amphibian, projectile로 원본 이미지와 크게 관련이 없는 분류가 나왔다. Image2의 경우 Top1 classification은 aircraft_carrier, Top2 classification은 submarine으로 Top1은 정확한 이미지 분류가 수행되었으나 Top2는 어느 정도 유사성만 있는 결과로 출력되었다. Image2에서는 Top3, Top4도 정확하지는 않으나 어느 정도 관련 있는 결괏값이 나온 것을 확인할 수 있었다.
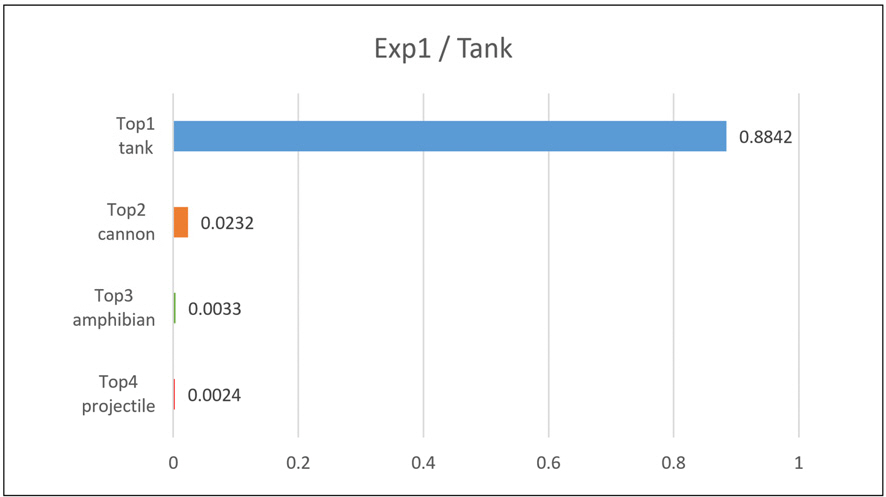
첫 번째 실험의 LIME 알고리즘 출력 결과는 Fig. 8, 9와 같다. Fig. 8은 Image1에 대하여 Top1∼4 출력 결과를 설명할 수 있는 superpixel을 남겨두고 설명성이 낮은 superpixel을 회색으로 마스킹한 결과를 나타낸다. Top1 prediction에서는 배경색들은 대부분 마스킹 되고 전차의 몸체와 바퀴 등 중요한 부분들이 남아 있어 딥러닝 모델이 사람과 비슷한 과정으로 사물을 설명하고 있는 것을 확인할 수 있었다. 또한 Top2 prediction 인 cannon의 경우도 이와 마찬가지로 사람의 해석과 같은 부분을 정확하게 마스킹하는 것을 관찰하였으며, LIME 알고리즘의 유용성을 확인할 수 있었다. 다만 Top3, Top4 prediction의 경우는 Tank와 관련성이 낮은 결과를 얻었는데, 이는 Fig. 6에서 볼 수 있듯이 Top1, Top2에 비해 Top3, Top4의 confidence 값이 현저히 낮은 것에 기인한 것으로 해석해 볼 수 있다.
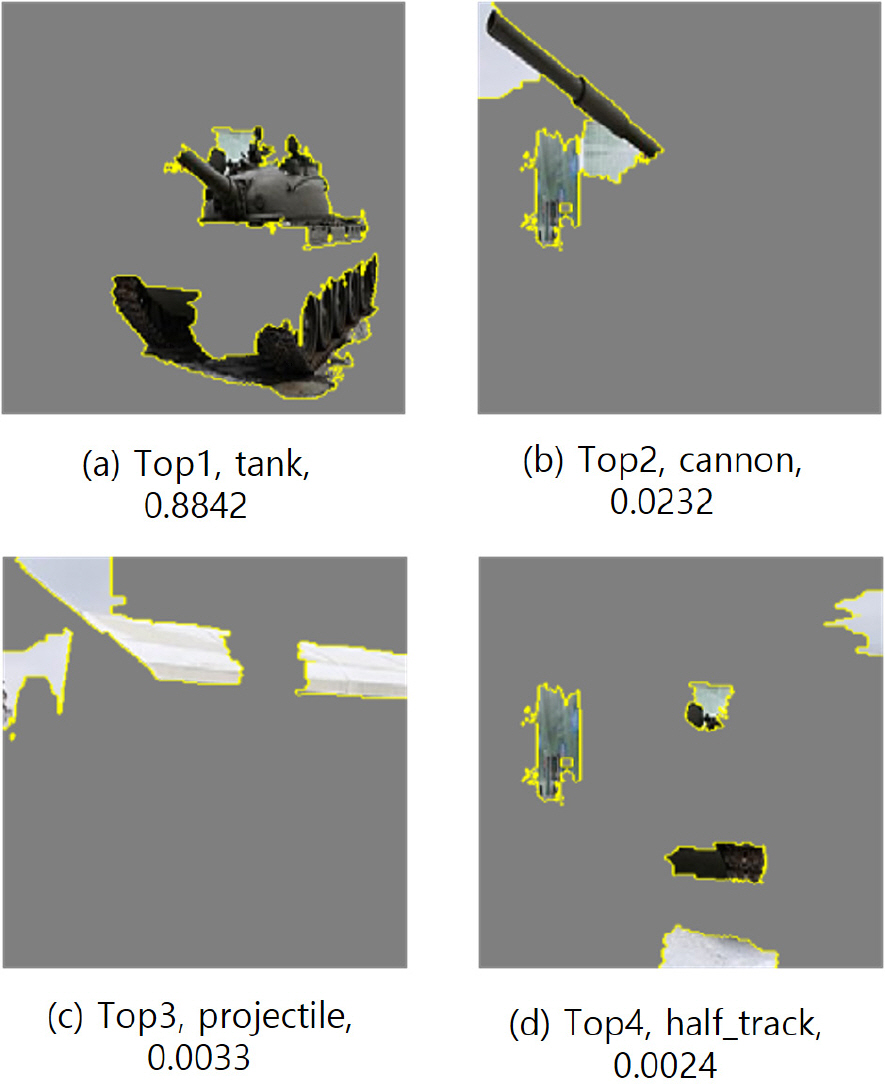
Fig. 9.
Experimental results of Exp1 using inception v2_resnet and LIME algorithm for Image2 (Warship)

Fig. 9는 Image2에 대하여 마찬가지 방법으로 Top1∼4 출력 결과의 설명성이 높은 superpixel을 남겨두고 상대적으로 낮은 superpixel을 회색으로 마스킹한 결과를 나타내고 있다. Image2의 분류 값 중 가장 confidence 가 높은 항목은 aircraft_carrier로 사진상의 배경을 대부분 제거하였으나 사진 해상도의 한계와 입력 데이터인 항공모함 구조의 복잡성으로 인해 항공모함 전체를 표현하지는 못하였다. 대신, 항공모함 위의 포신 부분을 정확하게 표현하여 어느 정도 신뢰성을 가지는 것을 확인할 수 있었다. Top2∼4의 경우 Image1의 Top3∼4와 같이 aircraft_carrier와 관련성이 낮은 결과를 얻었으나 이는 Fig. 7에서 나타난 것처럼 Top2∼4의 confidence가 상대적으로 낮은 것에 기인한 것으로 해석해 볼 수 있다. 두 실험에서 LIME 알고리즘 커널의 너비는 0.25로 설정하였으며, 이 값을 크게 설정할 경우 이미지의 분류와 관련한 더 많은 부분을 커버할 수 있지만 관련 없는 부분이 새로 추가될 수 있다.
4.2 실험2 결과 및 분석
두 번째 실험에서는 Inception v3, Inception v2_resnet, Xception 네트워크 각각의 classification 출력 결과 중 Top1에 대하여 LIME 알고리즘 출력 결과를 비교 분석하였다.
LIME 알고리즘 분석 결과의 해석을 위해, Table 1, 2에서 인셉션 파생 네트워크의 이미지 분류 결과를 나타내었다. Table 1은 Image1에서 딥러닝 모델의 Top1∼4 출력값을 표시하며 Table 2는 Image2에서 딥러닝 모델의 Top1∼4 출력값을 표시한다. Table 1에 있는 Image1의 분류 결과를 보면, Inception v3와 Inception v2_resnet, Xception 네트워크에서 모두 Top1, Top2 출력 결과가 각각 tank, cannon으로 같은 것을 확인할 수 있다. 이를 통해 Inception v2_resnet 뿐만 아니라 각 모델이 모두 올바른 출력값을 내는 것을 확인할 수 있었다. Top1의 confidence 값을 비교해보면 Xception, Inception v2_resnet, Inception v3 순으로 높게 나온 것을 확인할 수 있었다. Top3와 Top4의 결과는 사진과 크게 관계가 없는 것으로 나왔으나 이는 출력값에 대한 confidence가 상대적으로 낮은 것에 기인한 것으로 생각된다.
Table 1.
Inception-derived network classification results for Image1
Table 2.
Inception-derived network classification results for Image2
Table 2의 Image2 출력 결과를 확인해보면 Inception v3와 Inception v2_resnet, Xception 네트워크에서 모두 Top1 출력 결과는 aircraft_carrier(항공모함)로 같은 것으로 나왔다. 그러나 Image1과 다르게 Image2에서는 Top2의 결과가 모두 같지는 않았다. 다만 Top2∼4 결과를 살펴보면 confidence 값 자체는 크지 않았지만, Input data와 비슷한 종류의 사물이 출력되는 것을 확인할 수 있었다.
Fig. 10은 Table 1, 2의 결과 중 Top1 출력 결괏값과 LIME 알고리즘을 이용해 각 이미지 분류기가 어떤 근거를 가지고 이미지를 분류하였는지를 함께 나타낸 것이다. 이 결괏값에서 LIME Image Explainer는 이미지의 분류 결과 출력에 크게 기여한 부분을 녹색으로 마스킹하고 출력 결과와 상반되는 부분을 적색으로 마스킹한다.

전체적인 결과를 분석해 보면, Tank 이미지의 경우 세 개의 네트워크 모두에서 준수한 성능을 보여주었다. 특히 탱크 본체뿐만 아니라 포신의 일부분을 마스킹한 것으로 보아 딥러닝을 통한 이미지 분류에서 사람의 인지와 비슷한 것을 볼 수 있었고 그중에서도 Xception 네트워크의 LIME 알고리즘 출력 결과는 탱크의 바퀴와 포신 등 주요 부분을 녹색으로 마스킹한 결과를 나타내어 LIME 알고리즘을 통해 딥러닝 모델 예측의 신뢰성을 확인할 수 있었다. Warship의 출력 결과도 이와 비슷하였는데 Inception v3 및 Inception v2_resnet의 경우 녹색 마스킹이 항공모함뿐만 아니라 바다 일부분도 포함하였지만 Xception 네트워크의 출력 결과에서는 항공모함 본체 부분만 녹색으로 마스킹 되어 50 % 이상의 픽셀을 커버하였을 뿐만 아니라 분류 결과와 관련 없는 부분은 적색으로 마스킹 되어 Xception 네트워크가 Inception v3, Inception v2_resnet 에 비해 높은 설명 가능성을 지니고 있음을 확인할 수 있었다.
이는 Xception 네트워크가 81개의 레이어로 이루어져 있으며 inception v3의 189개, inception v2의 449개에 비해 낮은 복잡도를 가지고 있음에도 올바른 출력값을 낼 수 있어 다른 두 개의 네트워크에 비해 효율적인 것뿐만 아니라 더 높은 설명 가능성을 제공해준다는 측면에서 실험에 사용된 세 모델 중 국방 인공지능 기술의 실전 적용 시 가장 적합한 모델이라는 것을 생각하게 해준다.
결론 및 고찰
본 논문에서는 국방 데이터와 인공지능을 이용한 이미지 분류기 중 효율 및 정확성 측면에서 널리 사용되는 모델인 인셉션 네트워크 및 선형 분석으로 딥러닝 모델을 설명할 수 있는 LIME 알고리즘을 사용하여 이미지 분류 출력 결과를 살펴보고 인셉션 파생 네트워크 모델들의 설명 가능성에 대하여 고찰하였다. 이 과정에서 Inception v2_resnet을 이용한 비교 분석 연구(실험1)를 통해 LIME 알고리즘이 사람과 비슷한 방식으로 그림을 해석하는 것을 확인하였고 Inception v3, Inception v2_resnet, Xception 모델 각각에 대한 Top1 결과 비교 분석 연구(실험2)를 통해 LIME을 이용하여 여러 딥러닝 모델들의 효율성과 실전 활용 가능성을 비교할 수 있다는 것을 확인할 수 있었다. 향후 추가로 개선되는 인셉션 파생 네트워크 및 VGGNet, EfficientNet 등 여러 딥러닝 네트워크에 관하여 비슷한 연구를 수행한다면, 국방 분야뿐만 아니라 자율주행, 의료, 금융 등 각 활용 분야에서 더욱 설명 가능성이 높은 딥러닝 모델을 찾고 이를 실제로 활용할 수 있을 것이다. 이를 통해 인공지능의 적용 분야가 넓어지고 사람이 이해할 수 있는 의사결정이 가능하게 되어, 국방 분야를 포함한 사회 전반에서 업무 효율을 증대할 수 있을 것으로 기대된다.




