



1. м„ң лЎ
лқјл§Ң 분кҙ‘мқҖ л¬јм§Ҳмқҳ кі мң нҠ№м§•мқ„ лӮҳнғҖлӮҙлҠ” мҠӨнҺҷнҠёлҹјмңјлЎңмҚЁ нҷ”н•ҷ л¬јм§Ҳ нғҗм§Җм—җ мң мҡ©н•ҳкІҢ нҷңмҡ©лҗңлӢӨ. нҠ№нһҲ лқјл§Ң 분кҙ‘кё°лҠ” м ‘мҙү м—ҶмқҙлҸ„ л¬јм§Ҳ 분м„қмқҙ к°ҖлҠҘн•ҳкё°м—җ мһ‘м „ мғҒнҷ©м—җм„ң нҷ”н•ҷ мҳӨм—ј м—¬л¶ҖлҘј нғҗм§Җн•ҳлҠ” лҚ° мӮ¬мҡ©н• мҲҳ мһҲкі , мқҙм—җ л”°лқј м§Җн‘ңл©ҙм—җм„ң л№„м ‘мҙүмңјлЎң нҷ”н•ҷ л¬јм§Ҳмқ„ нғҗм§Җн•ҳкё° мң„н•ң лқјл§Ң 분кҙ‘лІ•м—җ лҢҖн•ң м—°кө¬[1-5]к°Җ нҷңл°ңнһҲ 진н–үлҗҳкі мһҲлӢӨ. мқҙл•Ң, мӢӨм ң нҷ”н•ҷ мҳӨм—ј нғҗм§ҖлҘј мң„н•ҙм„ңлҠ” мёЎм •лҗң лқјл§Ң 분кҙ‘мқҙ м–ҙл–Ө лҸ…м„ұ л¬јм§Ҳмқҳ 분кҙ‘кіј лҸҷмқјн•ңм§Җ 분별н•ҙлӮҙлҠ” кіјм •мқҙ н•„мҡ”н•ҳкі , кё°кі„н•ҷмҠө лӘЁлҚёмқҙ мқҙ мқјмқ„ н• мҲҳ мһҲлҸ„лЎқ н•ҷмҠөлҗңлӢӨл©ҙ лҸ…м„ұ нҷ”н•ҷ нғҗм§ҖлҘј мӢ мҶҚн•ҳкі м •нҷ•н•ҳкІҢ мҲҳн–үн• мҲҳ мһҲмқ„ кІғмқҙлӢӨ.
мөңк·ј л”Ҙлҹ¬лӢқмқҙ лӢӨл°©л©ҙмңјлЎң мӮ¬лһҢм—җ н•„м Ғн•ҳкі , л•Ңл•ҢлЎңлҠ” л„ҳм–ҙм„ңлҠ” кІ°кіјл“Өмқ„ ліҙм—¬мЈјкі мһҲлӢӨ[6]. мқҙлҹ¬н•ң м җмқ„ лҜёлЈЁм–ҙ ліј л•Ң, лқјл§Ң 분кҙ‘м—җ л”Ҙлҹ¬лӢқ кё°л°ҳмқҳ лӘЁлҚёмқ„ м Ғмҡ©н•ҳл©ҙ лқјл§Ң 분м„қ кіјм •мқҳ мһҗлҸҷнҷ”к°Җ к°ҖлҠҘн• кІғмңјлЎң кё°лҢҖн• мҲҳ мһҲлӢӨ[7]. л”Ҙлҹ¬лӢқмқҖ л§ҺмқҖ лҚ°мқҙн„°лҘј мӮ¬мҡ©н• мҲҳлЎқ лҚ” лҶ’мқҖ м •нҷ•лҸ„мқҳ лӘЁлҚёмқ„ м–»мқ„ мҲҳ мһҲм§Җл§Ң[8] лқјл§Ң 분кҙ‘мқҖ лӢӨм–‘н•ң нҷҳкІҪм—җм„ң лҚ°мқҙн„°лҘј мҲҳ집н•ҳлҠ” кІғмқҙ м–ҙл Өмҡҙ мғҒнҷ©мқҙ л§Һкі , мқҙкІғмқҙ л”Ҙлҹ¬лӢқмқ„ м Ғмҡ©н• л•Ңмқҳ м ңм•Ҫмқҙ лҗңлӢӨ. мҳҲлҘј л“Өм–ҙ, лқјл§Ң 분кҙ‘кё°лҘј нҷңмҡ©н•ҙ м§Җн‘ңл©ҙм—җм„ң лҸ…м„ұ л¬јм§Ҳмқ„ кІҖм¶ңн•ҳлҠ” мһҗлҸҷнҷ”лҗң л”Ҙлҹ¬лӢқ лӘЁлҚёмқ„ м–»кі мһҗ н•ҳлҠ” кІҪмҡ°, к°Ғкё° лӢӨлҘё нҷҳкІҪм—җм„ң лҸ…м„ұ л¬јм§Ҳмқҳ лқјл§Ң 분кҙ‘мқ„ м—¬лҹ¬ лІҲ мёЎм •н•ҙм•ј н•ҳлҠ”лҚ° мқҙлҘј мң„н•ҙм„ нҒ° 비мҡ©мқҙ л“Өм–ҙк°ҖкІҢ лҗңлӢӨ.
л”°лқјм„ң ліё л…јл¬ём—җм„ңлҠ” мқҙлҹ¬н•ң л¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ҙ, к°Ғк°Ғмқҳ л¬јм§Ҳм—җ н•ҙлӢ№н•ҳлҠ” лқјл§Ң 분кҙ‘ лҚ°мқҙн„°к°Җ 충분н•ҳм§Җ лӘ»н•ң мғҒнҷ©м—җм„ң л¬јм§Ҳлі„лЎң к·ёмҷҖ мң мӮ¬н•ң лӘЁмқҳ мӢ нҳёлҘј мғқм„ұн•ҳлҠ” м•Ңкі лҰ¬мҰҳмқ„ м ңм•Ҳн•ңлӢӨ. мҡ°м„ лқјл§Ң 분кҙ‘мқҳ нҠ№м„ұмқ„ мң м§ҖмӢңнӮӨлҠ” 4к°Җм§Җ мҲҳн•ҷм Ғ ліҖнҷҳмқ„ м„Өкі„н•ҳмҳҖкі , мҳӨнҶ мқёмҪ”лҚ”(autoencoder), ліҖ분м Ғ мҳӨнҶ мқёмҪ”лҚ”(VAE; Variational Autoencoder)[9], м ҒлҢҖм Ғ мғқм„ұ мӢ кІҪл§қ(GAN; Generative Adversarial Networks)[10]лҘј н•ҷмҠөн•ң нӣ„, мқҙлҘј нҶ лҢҖлЎң лҸ…м„ұ л¬јм§Ҳ Dimethyl Methyl Phosphonate(DMMP)мҷҖ 2-Chloroehtyl Ethyl Sulfide(2-CEES)м—җ лҢҖн•ң лӘЁмқҳ лқјл§Ң 분кҙ‘ лҚ°мқҙн„°м…Ӣмқ„ кө¬м¶•н•ҳмҳҖлӢӨ.
ліё л…јл¬ёмқҙ кё°м—¬н•ҳлҠ” л°”лҠ” лӢӨмқҢкіј к°ҷлӢӨ. мІ«м§ё, м§Ғм ‘м Ғмқё мӢӨн—ҳ м—Ҷмқҙ л§ҺмқҖ м–‘мқҳ лӘЁмқҳ лҸ…м„ұ л¬јм§Ҳ лҚ°мқҙн„°лҘј мғқм„ұн•ҳмҳҖлӢӨ. мқҙлҠ” мӢӨн—ҳмқ„ мң„н•ң 비мҡ© м Ҳк°җкіј лҚ”л¶Ҳм–ҙ к°•л Ҙн•ң кё°кі„н•ҷмҠө лӘЁлҚё н•ҷмҠөм—җ лҸ„мӣҖмқҙ лҗңлӢӨ. л‘ҳм§ё, л””л…ёмқҙ징м—җ мӮ¬мҡ©лҗҳлҠ” кё°лІ•мқ„ м Ғм ҲнһҲ нҷңмҡ©н•ҳм—¬ лқјл§Ң 분кҙ‘ лҚ°мқҙн„°м—җм„ң н”јнҒ¬ мң„м№ҳлҘј мң м§Җн•ң мұ„лЎң лӢӨм–‘н•ң ліҖнҳ•мқ„ к°Җн• мҲҳн•ҷм Ғ ліҖнҷҳл“Өмқҙ м„Өкі„лҗҳм—ҲлӢӨ. лӢЁмҲңнһҲ мӢ нҳё лҚ°мқҙн„°м—җ л…ёмқҙмҰҲлҘј лҚ”н•ҳлҠ” кІғмқҙ м•„лӢҢ лқјл§Ң 분кҙ‘мқҳ м„ұм§Ҳмқ„ ліҙмЎҙн•ҳлҠ” кІғм—җ нҠ№нҷ”лҗң ліҖнҷҳмқ„ м ңм•Ҳн•ҳмҳҖлӢӨ. м…Ӣм§ё, мғқм„ұн•ң лҚ°мқҙн„°лЎң мӢ¬мёө мғқм„ұ лӘЁлҚёмқ„ н•ҷмҠөмӢңмјң лҚ”мҡұ лӢӨм–‘н•ң лҚ°мқҙн„°м…Ӣмқ„ кө¬м¶•н•ҳмҳҖлӢӨ. 2мһҘм—җм„ңлҠ” кҙҖл Ё м—°кө¬лҘј к°„лһөнһҲ мҡ”м•Ҫн•ҳкі , 3мһҘм—җм„ң лӘЁмқҳ лҚ°мқҙн„° мғқм„ұ л°©лІ•мқ„ м„ӨлӘ…н•ңлӢӨ. 4мһҘм—җм„ңлҠ” мғқм„ұлҗң лҚ°мқҙн„°лҘј мӢңк°Ғнҷ”н•ҙ 분м„қн•ҳкі , мқҙлҘј кё°л°ҳмңјлЎң лӘЁмқҳ лҚ°мқҙн„°м…Ӣмқ„ к°ңм„ н•ңлӢӨ.
2. кё°мҲ нҳ„нҷ© 분м„қ
ліё м—°кө¬м—җм„ңлҠ” лқјл§Ң 분кҙ‘мқҳ лӘЁмқҳ лҚ°мқҙн„° мғқм„ұмқ„ лӢӨлЈЁкі мһҗ н•ҳл©° мқҙлІҲ мһҘм—җм„ңлҠ” лӢӨм–‘н•ң мёЎл©ҙмқҳ м„ н–ү м—°кө¬л“Өмқ„ мҡ”м•Ҫн•ңлӢӨ.
2.1 лқјл§Ң 분кҙ‘кіј л”Ҙлҹ¬лӢқ
лқјл§Ң 분кҙ‘мқҙ м–ҙл–Ө л¬јм§Ҳмқ„ лӮҳнғҖлӮҙлҠ”м§Җ 분лҘҳн•ҳкұ°лӮҳ, мЈјм–ҙ진 лқјл§Ң 분кҙ‘м—җм„ң л…ёмқҙмҰҲлҘј м ңкұ°н•ҳлҠ” л“ұ лӢӨм–‘н•ң мқҳлҸ„мқҳ м•Ңкі лҰ¬мҰҳ, л”Ҙлҹ¬лӢқ лӘЁлҚёмқҙ м—°кө¬лҗҳкі мһҲлӢӨ. л…ёмқҙмҰҲлҘј м ңкұ°н•ҳкё° мң„н•ҙ мӣЁмқҙлё”лҰҝ ліҖнҷҳмқ„ нҷңмҡ©н•ҳкұ°лӮҳ л””л…ёмқҙ징 мҳӨнҶ мқёмҪ”лҚ”, GANмқ„ н•ҷмҠөмӢңнӮӨлҠ” м—°кө¬к°Җ 진н–үмӨ‘мқҙлӢӨ[11-13]. лҳҗн•ң лқјл§Ң 분кҙ‘ 분лҘҳлҘј мң„н•ң CNNлӘЁлҚёмқ„ н•ҷмҠөмӢңнӮӨкұ°лӮҳ GANмқҳ нҢҗлі„мһҗлҘј нҷңмҡ©н•ҳлҠ” м ‘к·јлҸ„ мқҙлЈЁм–ҙм§Җкі мһҲлӢӨ[14,15]. лқјл§Ң 분кҙ‘м—җ л”Ҙлҹ¬лӢқ лӘЁлҚёмқ„ н•ҷмҠөмӢңнӮӨлҠ” мӢңлҸ„л“Өмқҙ м„ұкіөм Ғмқё кІ°кіјлҘј ліҙм—¬мЈјлҠ” к°ҖмҡҙлҚ°, м ҒмқҖ к°ңмҲҳмқҳ лқјл§Ң 분кҙ‘л§Ңмқ„ к°Җм§Җкі м¶©л¶„н•ң м–‘мқҳ лӘЁмқҳ лҚ°мқҙн„°лҘј мғқм„ұн• мҲҳ мһҲлҠ” м•Ңкі лҰ¬мҰҳмқҖ лҸ…м„ұ нҷ”н•ҷ нғҗм§Җ л“ұ лӢӨм–‘н•ң л¬ём ңм—җ нҷңмҡ©лҗ мҲҳ мһҲмқ„ кІғмқҙлӢӨ.
2.2 мӢ нҳё лҚ°мқҙн„° мҰқк°• м•Ңкі лҰ¬мҰҳ
лҚ°мқҙн„° мҰқк°•мқҖ к°•л Ҙн•ң л”Ҙлҹ¬лӢқ лӘЁлҚёмқ„ н•ҷмҠөмӢңнӮӨкё° мң„н•ң мӨ‘мҡ”н•ң мҡ”мҶҢлЎңмҚЁ мҰқк°•кіј кҙҖл Ён•ң л§ҺмқҖ м—°кө¬к°Җ мқҙлЈЁм–ҙм§Җкі мһҲлӢӨ. мӢңкі„м—ҙ лҚ°мқҙн„°лҘј мӢңк°„ лҸ„л©”мқё лҳҗлҠ” мЈјнҢҢмҲҳ лҸ„л©”мқём—җм„ң л…ёмқҙмҰҲлҘј лҚ”н•ҳлҠ” л“ұмқҳ л°©мӢқмңјлЎң мҰқк°•н•ҳкұ°лӮҳ, мӢ¬мёө мғқм„ұ лӘЁлҚёмқ„ нҷңмҡ©н•ҳлҠ” л°©лІ•л“Өмқҙ м—°кө¬лҗҳм—ҲлӢӨ[16]. нҠ№нһҲ GANкіј к°ҷмқҖ л”Ҙлҹ¬лӢқ кё°л°ҳмқҳ л°©лІ•мқ„ нҷңмҡ©н•ҙ лӘЁмқҳ лҚ°мқҙн„°лҘј мғқм„ұн•ҳлҠ” мӢңлҸ„к°Җ л§Һм•ҳлӢӨ[17,18]. нҠ№м • лҸ„л©”мқёмқҳ лҚ°мқҙн„°м—җ лҢҖн•ҙм„ңлҠ” лҚ°мқҙн„°мқҳ м„ұм§Ҳмқ„ мң м§Җн•ҳлҠ” мҰқк°• л°©лІ•л“Өмқҙ м„ұкіөм Ғмқё кІ°кіјлҘј м–»м–ҙлғҲкі , мӣЁм–ҙлҹ¬лё” м„јм„ң лҚ°мқҙн„°, лҮҢнҢҢ лҚ°мқҙн„° л“ұм—җ кҙҖн•ң м—°кө¬к°Җ мқҙлЈЁм–ҙмЎҢлӢӨ[19,20].
нҠ№м •н•ң м„јм„ң лҚ°мқҙн„°л“Өм—җ лҢҖн•ң л§ҺмқҖ мҰқк°• кё°лІ•мқҙ м—°кө¬лҗң лҚ° л°ҳн•ҳм—¬ лқјл§Ң 분кҙ‘ лҚ°мқҙн„°м—җ кҙҖн•ҙм„ңлҠ” лҚ°мқҙн„°мқҳ м„ұм§Ҳмқ„ мң м§Җн•ҳлҠ” ліҖнҷҳм—җ кҙҖн•ң м—°кө¬к°Җ мқҙлӨ„м§Җм§Җ м•Ҡм•ҳлӢӨ. кё°мЎҙмқҳ мӢ нҳё мҰқк°• кё°лІ•л“ӨмқҖ лқјл§Ң 분кҙ‘м—җ м Ғн•©н•ҳм§Җ м•Ҡкё°м—җ, ліё м—°кө¬м—җм„ңлҠ” лқјл§Ң 분кҙ‘мқҳ нҠ№мғүмқ„ л°ҳмҳҒн•ң лҚ°мқҙн„° мҰқк°• кё°лІ•мқ„ м ңм•Ҳн•ңлӢӨ.
3. м—°кө¬ л°©лІ•
мқҙлІҲ мһҘм—җм„ңлҠ” лқјл§Ң 분кҙ‘мқҳ мҰқк°• м•Ңкі лҰ¬мҰҳмқ„ м ңм•Ҳн•ңлӢӨ. 3.1м Ҳм—җм„ңлҠ” лҸ…м„ұ л¬јм§Ҳ лҚ°мқҙн„°м—җ кҙҖн•ҙ м„ӨлӘ…н•ҳкі , 3.2м Ҳм—җм„ңлҠ” мҲҳн•ҷм Ғ ліҖнҷҳмңјлЎң мҰқк°•лҗң лҚ°мқҙн„°лҘј мғқм„ұн•ҳлҠ” л°©лІ•мқ„, 3.3м Ҳм—җм„ңлҠ” н•ҙлӢ№ ліҖнҷҳл“ӨлЎң мғқм„ұлҗң лҚ°мқҙн„°лҘј мқҙмҡ©н•ң кё°кі„н•ҷмҠө лӘЁлҚёмқҳ н•ҷмҠө л°©лІ•мқ„ мҶҢк°ңн•ңлӢӨ.
3.1 лқјл§Ң 분кҙ‘ лҚ°мқҙн„° нҡҚл“қ
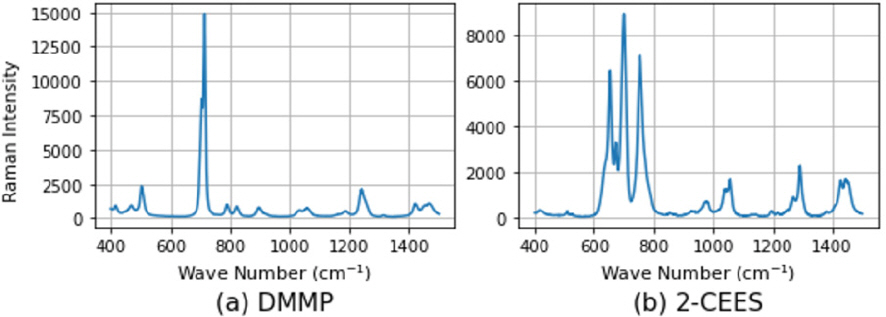
лӘЁмқҳ лҚ°мқҙн„°м…Ӣ кө¬м¶•мқ„ мң„н•ҙ лҸ…м„ұ л¬јм§Ҳ DMMPмҷҖ 2-CEESлҘј мӮ¬мҡ©н•ңлӢӨ. л Ҳмқҙм Җ нҢҢмһҘ 532 nm, мёЎм •мӢңк°„ 5мҙҲ, л Ҳмқҙм Җ м§ҖлҰ„ 300 ОјmлҘј мӮ¬мҡ©н•ҙ л¬јм§Ҳлі„лЎң н•ҳлӮҳмқҳ 분кҙ‘ лҚ°мқҙн„°лҘј мёЎм •н–Ҳкі , Fig. 1мқҖ мёЎм •лҗң лҚ°мқҙн„°лҘј ліҙм—¬мӨҖлӢӨ. мӣЁмқҙлёҢ л„ҳлІ„ 400 cm-1л¶Җн„° 1500 cm-1к№Ңм§Җ 0.5 cm-1 к°„кІ©мқё кёёмқҙ 2200мқҳ лҚ°мқҙн„°лҘј мһ…л Ҙ мӢ нҳёлЎң мӮ¬мҡ©н•ҳмҳҖлӢӨ. ліё м—°кө¬м—җм„ң мӮ¬мҡ©лҗң лҚ°мқҙн„°м—җлҠ” л…ёмқҙмҰҲмҷҖ лІ мқҙмҠӨлқјмқёмқҙ кҙҖмёЎлҗҳм§Җ м•Ҡм•„ лі„лҸ„мқҳ м „мІҳлҰ¬ кіјм •мқҙ м—Ҷмқҙ мёЎм •лҗң 분кҙ‘ лҚ°мқҙн„°лҘј м§Ғм ‘ м—°кө¬м—җ нҷңмҡ©н•ҳмҳҖлӢӨ. л§Ңмқј мёЎм •лҗң лқјл§Ң 분кҙ‘м—җ л…ёмқҙмҰҲмҷҖ лІ мқҙмҠӨлқјмқёмқҙ кҙҖмёЎлҗ кІҪмҡ° л””л…ёмқҙ징과 лІ мқҙмҠӨлқјмқё м ңкұ°к°Җ мӮ¬м „м—җ н•„мҡ”н• кІғмқҙлӢӨ.
3.2 мҲҳн•ҷм Ғ ліҖнҷҳмқ„ нҷңмҡ©н•ң мӢ нҳё ліҖнҳ•
лқјл§Ң 분кҙ‘ лҚ°мқҙн„°к°Җ к· л“ұн•ң к°„кІ©мқҳ мқёлҚұмҠӨлҘј к°Җм§Җл©° кёёмқҙк°Җ Nмқё мқјм°Ёмӣҗ мӢ нҳё F[0],вҖҰ,F[N-1]мҷҖ к°ҷмқҙ мЈјм–ҙ진 кІҪмҡ°, лқјл§Ң 분кҙ‘мңјлЎңл¶Җн„° мӨ‘мҡ”м№ҳ м•ҠмқҖ мӢ нҳёлҘј н•„н„°л§Ғн•ҙ ліҖнҷҳмқ„ к°Җн•ңлӢӨ. мқҙлҘј мң„н•ҙ кё°м Җ 분н•ҙ л°©мӢқмқё мқҙмӮ° н‘ёлҰ¬м—җ ліҖнҷҳкіј мқҙмӮ° мӣЁмқҙлё”лҰҝ ліҖнҷҳмқ„ нҷңмҡ©н•ҳлҠ” ліҖнҷҳ 2к°Җм§ҖлҘј м ңм•Ҳн•ңлӢӨ. лҚ”л¶Ҳм–ҙ л¬ҙмһ‘мң„м„ұмңјлЎң лқјл§Ң 분кҙ‘мқҳ н”јнҒ¬лҘј ліҖнҷҳн•ҳлҠ” ліҖнҷҳ 2к°Җм§ҖлҘј м ңм•Ҳн•ңлӢӨ.
3.2.1 мқҙмӮ° н‘ёлҰ¬м—җ ліҖнҷҳ
мқҙмӮ° н‘ёлҰ¬м—җ ліҖнҷҳмқҖ мЈјм–ҙ진 мӢ нҳёлЎңл¶Җн„° нҠ№м • мЈјнҢҢмҲҳм—җ н•ҙлӢ№лҗҳлҠ” л…ёмқҙмҰҲлҘј м ңкұ°н•ҳлҠ” лҚ°м—җ нҷңмҡ©лҗңлӢӨ. ліё л…јл¬ём—җм„ңлҠ” м—¬кё°м—җ кё°л°ҳмқ„ л‘җм–ҙ нҒ° мЈјкё°л§Ңмқ„ мӮ¬мҡ©н•ҙ мЈјм–ҙ진 мӢ нҳёмқҳ н”јнҒ¬мқҳ 추세лҘј мң м§Җн•ҳл©ҙм„ң ліҖнҷ”лҘј к°Җн• м•Ңкі лҰ¬мҰҳмқ„ м ңм•Ҳн•ңлӢӨ. мһ…л Ҙ мӢ нҳём—җ лҢҖн•ҙ н‘ёлҰ¬м—җ ліҖнҷҳмқҖ лӢӨмқҢкіј к°ҷмқҙ мЈјм–ҙ진лӢӨ.
мқҙл•Ң м—ӯліҖнҷҳмқҖ лӢӨмқҢкіј к°ҷмқҙ лӮҳнғҖлӮј мҲҳ мһҲлӢӨ.
м—¬кё°м„ң мқјл¶Җ Kк°ңмқҳ н•ӯл§Ңмқ„ мқҙмҡ©н•ҙ м—ӯліҖнҷҳн•ҳм—¬ н”јнҒ¬мқҳ м •ліҙлҘј мң м§ҖмӢңнӮӨл©° мһ…л Ҙ мӢ нҳёлҘј ліҖнҷҳн•ҳкі мһҗ н•ңлӢӨ. мһ…л Ҙ мӢ нҳёк°Җ мӢӨмҲҳлқјл©ҙ лӘЁл“ k м—җ лҢҖн•ҙ f [ k ] = f [ N вҲ’ k ] ВҜ
мЈјкё°к°Җ нҒ° мқјл¶Җл§ҢмңјлЎң мӢ нҳёлҘј ліөмӣҗн•ҳкІҢ лҗҳл©ҙ мӣҗліём—җм„ң н”јнҒ¬к°Җ м—Ҷкұ°лӮҳ мғҒлҢҖм ҒмңјлЎң лӮ®мқҖ н”јнҒ¬к°Җ мһҲлҠ” мң„м№ҳм—җм„ңлҠ” кіјлҸ„н•ң 진лҸҷмқҙ л°ңмғқн•ңлӢӨ. мқҙлЎңл¶Җн„° мғҲлЎңмҡҙ н”јнҒ¬к°Җ л§Ңл“Өм–ҙм§ҖлҠ” мқјмқ„ л§үкё° мң„н•ҙ мһ„кі„к°’ нҢҢлқјлҜён„° ОёлҘј мӮ¬мҡ©н•ҙ к·ёліҙлӢӨ нҒ° к°’л§Ң ліҖнҷҳн•ңлӢӨ.
3.2.2 мқҙмӮ° мӣЁмқҙлё”лҰҝ ліҖнҷҳ
мқҙмӮ° мӣЁмқҙлё”лҰҝ ліҖнҷҳмқҖ мӣЁмқҙлё”лҰҝ мЎұмқҳ кё°м ҖлЎң 분н•ҙн•ҳлҠ” ліҖнҷҳмқҙлӢӨ. мқҙлҘј мӢ нҳёмқҳ н”јнҒ¬мқҳ 추세лҘј мң м§Җн•ҳлҠ” ліҖнҷҳмңјлЎң нҷңмҡ©н•ңлӢӨ. мқҙмӮ° мӣЁмқҙлё”лҰҝ ліҖнҷҳкіј м—ӯ мқҙмӮ° мӣЁмқҙлё”лҰҝ ліҖнҷҳмқҖ [21]м—җ, мқҙлҘј нҷңмҡ©н•ң л””л…ёмқҙ징мқҖ [22]м—җ мһҗм„ёнһҲ м •лҰ¬лҗҳм–ҙ мһҲлӢӨ. мһ…л Ҙ мӢ нҳём—җ мӣЁмқҙлё”лҰҝ мЎұ wлЎң L л ҲлІЁл§ҢнҒј мқҙмӮ° мӣЁмқҙлё”лҰҝ ліҖнҷҳмқ„ м Ғмҡ©н•ҳл©ҙ к·јмӮ¬кі„мҲҳ aLкіј л””н…Ңмқј кі„мҲҳ d1,вҖҰ,dLмқ„ м–»лҠ”лӢӨ. м—¬кё°м„ң л””н…Ңмқј кі„мҲҳмқҳ к°’л§Ңмқ„ л°”кҫём–ҙ н”јнҒ¬ м •ліҙлҘј мң м§Җн•ң мұ„лЎң мӢ нҳём—җ ліҖнҳ•мқ„ к°Җн•ңлӢӨ. dLлЎң л…ёмқҙмҰҲ мһ„кі„к°’мқ„ м¶”м •н•ҳкі мқҙлЎңл¶Җн„° л””н…Ңмқј кі„мҲҳл“Өмқ„ d ^ 1 , . . . d ^ L d ^ 1 , . . . d ^ L F ^ D W T
3.2.3 лһңлҚӨ мҙҲмқҙмҠӨмҷҖ лһңлҚӨ мҠӨмјҖмқјл§Ғ
м•һм„ң м ңм•Ҳн•ң л‘җ ліҖнҷҳмқ„ мӮ¬мҡ©н•ңлӢӨл©ҙ, к°Ғ н”јнҒ¬мқҳ мғҒлҢҖм Ғ лҶ’лӮ®мқҙмҷҖ нҸӯм—җ ліҖнҷ”к°Җ мһ‘лӢӨлҠ” м җмқҙ н•ңкі„к°Җ лҗңлӢӨ. лҳҗн•ң л‘җ ліҖнҷҳ лӘЁл‘җ ОёліҙлӢӨ мһ‘мқҖ л¶Җ분м—җлҠ” м „нҳҖ ліҖнҷ”к°Җ мқјм–ҙлӮҳм§Җ м•ҠлҠ”лӢӨ. к·ёлҹ¬лҜҖлЎң мқҙлҹ¬н•ң л¬ём ңм җмқ„ н•ҙкІ°н•Ёкіј лҸҷмӢңм—җ мғқм„ұн•ҳлҠ” лҚ°мқҙн„°м—җ л¬ҙмһ‘мң„м„ұмқ„ лҚ”н•ҳкё° мң„н•ҙ лһңлҚӨ мҙҲмқҙмҠӨмҷҖ лһңлҚӨ мҠӨмјҖмқјл§Ғ л°©лІ•мқ„ м ңм•Ҳн•ңлӢӨ.
лһңлҚӨ мҙҲмқҙмҠӨ м•Ңкі лҰ¬мҰҳмқҖ мһ…л Ҙ мӢ нҳёмқҳ мқёлҚұмҠӨлҘј лһңлҚӨмңјлЎң м„ нғқлҗң мғҲлЎңмҡҙ мқёлҚұмҠӨлҘј лҢҖмІҙн•ңлӢӨ. мһ…л Ҙ мӢ нҳёмқҳ мқёлҚұмҠӨ 0,вҖҰ,N-1лҘј к· л“ұн•ҳм§Җ м•ҠмқҖ к°„кІ©мқҳ мӢӨмҲҳ мқёлҚұмҠӨ I0,вҖҰ,IN-1лЎң лҢҖмІҙн• кІғмқҙлӢӨ. 0м—җм„ң N-1мӮ¬мқҙмқҳ мһ„мқҳмқҳ мӢӨмҲҳлҘј Nк°ң мғҳн”Ңл§Ғн•ҙ лӘЁм•„л‘” 집합мқ„ Xлқј н•ҳмһҗ. мқҙл•Ң мғҳн”Ңл§Ғлҗң м җл“Өмқҙ нҠ№м • кө¬к°„м—җ лӘ°лҰ¬лҠ” кІғмқ„ л°©м§Җн•ҳкё° мң„н•ҙ м „мІҙ мқёлҚұмҠӨлҘј м ҒлӢ№нһҲ л¶„н• н•ҳкі , л¶„н• лҗң кө¬к°„лі„лЎң к· л“ұ분нҸ¬лҘј мқҙмҡ©н•ҙ мғҳн”Ңл§Ғн•ңлӢӨ. Inмқ„ Xм—җм„ң n + 1лІҲм§ёлЎң мһ‘мқҖ мӣҗмҶҢлЎң л‘җмһҗ. мқҙлҘј мқҙмҡ©н•ҙ лһңлҚӨ мҙҲмқҙмҠӨ ліҖнҷҳмқ„ м •мқҳн•ңлӢӨ.
InмқҖ мӢӨмҲҳк°’мқ„ к°Җм§ҖлҜҖлЎң мӢӨмҲҳ мқёлҚұмҠӨм—җ лҢҖн•ң мӢ нҳёмқҳ кі„мӮ°мқҙ н•„мҡ”н•ңлҚ°, мқҙлҘј мң„н•ҙ м„ нҳ• ліҙк°„мқ„ мқҙмҡ©н•ңлӢӨ.
лһңлҚӨ мҠӨмјҖмқјл§Ғ м•Ңкі лҰ¬мҰҳмқҖ к°Ғ н”јнҒ¬мқҳ лҶ’лӮ®мқҙлҘј мһ„мқҳлЎң ліҖнҳ•н•ңлӢӨ. мҠӨмјҖмқјл§Ғ нҺҷн„° S[n]лҘј лӢӨмқҢкіј к°ҷмқҙ м •мқҳн•ңлӢӨ. Оі = {x1,вҖҰ,xk}к°Җ мһ…л Ҙ мӢ нҳёмқҳ н”јнҒ¬л“Өмқҳ 집합мқҙлқј н•ҳмһҗ. nвҲҲОімқё кІҪмҡ°,
мҷҖ к°ҷмқҙ мғҳн”Ңл§Ғн•ҙ кІ°м •н•ҳл©°, nвҲүОімқё кІҪмҡ°S[n]мқҖ м„ нҳ• ліҙк°„мқ„ мқҙмҡ©н•ҙ кі„мӮ°н•ңлӢӨ. мқҙлЎңл¶Җн„° лһңлҚӨ мҠӨмјҖмқјл§Ғ ліҖнҷҳмқ„ лӢӨмқҢкіј к°ҷмқҙ м •мқҳн•ңлӢӨ.
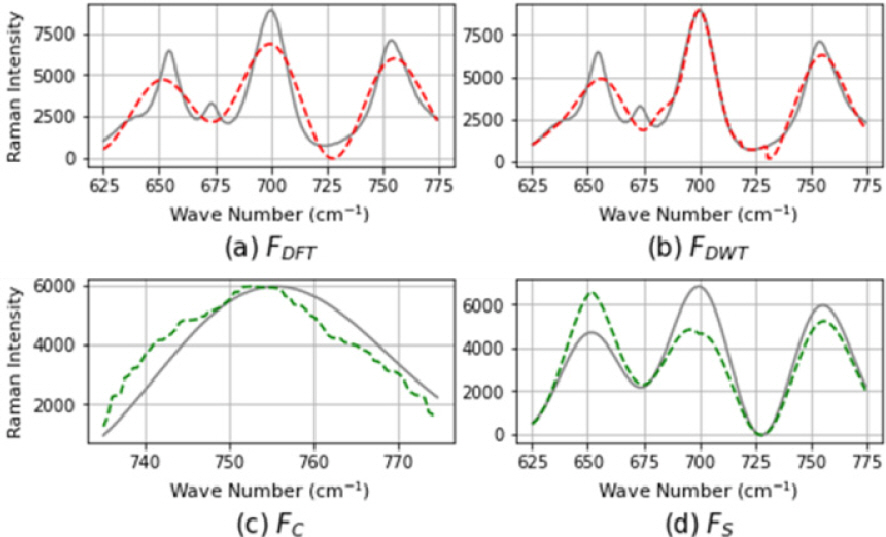
Fig. 2м—җ мқҙлІҲ м Ҳм—җм„ң м ңм•Ҳлҗң мҲҳн•ҷм Ғ ліҖнҷҳл“Өмқҙ мЈјм–ҙ진 мӢ нҳёлҘј м–ҙл–»кІҢ ліҖнҷҳн•ҳлҠ”м§Җ к·ёлҰјмңјлЎң н‘ңнҳ„лҗҳм–ҙ мһҲлӢӨ. нҡҢмғүм„ мқҙ ліҖнҷҳ м „мқҳ мӢ нҳё, м җм„ мқҖ ліҖнҷҳ нӣ„мқҳ мӢ нҳёмқҙлӢӨ. (1)мқҖ мЈјм–ҙ진 мӢ нҳёлҘј мЈјкё°к°Җ нҒ° н•ЁмҲҳл§ҢмңјлЎң н‘ңнҳ„н•ҳкё° л•Ңл¬ём—җ к°Ғ н”јнҒ¬лҘј к°Җм§ҖлҠ” кіім—җм„ң н”јнҒ¬мқҳ лӘЁм–‘мқ„ лҚ”мҡұ мҷ„л§Ңн•ң нҳ•нғңлЎң ліҖнҳ•мӢңнӮӨкі , (2)лҠ” мӮ¬мҡ©лҗҳлҠ” мӣЁмқҙлё”лҰҝ wмқҳ н•„н„° лӘЁм–‘м—җ л”°лқјм„ң н”јнҒ¬мқҳ лӘЁм–‘мқ„ ліҖнҷ”мӢңнӮЁлӢӨ. (3)мқҖ к°Ғ н”јнҒ¬мқҳ нҸӯкіј мғҒмҠ№, н•ҳлқҪн•ҳлҠ” лӘЁм–‘мқ„ ліҖнҳ•н•ҳкі , (4)лҠ” н”јнҒ¬лі„ лҶ’лӮ®мқҙлҘј мһ„мқҳлЎң лҠҳлҰ¬кұ°лӮҳ мӨ„мқёлӢӨ.
3.3 мғқм„ұ лӘЁлҚёмқ„ нҷңмҡ©н•ң лӘЁмқҳ 분кҙ‘ мғқм„ұ
лҚ”мҡұ лӢӨм–‘н•ң лӘЁмқҳ мӢ нҳёлҘј мғқм„ұн•ҳкё° мң„н•ҙ л”Ҙлҹ¬лӢқ кё°л°ҳмқҳ мғқм„ұ лӘЁлҚёмқ„ н•ҷмҠөмӢңмј°лӢӨ. лҚ°мқҙн„°мқҳ кёёмқҙ Nмқ„ 2200мңјлЎң мӮ¬мҡ©н•ҳл©ҙ лӘЁлҚё н•ҷмҠөмқҳ м•Ҳм •м„ұмқҙ л–Ём–ҙм ё м„ нҳ• ліҙк°„мқ„ мқҙмҡ©н•ҙ к·ёліҙлӢӨ мһ‘мқҖ к°’мқё 256мңјлЎң мЎ°м •н•ҙ мӮ¬мҡ©н•ҳмҳҖлӢӨ.
3.3.1 ліҖ분м Ғ мҳӨнҶ мқёмҪ”лҚ”
мҲҳн•ҷм Ғ ліҖнҷҳмңјлЎң мғқм„ұлҗң лҚ°мқҙн„°мқҳ ліөмһЎн•ң нҢЁн„ҙмқ„ мһ мһ¬ліҖмҲҳлЎң мқёмҪ”л”©н•ҳкі нҡЁкіјм ҒмңјлЎң л””мҪ”л”©н•ҙ ліөмӣҗн•ҳлҠ” мҳӨнҶ мқёмҪ”лҚ”лҘј н•ҷмҠөмӢңнӮӨкі мһҗ н•ңлӢӨ. лӢӨмқҢкіј к°ҷмқҙ ліөмӣҗ мҶҗмӢӨкіј м •к·ңнҷ” мҶҗмӢӨм—җ лҢҖн•ң н•ӯмңјлЎң кө¬м„ұлҗң мҶҗмӢӨн•ЁмҲҳлҘј мӮ¬мҡ©н•ңлӢӨ.
л””мҪ”лҚ”лҠ” Fig. 3кіј к°ҷмқҖ кө¬мЎ°мқҳ н•©м„ұкіұ лё”лЎқ(CB; Convolutional Block)мқ„ нҷңмҡ©н•ҳкі , л‘җ лІҲмқҳ мқјм°Ёмӣҗ н•©м„ұкіұкіј л°°м№ҳм •к·ңнҷ”(BN; Batch Normalization), м„ нҳ• м—…мғҷн”Ңл§ҒмңјлЎң кө¬м„ұлҗңлӢӨ. CмҷҖ LмқҖ к°Ғк°Ғ мһ…л Ҙ мұ„л„җмқҳ к°ңмҲҳмҷҖ кёёмқҙмқҙлӢӨ.
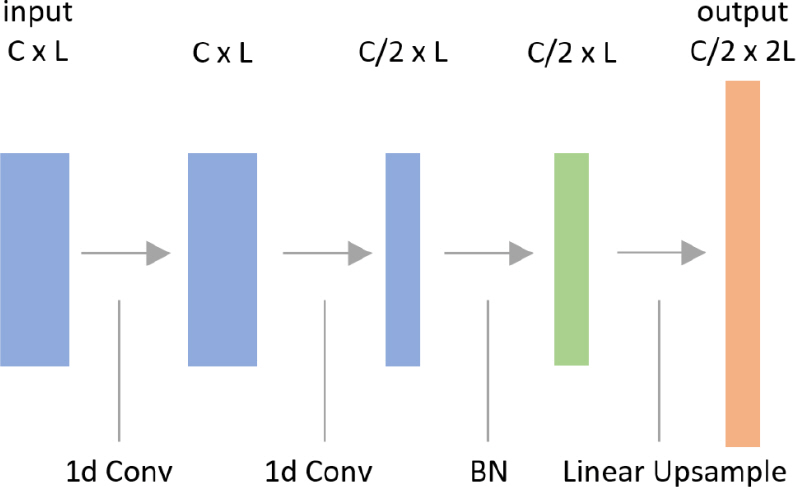
ліҖ분м Ғ мҳӨнҶ мқёмҪ”лҚ”мқҳ н•ҷмҠөм—җ мӮ¬мҡ©н• мқёмҪ”лҚ”мҷҖ л””мҪ”лҚ”мқҳ кө¬мЎ°лҠ” Table 1м—җ м •лҰ¬лҗҳм–ҙ мһҲлӢӨ. к°Ғ н–үмқҙ н•ҳлӮҳмқҳ кі„мёөм—җ лҢҖмқ‘лҗңлӢӨ. мқјм°Ёмӣҗ м»ЁліјлЈЁм…ҳ(C1d; 1d Convolution)мқҳ нҢҢлқјлҜён„°лҠ” мҲңм„ңлҢҖлЎң н•„н„°мқҳ к°ңмҲҳ, м»Өл„җ кёёмқҙ, мҠӨнҠёлқјмқҙл“ңлҘј мқҳлҜён•ңлӢӨ. мҷ„м „м—°кІ°(FC; Fully Connected) кі„мёөмқҳ нҢҢлқјлҜён„°лҠ” л…ёл“ңмқҳ к°ңмҲҳлӢӨ. н•©м„ұкіұ лё”лЎқмқҳ нҢҢлқјлҜён„°лҠ” мҲңм„ңлҢҖлЎң м¶ңл Ҙ мұ„л„җмқҳ к°ңмҲҳмҷҖ лӘЁл“ мқјм°Ёмӣҗ м»ЁліјлЈЁм…ҳмқҳ м»Өл„җ кёёмқҙлӢӨ. л°°м№ҳ м •к·ңнҷ”лҠ” лӘЁл‘җ н•ҙлӢ№ кі„мёө нҷңм„ұнҷ” н•ЁмҲҳ мқҙм „м—җ м Ғмҡ©лҗңлӢӨ. лӘЁл“ нҷңм„ұнҷ” н•ЁмҲҳлЎң мқҢмҲҳл¶Җ분м—җ 0.2к°Җ кіұн•ҙ진 Leaky ReLUлҘј, л””мҪ”лҚ”мқҳ мөңмў… мёөм—җл§Ң мӢңк·ёлӘЁмқҙл“ңлҘј мӮ¬мҡ©н–ҲлӢӨ.
3.3.2 м ҒлҢҖм Ғ мғқм„ұ мӢ кІҪл§қ
лӢӨмқҢмңјлЎң мғқм„ұ лӘЁлҚёлЎңмҚЁ к°ҖмһҘ нҷңл°ңнһҲ м—°кө¬лҗҳлҠ” GAN мқ„ нҷңмҡ©н•ҙ лӘЁмқҳ мӢ нҳёлҘј мғқм„ұн•ҳмҳҖлӢӨ. GANмқҖ мӢӨм ң лҚ°мқҙн„°мҷҖ мң мӮ¬н•ң мғҳн”Ңмқ„ мғқм„ұн•ҳлҠ” мғқм„ұмһҗлҘј н•ҷмҠөн•ҳкё° мң„н•ң лӘЁлҚёлЎң мғқм„ұмһҗмҷҖ нҢҗлі„мһҗмқҳ мөңлҢҖмөңмҶҢкІҢмһ„мңјлЎң н•ҷмҠөлҗңлӢӨ. ліё л…јл¬ём—җм„ңлҠ” GANмқҳ н•ҷмҠөм—җлҠ” мөңлҢҖмөңмҶҢкІҢмһ„мқҳ мҲҳл ҙмқ„ лҸ•лҠ” Wasserstein GANм—җ кё°мҡёкё° нҢЁл„җнӢ°лҘј мЈјлҠ” мҶҗмӢӨн•ЁмҲҳ[23]лҘј мӮ¬мҡ©н•ҳмҳҖлӢӨ.
мӢӨм ңм Ғмқё лӘЁмқҳ мӢ нҳёмқҳ мғқм„ұмқ„ мң„н•ҙ GANмқҳ мғқм„ұмһҗмқҳ мҙҲк№ғк°’мңјлЎң мӮ¬м „н•ҷмҠөлҗң VAEмқҳ л””мҪ”лҚ”лҘј мӮ¬мҡ©н•ңлӢӨ. нҢҗлі„мһҗмқҳ кө¬мЎ°лҠ” мөңмў… мёөл§Ң м ңмҷён•ҳкі лҠ” Table 1мқҳ мқёмҪ”лҚ” кө¬мЎ°мҷҖ к°ҷкі , мөңмў… мёөмқҖ н•ҳлӮҳмқҳ л…ёл“ңм—җ мӢңк·ёлӘЁмқҙл“ң н•ЁмҲҳк°Җ нҷңм„ұнҷ” н•ЁмҲҳлЎң мӮ¬мҡ©лҗңлӢӨ.
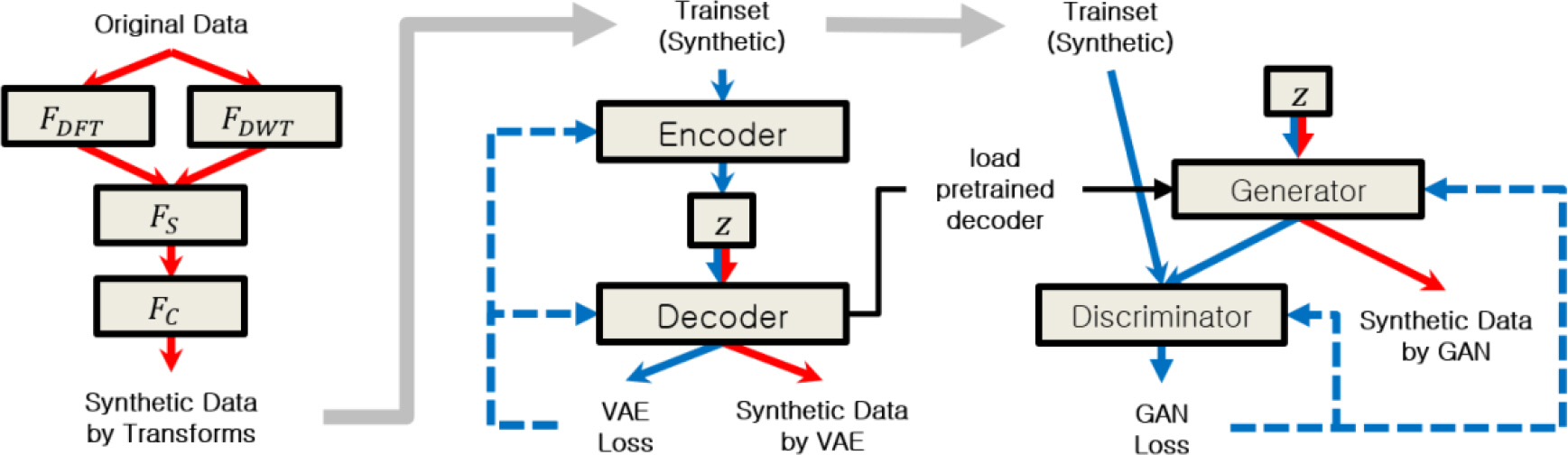
м ңм•Ҳн•ң л°©лІ•л“ӨлЎң лӘЁмқҳ мӢ нҳёлҘј мғқм„ұн•ҳлҠ” кіјм •мқҙ Fig. 4м—җ н‘ңнҳ„лҗҳм–ҙ мһҲлӢӨ. л¶үмқҖ нҷ”мӮҙн‘ңк°Җ мғқм„ұ кіјм •, н‘ёлҘё нҷ”мӮҙн‘ңк°Җ н•ҷмҠө кіјм •мқ„ мқҳлҜён•ңлӢӨ. лЁјм Җ мӣҗліё мӢ нҳёлҘј к°Ғк°Ғ (1)кіј (2)лҘј мқҙмҡ©н•ҙ ліҖнҷҳн•ң нӣ„ мҲңм°Ём ҒмңјлЎң (3)кіј (4)лЎң ліҖнҷҳн•ҙмӨҖлӢӨ. к·ё кІ°кіјлЎң мҲҳн•ҷм Ғ ліҖнҷҳмңјлЎң мғқм„ұлҗң лӘЁмқҳ лҚ°мқҙн„°лҘј м–»лҠ”лӢӨ. к·ё нӣ„ н•ҙлӢ№ лӘЁмқҳ лҚ°мқҙн„°лҘј мқҙмҡ©н•ҙ (5)лҘј мқҙмҡ©н•ҙ VAEлҘј н•ҷмҠөн•ңлӢӨ. лӮҳм•„к°Җ н•ҷмҠөлҗң VAE мқҳ л””мҪ”лҚ”лҘј мӮ¬м „н•ҷмҠөлҗң мғқм„ұмһҗлЎң мҙҲкё°нҷ”н•ҳм—¬ (6)мқ„ мқҙмҡ©н•ҙ GANмқ„ н•ҷмҠөн•ңлӢӨ. н•ҷмҠөлҗң VAEмҷҖ GANмңјлЎң кё°кі„н•ҷмҠөмңјлЎң мғқм„ұлҗң лӘЁмқҳ лҚ°мқҙн„°лҘј м–»лҠ”лӢӨ.
4. мӢӨн—ҳ кІ°кіј
3мһҘм—җм„ң м ңм•Ҳн•ң л°©лІ•л“ӨлЎң мЈјм–ҙ진 DMMPмҷҖ 2-CEES мқҳ лӘЁмқҳ лқјл§Ң 분кҙ‘ лҚ°мқҙн„°лҘј м§Ғм ‘ мғқм„ұн•ҳкі , к·ё кІ°кіјлҘј 분м„қн•ҳкі мһҗ н•ңлӢӨ.
4.1 мҲҳн•ҷм Ғ ліҖнҷҳмқҳ нҢҢлқјлҜён„°
мҲҳн•ҷм Ғ ліҖнҷҳм—җ н•„мҡ”н•ң нҢҢлқјлҜён„°л“ӨмқҖ л¬јм§Ҳлі„ лӘ…нҷ•н•ң м°ЁмқҙлҘј мң м§Җн•ҳл©ҙм„ң лӢӨм–‘м„ұмқ„ нҷ•ліҙн•ҳкё° мң„н•ң к°’л“ӨлЎң ліё м—°кө¬м—җм„ңлҠ” мһ„мқҳлЎң м§Җм •н–ҲлӢӨ. FDFTмқҳ KмҷҖ FDWTмқҳ LмқҖ Fig. 5м—җм„ң лӮҳнғҖлӮң л°”мҷҖ к°ҷмқҙ нҠ№м • к°’к№Ңм§ҖлҠ” мӣҗліёкіјмқҳ нҸүк· м ҲлҢҖ нҺём°Ёк°Җ мһ‘мқҖ к°’мңјлЎң мң м§ҖлҗҳлӢӨк°Җ кёүкІ©нһҲ мҰқк°Җн•ҳлҠ” 추세лҘј ліҙмқҙкё° л•Ңл¬ём—җ, ліҖнҷ”мңЁмқҙ к°ҖмһҘ м»Өм§ҖлҠ” мң„м№ҳм—җм„ң к°’мқ„ нғқн–ҲлӢӨ. KлҠ” Table 2мқҳ к°’мқ„, LмқҖ 5лҘј мӮ¬мҡ©н•ңлӢӨ. мӣЁмқҙлё”лҰҝ wлҠ” кІ°м •лҗң L к°’м—җ лҢҖн•ҙ 분н•ҙк°Җ к°ҖлҠҘн•ң н•„н„° мӨ‘м—җм„ң Table 2кіј к°ҷмқҙ лӢӨм–‘н•ҳкІҢ м„ нғқн–ҲлӢӨ. лҳҗн•ң FDFTмҷҖ FDWTмқҳ мһ„кі„м№ҳ ОёлҠ” к°Ғ мӣҗліё мӢ нҳём—җ лҢҖн•ң мөңлҢҖк°’кіј мөңмҶҢк°’мқҳ м°Ёмқҳ 5 %к°Җ лҗҳлҸ„лЎқ кІ°м •н–Ҳкі , FDWTмқҳ л””н…Ңмқј кі„мҲҳ мһ„кі„к°’ м¶”м •м—җлҠ” м „м—ӯ мһ„кі„к°’мқ„ мӮ¬мҡ©н–ҲлӢӨ. FSмқҳ Оұ, ОІлҠ” к°Ғ л¬јм§Ҳмқҙ нҷ•мӢӨн•ҳкІҢ кө¬л¶„лҗҳлҠ” к°’мңјлЎң к°Ғк°Ғ 0.8, 1.2лЎң нғқн–Ҳмңјл©°, FCмқҳ л¶„н• лЎң 100 cm-1 к°„кІ©мқҳ к· л“ұл¶„н• мқ„ мӮ¬мҡ©н–ҲлӢӨ.

4.2 мҲҳн•ҷм Ғ ліҖнҷҳмқ„ мқҙмҡ©н•ң лҚ°мқҙн„° мғқм„ұ
мҡ°м„ мҲҳн•ҷм Ғ ліҖнҷҳмқ„ нҶөн•ҙ лҚ°мқҙн„°лҘј мғқм„ұн•ҳкі кІ°кіјлҘј 분м„қн•ңлӢӨ. VAEмҷҖ GAN н•ҷмҠөм—җ мқјм •н•ң лІ”мң„мқҳ лҚ°мқҙн„°лҘј мӮ¬мҡ©н•ҳкё° мң„н•ҙ мғқм„ұлҗң лҚ°мқҙн„°м—җлҠ” 0кіј 1мӮ¬мқҙмқҳ к°’мңјлЎң мөңлҢҖмөңмҶҢ мҠӨмјҖмқјл§Ғмқ„ м Ғмҡ©н–ҲлӢӨ. Fig. 6мқҖ мғқм„ұлҗң лӘЁмқҳ лҚ°мқҙн„°мҷҖ к·ёкІғмқҳ нҸүк· (진н•ң м„ )кіј мөңмҶҹк°’, мөңлҢ“к°’мқҳ лІ”мң„(м—°н•ң лІ”мң„)лҘј н‘ңнҳ„н•ң кІғмқҙлӢӨ. лӘЁмқҳ лҚ°мқҙн„°к°Җ мқҙмғҒм№ҳ м—Ҷмқҙ нҠёлһңл“ңлҘј л”°лқјк°Җл©ҙм„ңлҸ„ ліҖлҸҷнҸӯмқ„ к°Җ진лӢӨ. лҚ”л¶Ҳм–ҙ н”јнҒ¬к°Җ мһҲлҠ” л¶Җ분м—җм„ңмқҳ ліҖлҸҷнҸӯмқҙ н”јнҒ¬к°Җ м—ҶлҠ” кіім—җ 비н•ҙ лҚ” нҒ°лҚ°, мқҙлҠ” н”јнҒ¬м—җ лӢӨм–‘н•ң ліҖнҳ•мқ„ к°Җн•ҳкі мһҗ н–ҲлҚҳ мқҳлҸ„лҘј л°ҳмҳҒн•ҳлҠ” кІ°кіјлӢӨ. Fig. 1кіј 비көҗн•ҙліҙл©ҙ мғқм„ұлҗң мӢ нҳёмқҳ нҸүк· мқҙ мӣҗліё мӢ нҳёмҷҖ к°ҷмқҖ мң„м№ҳм—җм„ң н”јнҒ¬лҘј к°Җм§Җкі , мқҙлЎңл¶Җн„° лқјл§Ң 분кҙ‘мқҳ нҠ№м„ұмқҙ мң м§Җлҗҳм—ҲмқҢмқ„ нҷ•мқён• мҲҳ мһҲлӢӨ.
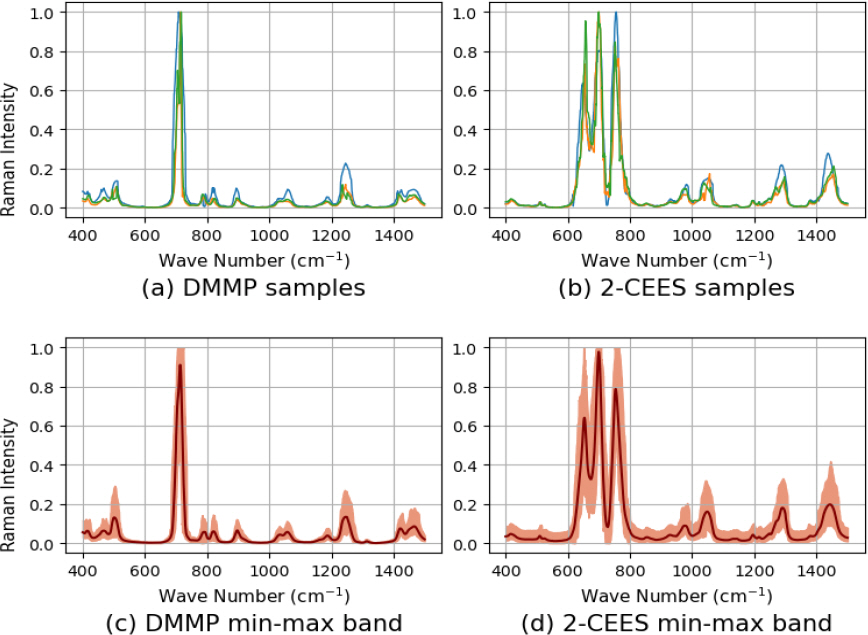
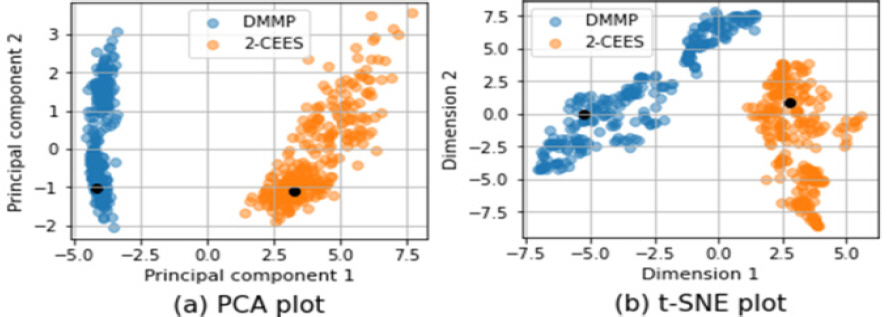
Fig. 7мқҖ ліҖнҷҳмңјлЎң мғқм„ұлҗң лҚ°мқҙн„°лҘј PCAмҷҖ t-SNEлЎң мӢңк°Ғнҷ”н•ң кІ°кіјлӢӨ. кІҖмқҖ м җмқҖ мӣҗліё лҚ°мқҙн„°лҘј мқҳлҜён•ңлӢӨ. л¬јм§Ҳлі„лЎң ліҖнҷҳмңјлЎң мғқм„ұлҗң лҚ°мқҙн„°лҠ” мӣҗліё лҚ°мқҙн„°мҷҖ 충분нһҲ к°Җк№Ңмҡҙ мң„м№ҳм—җ лӘЁм—¬ мһҲмңјл©° лӘ…нҷ•н•ҳкІҢ кө¬л¶„лҗҳл©ҙм„ңлҸ„ м ҒлӢ№н•ң 분мӮ°мқ„ к°Җм ё нқ©м–ҙм ё мһҲмқҢмқ„ нҷ•мқён• мҲҳ мһҲлӢӨ.
4.3 мғқм„ұ лӘЁлҚёмқ„ мқҙмҡ©н•ң лҚ°мқҙн„° мғқм„ұ
лӢӨмқҢмңјлЎң ліҖнҷҳмңјлЎң мғқм„ұн•ң лҚ°мқҙн„°лҘј нӣҲл Ём§‘н•©мңјлЎң мғқм„ұ лӘЁлҚёмқ„ н•ҷмҠөмӢңмјң м–»лҠ” мғҲлЎңмҡҙ лҚ°мқҙн„°лҘј нҷ•мқён•ңлӢӨ. VAEлҠ” л¬јм§Ҳлі„лЎң 0.001 н•ҷмҠөмңЁмқҳ AdamмңјлЎң 1000 м—җнҸ¬нҒ¬м”©, GANмқҖ мғқм„ұмһҗлҠ” 0.00005 нҢҗлі„мһҗлҠ” 0.0001мқҳ н•ҷмҠөмңЁлЎң RMSpropмқ„ нҷңмҡ©н•ҙ л¬јм§Ҳлі„лЎң 1000 м—җнҸ¬нҒ¬м”© н•ҷмҠөмӢңмј°лӢӨ.
Fig. 8, 9, 10м—җм„ң мҲҳн•ҷм Ғ ліҖнҷҳкіј мғқм„ұ лӘЁлҚёлЎң мғқм„ұлҗң лҚ°мқҙн„°мқҳ 분нҸ¬лҘј мғҒм„ён•ҳкІҢ 비көҗн•ҳкі мһҲлӢӨ. к°Ғ мғқм„ұ лӘЁлҚёмқҳ нӣҲл ЁлҚ°мқҙн„°мҷҖ мғқм„ұлҗң лҚ°мқҙн„°лҘј к°ҷмқҖ к°ңмҲҳл§ҢнҒј к°Җм§Җкі t-SNEлҘј мҲҳн–үн•ңлӢӨ. мқҙл•Ң, мғқм„ұлӘЁлҚёмқҙ мғқм„ұн•ң лҚ°мқҙн„°лҠ” кё°мЎҙ лҚ°мқҙн„° кёёмқҙмқё 2,200мңјлЎң м„ нҳ•ліҙк°„н•ҳм—¬ 비көҗн•ҳмҳҖлӢӨ. Fig. 8мқҖ VAEмқҳ мһ мһ¬кіөк°„м—җм„ң мғҳн”Ңл§ҒмңјлЎң мғқм„ұлҗң лҚ°мқҙн„°кіј нӣҲл ЁлҚ°мқҙн„°лҘј мӢңк°Ғнҷ”н•ң кІ°кіјлӢӨ. VAE лЎң мғқм„ұлҗң лҚ°мқҙн„°мқҳ 분нҸ¬л“Ө лӘЁл‘җ нӣҲл ЁлҚ°мқҙн„°мқҳ 분нҸ¬мҷҖ 충분нһҲ кІ№міҗм§Җкі , мқҙлҠ” VAEк°Җ нӣҲл ЁлҚ°мқҙн„°м—җ лӮҙмһ¬лҗң 분нҸ¬лҘј мһҳ лӘЁл°©н•ҳкІҢлҒ” н•ҷмҠөлҗҳм—ҲлӢӨлҠ” кІғмқ„ мқҳлҜён•ңлӢӨ.
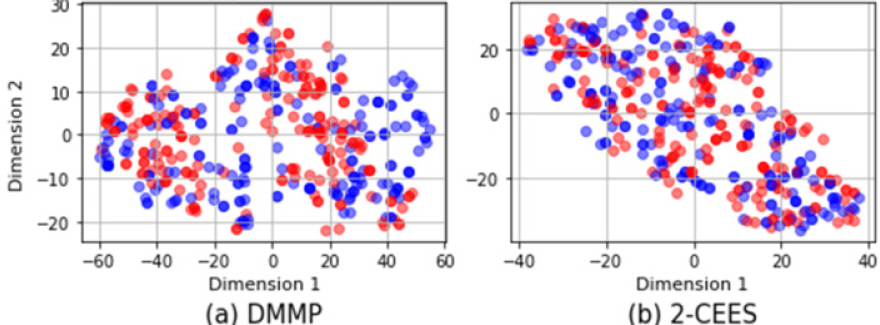

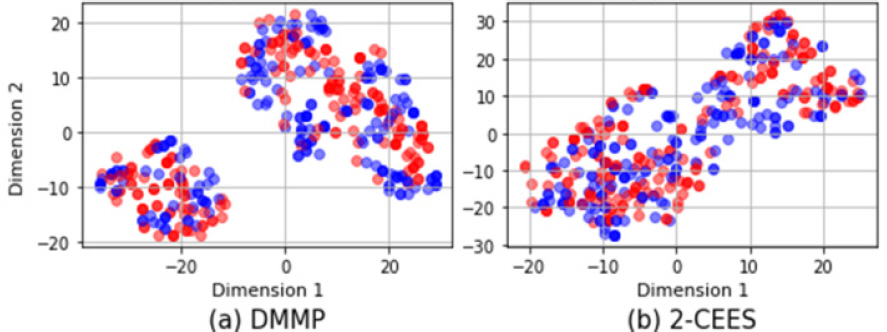
Fig. 9лҠ” н•ҷмҠөлҗң GANмқҙ мғқм„ұн•ң лҚ°мқҙн„°лҘј мӢңк°Ғнҷ”н•ң кІ°кіјлӢӨ. мӮ¬м „н•ҷмҠө м—Ҷмқҙ н•ҷмҠөмқ„ 진н–үн–Ҳмқ„ л•Ң, мғқм„ұлҗң лҚ°мқҙн„°к°Җ 충분нһҲ лӢӨм–‘н•ҳм§Җ лӘ»н•ҳл©°, к°ңм„ мқ„ мң„н•ҙ VAE мқҳ л””мҪ”лҚ”лҘј мғқм„ұмһҗмқҳ мҙҲк№ғк°’мңјлЎң мҙҲкё°нҷ”н•ҳм—¬ GANмқ„ н•ҷмҠөмӢңнӮЁ кІ°кіј, мҲҳн•ҷм Ғ ліҖнҷҳ лҚ°мқҙн„°мҷҖ 충분нһҲ мң мӮ¬н•ҳл©° лӢӨм–‘н•ң лҚ°мқҙн„°к°Җ мғқм„ұлҗҳм—ҲлӢӨ.
Fig. 10м—җлҠ” мөңмў…м ҒмңјлЎң GANмқҙ мғқм„ұн•ң лӘЁмқҳ лҚ°мқҙн„°мҷҖ нӣҲл ЁлҚ°мқҙн„°мқҳ t-SNE мӢңк°Ғнҷ”к°Җ лӮҳнғҖлӮҳ мһҲлӢӨ. Fig. 8кіј 비көҗн•ҙліҙм•ҳмқ„ л•ҢлҸ„ GANмқҙ мғқм„ұн•ң лҚ°мқҙн„°мқҳ 분нҸ¬к°Җ нӣҲл ЁлҚ°мқҙн„°мқҳ 분нҸ¬мҷҖ лҚ”мҡұ мһҳ кІ№міҗм§ҖлҠ” кІғмқ„ нҷ•мқён• мҲҳ мһҲлӢӨ. л§Ҳм°¬к°Җм§ҖлЎң GANмқҙ нӣҲл ЁлҚ°мқҙн„°лҘј мһҳ лӘЁл°©н•ңлӢӨлҠ” кІғмқ„ м•Ң мҲҳ мһҲлӢӨ.
мғқм„ұлҗң лҚ°мқҙн„°мҷҖ мӣҗліёкіјмқҳ м°ЁмқҙлЎң к°Ғ л°©лІ•мңјлЎң мғқм„ұн•ң лҚ°мқҙн„°л“Өмқҳ 분нҸ¬к°Җ мң мӮ¬н•ңм§Җ м•Ңм•„ліј кІғмқҙлӢӨ. Table 3мқҖ к°Ғ л°©лІ•мңјлЎң мғқм„ұлҗң лҚ°мқҙн„°мҷҖ мӣҗліё лҚ°мқҙн„° мӮ¬мқҙмқҳ мғҒкҙҖкі„мҲҳ лӮҳнғҖлӮё н‘ңмқҙлӢӨ. н‘ңмқҳ к°’мқ„ нҶөн•ҙ мғқм„ұлҗң лӘЁмқҳлҚ°мқҙн„°к°Җ мӣҗліёкіј лҶ’мқҖ мғҒкҙҖлҸ„лҘј к°Җм§ҖлҸ„лЎқ мғқм„ұлҗҳм—ҲмқҢмқ„ нҷ•мқён• мҲҳ мһҲлӢӨ.
кІ° лЎ
ліё л…јл¬ёмқҖ м ҒмқҖ мҲҳмқҳ лҚ°мқҙн„°л§Ңмқ„ к°Җм§Җкі к·ёмҷҖ мң мӮ¬н•ң лӘЁмқҳ лқјл§Ң 분кҙ‘мқ„ мғқм„ұн•ҳлҠ” м•Ңкі лҰ¬мҰҳмқ„ м ңм•Ҳн•ҳкі , мқҙлҘј нҶөн•ҙ м–ҙл–Ө л¬јм§Ҳмқҳ лқјл§Ң 분кҙ‘мқҙ мЈјм–ҙм§Җл©ҙ мҲҳн•ҷм Ғ ліҖнҷҳкіј мғқм„ұлӘЁлҚёмқҳ н•ҷмҠөмқ„ кұ°міҗ лӘЁмқҳ лқјл§Ң 분кҙ‘ лҚ°мқҙн„°м…Ӣмқ„ кө¬м¶•н•ңлӢӨ. лҸ…м„ұ л¬јм§Ҳмқё DMMPмҷҖ 2-CEESмқҳ лқјл§Ң 분кҙ‘ лҚ°мқҙн„°лЎң лӘЁмқҳ лҚ°мқҙн„°лҘј мғқм„ұн•ң нӣ„ н•ҙлӢ№ л¬јм§Ҳм—җ лҢҖн•ң 충분н•ң нҒ¬кё°мқҳ лӘЁмқҳ лқјл§Ң 분кҙ‘ лҚ°мқҙн„°м…Ӣмқ„ кө¬м¶•н•ҳмҳҖлӢӨ. н–Ҙнӣ„ ліё м—°кө¬м—җм„ң м ңм•Ҳн•ң м•Ңкі лҰ¬мҰҳмңјлЎң мғқм„ұн•ң лӘЁмқҳ лқјл§Ң 분кҙ‘мқ„ мқҙмҡ©н•ҳм—¬ лӢӨм–‘н•ң нҷҳкІҪм—җм„ң лҸ…м„ұ л¬јм§Ҳмқ„ кІҖм¶ңн•ҳлҠ” нғҗм§Җ лӘЁлҚёмқҳ к°ңл°ңмқ„ 진н–үн• кІғмқҙлӢӨ.




