



žĄú Ž°†
4žį® žāįžóÖŪėĀŽ™ÖžĚė ž§Ďžč¨Íłįžą† ž§Ď ŪēėŽāėžĚł ŽĒ•Žü¨ŽčĚ Íłįžą†žĚī ŪēôÍ≥Ą ŽįŹ ÍįĀ žāįžóÖŽ∂Ąžēľžóź ž†Āžö©ŽźėŽ©īžĄú, ÍĶ≠Žį©Ž∂Ąžēľ ŽėźŪēú ŽĒ•Žü¨ŽčĚ Íłįžą†žĚĄ ž†Āžö©ŪēėÍ≥†žěź ŪēėŽäĒ žčúŽŹĄÍįÄ Í≥ĄžÜ掟ėÍ≥† žěąŽč§. ŪäĻŪěą, ŽĒ•Žü¨ŽčĚ ž§ĎžóźžĄúŽŹĄ žĚīŽĮłžßÄ žĚłžčĚŽ∂ĄžēľŽäĒ ÍĶ≠Žį© Í≤ĹÍ≥Ą Íįźžčú žčúžä§ŪÖú[1], ÍĶįŪē®/ŽĻĄÍĶįŪē® Ž∂ĄŽ•ė[2], ÍĶįŪē® Ūē®žĘÖ žčĚŽ≥Ą žčúžä§ŪÖú[3], žě†žąėŪē® ŽĻĄžĚĆŪĖ• ŪÉźžßÄŽ•ľ žúĄŪēú Žßąžä§Ūäł žčĚŽ≥Ą[4] ŽďĪžóź Žč§žĖĎŪēėÍ≤Ć žóįÍĶ¨ŽźėŽ©īžĄú ŽĒ•Žü¨ŽčĚ Íłįžą†žĚė ÍĶ≠Žį©Ž∂Ąžēľ ž†Ā žö©ÍįÄŽä•žĄĪžóź ŽĆÄŪēú ÍłįŽĆÄŽ•ľ ŪēúžłĶ ŽÜížĚīÍ≥† žěąŽč§.
žĚīŽĮłžßÄ žĚłžčĚžĚÄ žěÖŽ†• ŽćįžĚīŪĄįÍįÄ ž£ľžĖīž°ĆžĚĄ ŽēĆ ŪēīŽčĻ ŽćįžĚīŪĄįžĚė ŪĀīŽěėžä§Ž•ľ žėąžł°ŪēėŽäĒ Ž∂ĄŽ•ė Ž¨łž†úžĚīŽč§. žėąžł°žĚĄ Ūē† žąė žěąŽäĒ Ž™®ŽćłžĚĄ ÍĶ¨ž∂ēŪēėÍłį žúĄŪēīžĄúŽäĒ ŪõąŽ†®ŽćįžĚīŪĄįŽ°ú Ž™®ŽćłžĚĄ ŪēôžäĶžčúžľúžēľ ŪēėŽ©į, žĚīžÉĀž†ĀžúľŽ°úŽäĒ ŪõąŽ†®ŽćįžĚīŪĄįžĚė ŪĀīŽěėžä§Ž≥Ą ŽćįžĚīŪĄį žąėÍįÄ žú†žā¨Ūēėžó¨žēľ ŪēúŽč§. ŪĀīŽěėžä§Ž≥Ą žąėžĚė žį®žĚīÍįÄ ŽįúžÉĚŪēėŽäĒ ŽćįžĚīŪĄįŽ•ľ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįŽĚľÍ≥† ŪēėŽäĒŽćį[5], žĖīŽĖ†Ūēú ŽćįžĚīŪĄįžĄłŪ䳎̾ŽŹĄ ŪĀīŽěėžä§Ž≥Ą ŽćįžĚīŪĄį žąėÍįÄ ž°įÍłąžĒ©žį®žĚīŽäĒ Žā† žąė žěąžßÄŽßĆ, Ž®łžč†Žü¨ŽčĚžĚīŽāė ŽĒ•Žü¨Žč̞󟞥úžĚė Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįŽäĒ ŪĀīŽěėžä§ ÍįĄ ŽćįžĚīŪĄį žąėžĚė Ž∂ąÍ∑†ŪėēžĚī ŪėĄž†ÄŪēėÍ≤Ć ŽāėŪÉÄŽāėŽäĒ Í≤ĹžöįŽ•ľ žĚėŽĮłŪēėŽ©į[6], Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ 1:5 žĚīžÉĀžĚė Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ ÍįĞߥ Í≤ĹžöįŽ•ľ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįŽ°ú ž†ēžĚėŪēėžėÄŽč§. Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžóźžĄúŽäĒ ŽćįžĚīŪĄį ÍįĄžĚė Ž∂ĄŽ•ėÍ≤ĹÍ≥ĄžĄ†žĚī ž†Āž†ąŪēėÍ≤Ć ŪėēžĄĪŽźėžßÄ Ž™ĽŪēėÍ≥† ŽćįžĚīŪĄįÍįÄ ŽßéžĚÄ Žč§žąėŪĀīŽěėžä§žóź ŪéłŪĖ•ŽźėžĖī ŪėēžĄĪŽźėÍ≤Ć ŽźėŽ©į, žĚī Í≤Ĺžöį žÜĆžąėŪĀīŽěėžä§žóź ŽĆÄŪēú žėąžł° žĄĪŽä•žĚī ŽāģžēĄžßĄŽč§ŽäĒ Ž¨łž†úÍįÄ žěąŽč§.
ŪėĄžč§Ž¨łž†úžóźžĄúŽäĒ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžĚł Í≤ĹžöįÍįÄ Žč§žąė ž°īžě¨ŪēúŽč§. žėąŽ•ľ Žď§žĖī ž†úž°įžó֞󟞥ú Ž∂ąŽüČŪíąžĚĄ ŪĆźž†ēŪēėŽäĒ Í≤ĹžöįŽ•ľ ŽĒ•Žü¨Žč̞̥ ŪÜĶŪēī ŪēôžäĶžčúŪā®Žč§Ž©ī, ž†ēžÉĀžĚł žÉĀŪíąžĚī Ž∂ąŽüȞ̳ žÉĀŪíąŽ≥īŽč§ Ūõ®žĒ¨ ŽßéžúľŽĮÄŽ°ú Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžóź ŪēīŽčĻŪēúŽč§. žĚī Í≤Ĺžöį ž†ēžÉĀžĚł žÉĀŪíąžóź ŪéłŪĖ•ŽźėžĖī ŪēôžäĶŽźėÍ≤Ć ŽźėÍ≥† ŪēôžäĶŽźú Ž™®ŽćłžĚÄ Ž∂ąŽüȞ̳ žÉĀŪíąžóź ŽĆÄŪēú ŽāģžĚÄ žčĚŽ≥Ąžú®žĚĄ Ž≥īžĚīÍ≤Ć ŽźúŽč§. žēĒ žßĄŽč®ŽŹĄ žú†žā¨ŪēúŽćį, žĚĆžĄĪžĚł Í≤ĹžöįÍįÄ žĖĎžĄĪŽ≥īŽč§ Ūõ®žĒ¨ ŽßéžúľŽĮÄŽ°ú žĚĆžĄĪžóź ŪéłŪĖ•ŽźėžĖī ŪēôžäĶŽźėÍ≤Ć ŽźėÍ≥† Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįŽ•ľ ž†Āž†ąŪēėÍ≤Ć ž≤ėŽ¶¨ŪēėžßÄ žēäžúľŽ©ī Ž™®ŽćłžĚė žėąžł° žĄĪŽä•žĚÄ ŽāģžēĄžßÄÍ≤Ć ŽźúŽč§.
ÍĶ≠Žį©Ž∂ĄžēľžóźžĄú žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ•ľ žúĄŪēī ŽĒ•Žü¨Žč̞̥ ž†Āžö©ŪēėÍ≥†žěź ŪēėŽäĒ Ž¨łž†úžóźžĄúŽŹĄ žĚīžôÄ žú†žā¨ŪēėÍ≤Ć Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįŽ•ľ ž≤ėŽ¶¨Ūēīžēľ ŪēėŽäĒ Í≤ĹžöįÍįÄ ŽĻąŽ≤ąŪēėÍ≤Ć ŽįúžÉĚŪēúŽč§. Í≤ĹÍ≥Ą Íįźžčú žčúžä§ŪÖúžóźžĄúŽäĒ ŽĻĄžĻ®žěÖ ŽįįÍ≤ĹžĚė ŽćįžĚīŪĄįÍįÄ ÍįźžčúŪēėÍ≥†žěź ŪēėŽäĒ žĻ®žěÖžěźžĚė ŽćįžĚīŪĄįžóź ŽĆÄŽĻĄŪēī Žč§žąėžĚīŽč§. žě†žąėŪē®žĚė ŽĻĄžĚĆŪĖ• ŪÉźžßÄŽ•ľ žúĄŪēī žě†žąėŪē® Žßąžä§Ū䳎•ľ žčĚŽ≥ĄŪēėŽäĒ Ž¨łž†úžóźžĄúŽŹĄ žě†žąėŪē® Žßąžä§ŪäłžĚė žĚīŽĮłžßÄŽäĒ Žč§Ž•ł žú†žā¨ŽćįžĚīŪĄįžóź ŽĻĄŪēī ŪöćŽďĚŪēėŽäĒ Í≤ÉžĚī žĖīŽ†ĶÍłį ŽēĆŽ¨łžóź Ž∂ąÍ∑†ŪėēŪēú ŽćįžĚīŪĄįžĄłŪäłÍįÄ Žź† žąė ŽįĖžóź žóÜŽč§. ÍĶįŪē®Í≥ľ ŽĻĄÍĶįŪē®žĚĄ žčĚŽ≥ĄŪēėÍ≥†žěź ŪēėŽäĒ Ž¨łž†úŽŹĄ žú†žā¨ŪēúŽćį, ÍĶįŪē®žĚī Ūē≠ŪēīŽ•ľ žúĄŪēī TVžĻīŽ©ĒŽĚľ ŽďĪžĚė žėĀžÉĀžě•ŽĻĄŽ•ľ žěĎŽŹô ž§Ďžóź žĖĽžĚĄ žąė žěąŽäĒ ŽćįžĚīŪĄįŽäĒ ÍĶįŪē®žóź ŽĻĄŪēī ŽĻĄÍĶįŪē®žĚł žó¨ÍįĚžĄ†, žú†ž°įžĄ†, LNGžĄ†, žĖīžĄ† ŽďĪžĚė ŽćįžĚīŪĄįÍįÄ Ūõ®žĒ¨ ŽßéŽč§.
žĶúžīąŽ°ú Ž™®ŽćłžĚĄ ÍĶ¨ž∂ēŪē† ŽēĆ ŪĀīŽěėžä§Ž≥ĄŽ°ú ŽŹôžĚľŪēú žĖĎžĚė ŽćįžĚīŪĄįžĄłŪ䳎•ľ žĚłžúĄž†ĀžúľŽ°ú ÍĶ¨žĄĪŪēú ŪõĄ ŪēôžäĶŪē† žąėŽŹĄ žěąÍ≤†žßÄŽßĆ, Ž™®Žćł žĄĪŽä• ŪĖ•žÉĀžĚĄ žúĄŪēīžĄúŽäĒ ŽćįžĚīŪĄįŽ•ľ žßÄžÜ枆ĀžúľŽ°ú žąėžßĎŪēėžó¨ žóÖÍ∑łŽ†ąžĚīŽďúŪēīžēľ ŪēúŽč§. Í≤ĹÍ≥Ą Íįźžčú žčúžä§ ŪÖúžĚė TODŽāė Ūē®ž†ēžĚė TVžĻīŽ©ĒŽĚľ ŽďĪžĚĄ ŪÜĶŪēī žąėžßĎŪēú ŽćįžĚīŪĄįŽ•ľ ŪÜĶŪēī Ž™®ŽćłžĚĄ žóÖÍ∑łŽ†ąžĚīŽďúŪēúŽč§Ž©ī, žěźžóįžä§ŽüĹÍ≤Ć žĖĽžĖīžßÄŽäĒ ŽćįžĚīŪĄįŽäĒ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįÍįÄ ŽźėÍłį žČ¨žöł Í≤ÉžĚīŽč§.
žĚīžóź Ž≥ł žóįÍĶ¨ŽäĒ ÍĶ≠Žį©Ž∂ĄžēľžóźŽäĒ žĶúžīąŽ°ú žĚīŽĮłžßÄ Ž∂ĄŽ•ėžĚė Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄį Ž¨łž†úŽ•ľ ÍįúžĄ†ŪēėÍłį žúĄŪēú Žį©žēąžúľŽ°ú ŪĀīŽěėžä§žóź ŽĒįŽĚľ žĄúŽ°ú Žč§Ž•ł ŽĻĄžö©žĚĄ Ž∂Äžó¨ŪēėŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ(Cost-sensitive learning) ÍłįŽįė Ž™®ŽćłžĚĄ ž†úžčúŪēúŽč§. ÍĶ≠Žį©Ž∂ĄžēľžóźžĄúžĚė Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄį Ž¨łž†úžôÄ ÍīÄŽ†®Ūēú žóįÍĶ¨ÍįÄ ŽĮłŪĚ°Ūēú žÉĀŪô©žóźžĄú, žě†žąėŪē® Žßąžä§Ūäł žčĚŽ≥ĄžĚĄ žúĄŪēú žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįžĄłŪäłžôÄ ÍĶįŪē®/ŽĻĄÍĶįŪē® Ž∂ĄŽ•ėŽ•ľ žúĄŪēú ŽćįžĚīŪĄįžĄłŪ䳎°ú CNN(Convolutional Neural Network)žĚĄ žĚīžö©Ūēú žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ•ľ žčúŽŹĄŪē† ŽēĆ, ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė Ž™®ŽćłžĚī žĚľŽįė Ž™®ŽćłŽ≥īŽč§ žĄĪŽä•žĚī žöįžąėŪē®žĚĄ Ž≥īžėÄŽč§. 2žě•žóźžĄúŽäĒ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžĚė Ž¨łž†úž†źÍ≥ľ žĚīŽ•ľ ž≤ėŽ¶¨ŪēėÍłį žúĄŪēú Íłįžą†, žĄ†ŪĖČŽźú žú†žā¨žóįÍĶ¨žóź ŽĆÄŪēī žĄ§Ž™ÖŪēėžėÄÍ≥†, 3žě•žóźžĄúŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚĄ ÍĶ¨ž∂ēŪēú ŪõĄ žó¨Žü¨ ŽćįžĚīŪĄįžĄłŪ䳎•ľ Ūôúžö©Ūēėžó¨ žĚľŽįė Ž™®ŽćłŽď§žĚė žėąžł° žĄĪŽä•Í≥ľ ŽĻĄÍĶź žč§ŪóėžĚĄ žßĄŪĖČŪēėžėÄŽč§. 4žě•žóźžĄúŽäĒ žėąžł° žĄĪŽä•žĚė žį®žĚīÍįÄ ŪÜĶÍ≥Ąž†ĀžúľŽ°ú žú†žĚėŽĮłŪēúžßÄ Ž∂ĄžĄĚŪēėžėÄŽč§. 5žě•žóźžĄúŽäĒ žóįÍĶ¨Í≤įŽ°† ŽįŹ ž†úŪēúžā¨Ūē≠žĚĄ ž†úžčúŪēėžėÄŽč§.
Ž¨łŪóĆžóįÍĶ¨
2.1 Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžĚė Ž¨łž†úž†źÍ≥ľ ž≤ėŽ¶¨Íłįžą†
Ž®łžč†Žü¨ŽčĚžĚīŽāė ŽĒ•Žü¨Žč̞󟞥úžĚė Ž∂ĄŽ•ėŽ¨łž†úŽäĒ ŪēôžäĶŽćįžĚīŪĄįžĄłŪ䳎°úŽ∂ÄŪĄį ŪĀīŽěėžä§Ž≥ĄŽ°ú ž†Āž†ąŪēú Ž∂ĄŽ•ėÍ≤ĹÍ≥ĄžĄ†žĚĄ žįĺÍ≥†, žĚī Ž™®ŽćłŽ°ú žÉąŽ°úžöī ŽćįžĚīŪĄįžĚė ŪĀīŽěėžä§Ž•ľ žėąžł°ŪēėŽäĒ Í≤ÉžĚīŽč§. ŪĀīŽěėžä§ Ž≥Ą ŪäĻžßēžĚī Ž∂ĄŽ™ÖŪēėÍ≥† ŽćįžĚīŪĄįžĚė žąėÍįÄ Í∑†ŽďĪŪēėŽč§Ž©ī Fig. 1žóźžĄú Ž≥īŽäĒ Í≤ÉÍ≥ľ ÍįôžĚī žĚīžÉĀž†ĀžĚł Ž∂ĄŽ•ėÍ≤ĹÍ≥ĄžĄ† (Ideal classifier)žĚī ŪėēžĄĪŽźėÍ≤†žßÄŽßĆ, ŽćįžĚīŪĄįÍįÄ ŪēėŽāėžĚė ŪĀīŽěėžä§žóź Ūéłž§ĎŽźúŽč§Ž©ī Žč§žąėŪĀīŽěėžä§žóź Ūéłž§ĎŽźú žė§Ž•łž™ĹžĚė Ž∂ĄŽ•ėÍ≤ĹÍ≥ĄžĄ†žĚĄ ŪėēžĄĪŪēėÍ≤Ć ŽźúŽč§. žĚī Í≤Ĺžöį ŪėēžĄĪŽźú Ž™®ŽćłžóźžĄúŽäĒ žėąžł°ŪēėÍ≥†žěź ŪēėŽäĒ ŽćįžĚīŪĄįžĚł ŪöĆžÉČžĚė ŽćįžĚīŪĄįŽ•ľ žĚĆžĄĪ(Negative class)žúľŽ°ú žė§Ž∂ĄŽ•ėŪēėÍ≤Ć ŽźėŽäĒ Í≤ÉžĚīŽč§[7].

Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįŽ°ú žĚłŪēī ŽįúžÉĚŪēėŽäĒ Ž¨łž†úŽ•ľ Í∑ĻŽ≥ĶŪēėÍłį žúĄŪēú ÍłįŽ≤ēžĚÄ ŪĀ¨Í≤Ć ŽćįžĚīŪĄį žąėž§ÄžĚė Žį©Ž≤ēÍ≥ľ žēĆÍ≥†Ž¶¨ž¶ė žąėž§ÄžĚė Žį©Ž≤ēžĚī žěąŽč§[8]. ŽćįžĚīŪĄį žąėž§ÄžĚė Žį©Ž≤ēžĚÄ ŽćįžĚīŪĄį žąėžĚė Í∑†ŪėēžĚĄ Žßěž∂ĒžĖī ŪēôžäĶŪēėŽäĒ Žį©Ž≤ēžúľŽ°ú žÉėŪĒĆŽßĀ(Sampling)ÍłįŽ≤ēžĚī žĚīžóź ŪēīŽčĻŪēúŽč§. žÉėŪĒĆŽßĀ ÍłįŽ≤ēžĚÄ ŽćįžĚīŪĄįžĚė žąėŽ•ľ ž°įž†ąŪēėŽäĒ Žį©Ž≤ēžóź ŽĒįŽĚľ žÜĆžąėŪĀīŽěėžä§žĚė ŽćįžĚīŪĄįŽ•ľ Žč§žąėŪĀīŽěėžä§žĚė ŽćįžĚīŪĄįŽßĆŪĀľ ž¶ĚŪŹ≠žčúŪā§ŽäĒ žė§Ž≤ĄžÉėŪĒĆŽßĀ(Oversampling)Í≥ľ Žč§žąėŪĀīŽěėžä§žĚė ŽćįžĚīŪĄįŽ•ľ žÜĆžąėŪĀīŽěėžä§žóź Žßěž∂ĒžĖī ÍįźžÜĆžčúŪā§ŽäĒ žĖłŽćĒžÉėŪĒĆŽßĀ(Undersampling)žĚī žěąŽč§. žė§Ž≤ĄžÉėŪĒĆŽßĀžĚė ŽĆÄŪĎúž†ĀžĚł ÍłįŽ≤ēžúľŽ°úŽäĒ žě¨ŪĎúžßĎ(Resampling), SMOTE (Synthetic Minority Oversampling Technique), Borderline-SMOTE ŽďĪžĚī žěąžúľŽ©į, žĖłŽćĒžÉėŪĒĆŽßĀžóźŽäĒ ŽěúŽć§ žĖłŽćĒžÉėŪĒĆŽßĀ, Tomek links ŽďĪžĚī žěąŽč§. ŪēėžßÄŽßĆ žĖłÍłČŪēú žÉėŪĒĆŽßĀ ÍłįŽ≤ē ž§Ď žĖłŽćĒžÉėŪĒĆŽßĀ ÍłįŽ≤ēžĚÄ ŽćįžĚīŪĄįŽ•ľ ž†úÍĪįŪēėŽäĒ Žį©žčĚžĚīÍłį ŽēĆŽ¨łžóź ž†ēŽ≥īžĚė žÜźžč§žĚī žīąŽěėŽźúŽč§ŽäĒ Ž¨łž†úÍįÄ žěąÍ≥†, žė§Ž≤ĄžÉėŪĒĆŽßĀ ÍłįŽ≤ēžĚÄ Ūē©žĄĪŽźú ŽćįžĚīŪĄįÍįÄ Íłįž°ī ŽćįžĚīŪĄįžôÄ žú†žā¨ŪēėÍłį ŽēĆŽ¨łžóź, žú†žā¨Ūēú ŽćįžĚīŪĄįŽ•ľ ŽįėŽ≥Ķ ŪēôžäĶŪē®žúľŽ°úžć® Í≥ľŽĆÄž†ĀŪē©(Overfitting)žĚī žēľÍłįŽź† žąė žěąŽč§ŽäĒ Ž¨łž†úÍįÄ žěąŽč§.
žēĆÍ≥†Ž¶¨ž¶ė žąėž§ÄžĚė Žį©Ž≤ēžĚÄ ŽćįžĚīŪĄį žąėž§ÄžĚė Žį©Ž≤ēžóź ŽĻĄŪēī ŽßéžĚÄ žóįÍĶ¨ŽäĒ žßĄŪĖČŽźėžßÄ žēäÍ≥† žěąžßÄŽßĆ, ŽĆÄŪĎúž†ĀžĚł Žį©Ž≤ēžúľŽ°úŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚī žěąŽč§. ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚÄ ŪĀīŽěėžä§Ž•ľ žė§Ž∂ĄŽ•ėŪĖąžĚĄ ŽēĆ ŽĻĄžö©žĚĄ Í≥†Ž†§Ūēī ž£ľŽäĒ Í≤ÉžúľŽ°ú, žÜĆžąėŪĀīŽěėžä§žĚė ŽĻĄžö©Ūē®žąė(Cost function)žóź ŽÜížĚÄ ÍįÄž§ĎžĻėŽ•ľ Ž∂Äžó¨ŪēėŽäĒ Žį©žčĚžĚīŽ©į, žÉėŪĒĆŽßĀ ÍłįŽ≤ēžĚė Žč®ž†źžĚĄ Ž≥īžôĄŪēėŽ©īžĄúŽŹĄ žĚīŽĮłžßÄžôÄ ÍįôžĚÄ ŽĻĄž†ēŪėēŽćįžĚīŪĄįžóź ž†Āžö©ŪēėÍłį žČ¨žöī žě•ž†źžĚī žěąžĖī Ž≥ł žóįÍĶ¨žóźžĄú ž†Āžö©žčúŪā® Žį©Ž≤ēžĚīŽč§.
2.2 žĄ†ŪĖČŽźú žú†žā¨žóįÍĶ¨
ÍĶ≠Žį©Ž∂ĄžēľžóźžĄú ŽĒ•Žü¨Žč̞̥ Ūôúžö©Ūēėžó¨ žĚīŽĮłžßÄŽ•ľ žĚłžčĚŪēėÍłį žúĄŪēú žčúŽŹĄŽäĒ Žč§žĖĎŪēėÍ≤Ć ž†Āžö©ŽźėÍ≥† žěąŽč§. ŪēėžßÄŽßĆ, ÍīÄŽ†®Žźú žóįÍĶ¨Žď§žĚÄ ŽĆÄŽ∂ÄŽ∂Ą ŽćįžĚīŪĄį Í∑†ŪėēžĚĄ ž†Ąž†úŽ°ú ŪēėÍ≥† žěąŽč§.
Jeong et al.[4]žĚÄ žě†žąėŪē®žĚė ŽĻĄžĚĆŪĖ• ŪÉźžßÄžú® ŪĖ•žÉĀžĚĄ žúĄŪēī ž†Ąžą†ž†ĀžĚł žÉĀŪô©žóźžĄú Ūē®ž†ēžĚė TVžĻīŽ©ĒŽĚľŽ°ú ŪöćŽďĚŪēú žėĀžÉĀžĚĄ ÍłįŽįėžúľŽ°ú žě†ŽßĚÍ≤Ş̥ ŽĻĄŽ°ĮŪēú Žßąžä§Ū䳎•ľ žė¨Ž¶¨Í≥† Ūē≠ŪēīŪēėŽäĒ žě†žąėŪē®žĚĄ ŪÉźžßÄŪēėŽäĒ Í≤ɞ̥ ž£ľŽ™©ŪĎúŽ°ú žě†žąėŪē®žĚė Žßąžä§ŪäłžôÄ Ūē≠Ūēīž§Ď žú†žā¨ŪēėÍ≤Ć Ž≥īžĚľ žąė žěąŽäĒ ŪĎúž†ĀŽď§žĚĄ Ž∂ĄŽ•ėŪēėŽäĒ žóįÍĶ¨Ž•ľ žßĄŪĖČŪēėžėÄŽč§.
Choi et al.[2]žĚÄ žēľÍįĄ ŽįŹ ž†Äžčúž†ē žÉĀŪô© ŪēėžóźžĄú Ūē®ž†ēžĚė EOTS(Electro Optical Tracking System)Žāė IRST(Infra-Red Search and Track)Ž•ľ Ūôúžö©Ūēėžó¨ ŪöćŽďĚŪēú žėĀžÉĀžúľŽ°ú ÍĶįŪē®Í≥ľ ŽĻĄÍĶįŪē®žĚė Ž∂ĄŽ•ėŽ•ľ žö©žĚīŪēėÍ≤Ć ŪēėÍłį žúĄŪēī žúĄ žě•ŽĻĄŽ°ú ŪöćŽďĚŪēú žėĀžÉĀžěźŽ£ĆžôÄ žú†žā¨ŪēėÍ≤Ć žĚīŽĮłžßÄŽ•ľ ž†Ąž≤ėŽ¶¨Ūēú ŪõĄ ŪēôžäĶŪēėžó¨ Ž∂ĄŽ•ėžú®žĚī ŪĖ•žÉĀŽź®žĚĄ ŪôēžĚłŪēėžėÄŽč§.
Lee et al.[3]žĚÄ ž†Ąžčúžóź ž†ĀŪē®žĚī žĄ†ŽįēžěźŽŹôžčĚŽ≥Ąžčúžä§ŪÖú(Automatic identification system)žĚĄ žĚėŽŹĄž†ĀžúľŽ°ú ŽĀĄŽäĒ Í≤ĹžöįžôÄ ÍįôžĚÄ žÉĀŪô©žóźžĄú Ūē®ž†ēžĚī ŪöćŽďĚŪēú žėĀžÉĀžúľŽ°ú ž£ľŽ≥Ä žĄ†ŽįēÍ≥ľ ÍĶįŪē®žĚĄ Ž∂ĄŽ•ėŪēėÍ≥†, Žč®Í≥Ąž†ĀžúľŽ°ú ÍĶįŪē® ŽāīžóźžĄúŽŹĄ žĄłŽ∂Äž†ĀžúľŽ°ú žĘÖŽ•ėŽ•ľ ŽāėŽąĄŽäĒ žčúžä§ŪÖúžĚĄ ž†úžēąŪēėžėÄŽč§. ŪēėžßÄŽßĆ žúĄ žóįÍĶ¨Žď§žĚÄ Ž™®ŽĎź ŽćįžĚīŪĄįžĚė Í∑†ŪėēžĚĄ ž†Ąž†úŪēėÍ≥† žěąÍłį ŽēĆŽ¨łžóź ŪėĄžč§ž†ĀžĚł Ž¨łž†úžóźžĄúŽäĒ ŽćįžĚīŪĄįŽ∂ąÍ∑†Ūėēžóź žĚėŪēú žėąžł° žĄĪŽä• ž†ÄŪēėÍįÄ žēľÍłįŽź† žąė žěąŽč§.
ŽćįžĚīŪĄįŽ∂ąÍ∑†ŪėēžĚĄ ŪēīÍ≤įŪēėÍłį žúĄŪēīžĄúŽäĒ ŽßéžĚÄ žóįÍĶ¨ÍįÄ žßĄŪĖČŽźėžóąŽč§. Jeong et al.[9]žĚÄ žÉĚŽ™ÖŽ≥īŪóėžā¨ Í≥†ÍįĚŽćįžĚīŪĄįžĚė Ž∂ąÍ∑†Ūėē Ž¨łž†úŽ•ľ ŪēīÍ≤įŪēėÍłį žúĄŪēėžó¨ Ž∂ąÍ∑†Ūėē ŽĻĄžú®žóź ŽĒįŽ•ł žė§Ž≤ĄžÉėŪĒĆŽßĀžĚė Ūö®Í≥ľžóź ŽĆÄŪēú žóįÍĶ¨Ž•ľ žßĄŪĖČŪēėžėÄŽč§. Lee et al.[10]žĚÄ ŽćįžĚīŪĄįžĚė Ž∂ąÍ∑†Ūėē Ž¨łž†úŽ•ľ ŪēīÍ≤įŪēėÍłį žúĄŪēėžó¨ žĖłŽćĒžÉėŪĒĆŽßĀ ŪēėŽäĒ Í≥ľž†ēžóźžĄú Ž™®žßĎŽč® Ž∂ĄŪŹ¨Ž•ľ Ūö®žú®ž†ĀžúľŽ°ú ž∂Ēž∂úŪēėžó¨ žÉėŪĒĆŽßĀŪēėŽäĒ Žį©Ž≤ēžĚĄ žóįÍĶ¨ŪēėžėÄŽč§. ŪēėžßÄŽßĆ žĚīŽü¨Ūēú žóįÍĶ¨Žď§žĚÄ Ž™®ŽĎź ž†ēŪėēŽćįžĚīŪĄįŽ•ľ Ūôúžö©Ūēú ŽćįžĚīŪĄįŽ∂ąÍ∑†Ūėē ŪēīÍ≤į ŽÖłŽ†•žĚė žĚľŪôėžĚīŽ©į, žĚīŽĮłžßÄžôÄ ÍįôžĚÄ ŽĻĄž†ēŪėēŽćįžĚīŪĄįžĚė Ž∂ąÍ∑†Ūėēžóź ŽĆÄŪēú žóįÍĶ¨ŽäĒ Í∑ĻžÜĆžąėžĚīŽč§. žĚīŽĮłžßÄžĚė ŽćįžĚīŪĄįŽ∂ąÍ∑†ŪėēžĚĄ ŪēīÍ≤įŪēėÍłį žúĄŪēī ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚĄ ž†Āžö©Ūēú žėąŽ°ú H. C. Kim.[11]žĚÄ ŪĀīŽěėžä§žĚė ŽćįžĚīŪĄį Íįúžąėžóź ŽĒįŽĚľ ÍįÄž§ĎžĻėŽ•ľ žÉĚžĄĪŪēėŽäĒ ž†ĀŽĆÄž†Ā ŽĻĄžö©ŽĮľÍįźŪēôžäĶžúľŽ°ú ÍįúžôÄ Í≥†žĖĎžĚīžĚė žĚīŽĮłžßÄžĚė Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄį Ž∂ĄŽ•ėžú®žĚī ŪĖ•žÉĀŽź®žĚĄ Ž≥īžėÄŽč§.
ŪēúŪéł, ÍĶ≠Žį©Ž∂ĄžēľžóźžĄúŽäĒ žĚīŽĮłžßÄ ŽŅźŽßĆ žēĄŽčąŽĚľ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįŽ•ľ ž≤ėŽ¶¨ŪēėÍłį žúĄŪēú žóįÍĶ¨ žěźž≤īÍįÄ Ž∂Äž°ĪŪēúŽćį, Í∑ł ž§Ď Kim et al.[12]žĚÄ Ž∂Äžā¨ÍīÄ žßĄÍłČ žöĒžĚłžĚĄ Ž∂ĄžĄĚŪē®žóź žěąžĖī ŽįúžÉĚŪēėŽäĒ Ž∂ąÍ∑†ŪėēŪēú ŽćįžĚīŪĄįŽ•ľ ž≤ėŽ¶¨ŪēėÍłį žúĄŪēī žÉėŪĒĆŽßĀ ÍłįŽ≤ēžĚĄ Ūôúžö©ŪēėžėÄŽč§.
Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ ÍĶ≠Žį©Ž∂ĄžēľžóźŽäĒ žĶúžīąŽ°ú žĚīŽĮłžßÄ žĚłžčĚžĚė Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄį Ž¨łž†úŽ•ľ ÍįúžĄ†ŪēėÍłį žúĄŪēú Žį©žēąžóź ŽĆÄŪēī žóįÍĶ¨ŪēėžėÄžúľŽ©į, ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚĄ ž†Āžö©Ūēú CNN Ž™®ŽćłžĚĄ žĚīžö©Ūēėžó¨ žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįžĄłŪäłžôÄ ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįžĄłŪ䳎•ľ ŪēôžäĶŪē®žúľŽ°úžć® Ž™®Žćł žĄĪŽä•žĚī ŪĖ•žÉĀŽź† žąė žěąžĚƞ̥ Ž≥īžĚīÍ≥†žěź ŪēúŽč§.
ž†úžēąŪēėŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®Žćł
Ž≥ł žóįÍĶ¨ŽäĒ ÍĶ≠Žį©Ž∂ĄžēľžĚė žĚīŽĮłžßÄ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄį Ž¨łž†úŽ•ľ ÍįúžĄ†ŪēėÍłį žúĄŪēī ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ė Ž™®Žćł ÍĶ¨ž∂ēÍ≥ľž†ēžĚĄ Fig. 2žôÄ ÍįôžĚī ŽćįžĚīŪĄį žąėžßĎ ŽįŹ ž†Ąž≤ėŽ¶¨, žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®Žćł ÍĶ¨ž∂ē ŽįŹ ŽĻĄÍĶź žč§Ūóė, Í≤įÍ≥ľ Í≤Äž¶ĚžĚė 3Žč®Í≥ĄŽ°ú žąėŪĖČŪēėžėÄžúľŽ©į, ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ė Ž™®ŽćłÍ≥ľ žĚľŽįė Ž™®ŽćłžĚė žį®žĚīŽ•ľ žßĀÍīÄž†ĀžúľŽ°ú žĚīŪēīŪēėÍłį žČĹŽŹĄŽ°Ě Í∑łŽ¶ľžúľŽ°ú ž†úžčúŪēėžėÄŽč§.
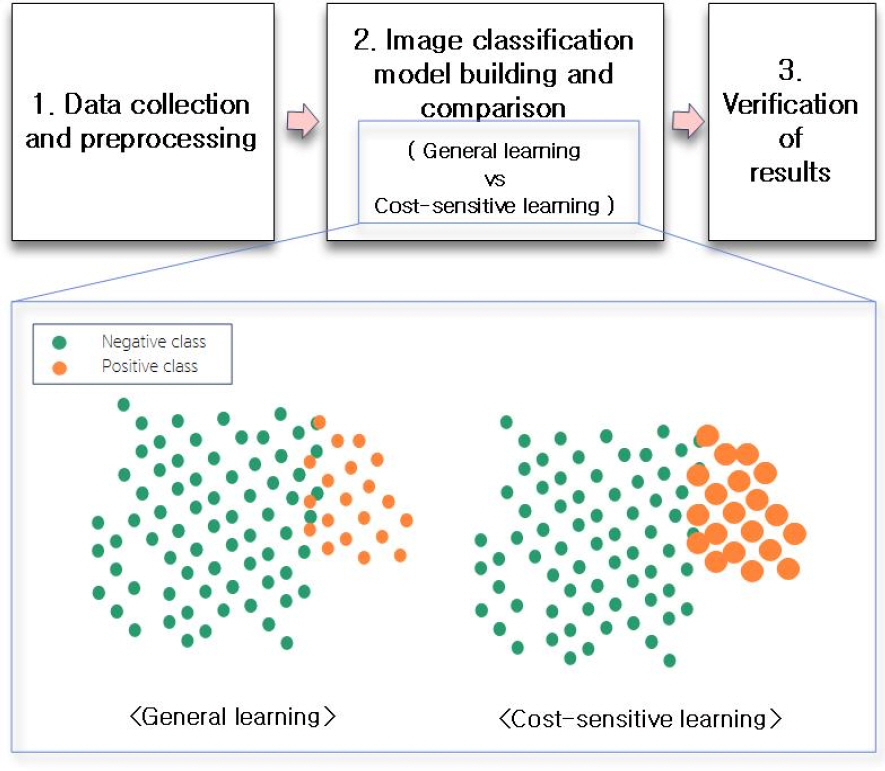
1Žč®Í≥Ą, ŽćįžĚīŪĄį žąėžßĎ ŽįŹ ž†Ąž≤ėŽ¶¨ Žč®Í≥ĄžóźžĄúŽäĒ žě†žąėŪē®/ŽĻĄžě†žąėŪē®Í≥ľ ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįŽ•ľ žąėžßĎŪēėÍ≥†, Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžĄłŪ䳎•ľ ÍĶ¨žĄĪŪēėžėÄŽč§. 2Žč®Í≥Ą, žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®Žćł ÍĶ¨ž∂ē ŽįŹ ŽĻĄÍĶź žč§ŪóėžĚÄ 2ÍįÄžßÄ ŽćįžĚīŪĄįŽ°ú Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ Žč¨Ž¶¨Ūēėžó¨ ÍĶ¨žĄĪŽźú žīĚ 4ÍįúžĚė ŽćįžĚīŪĄįžĄłŪ䳎•ľ žĚīžö©Ūēėžó¨, ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįėžĚė Žč§žąė CNN Ž™®ŽćłÍ≥ľ žĚľŽįėž†ĀžĚł Žč§žąė CNN Ž™®ŽćłžĚĄ ÍĶ¨ž∂ēŪēėžėÄŽč§. žĚī ŪõĄ ÍįĀÍįĀžĚė Ž™®ŽćłŽ°ú ŪÖĆžä§ŪäłžĚīŽĮłžßÄžóź ŽĆÄŪēú žėąžł° žĄĪŽä•žĚĄ ŪŹČÍįÄŪēėžėÄŽč§. 3Žč®Í≥Ą, Í≤įÍ≥ľ Í≤Äž¶Ě Žč®Í≥ĄžóźžĄúŽäĒ t-Í≤Äž†ēžĚĄ žĚīžö©Ūēėžó¨ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė CNN Ž™®Žćł žėąžł° žĄĪŽä•žĚė ŪŹČÍ∑†ÍįíÍ≥ľ žĚľŽįė CNN Ž™®Žćł žėąžł° žĄĪŽä•žĚė ŪŹČÍ∑†ÍįížĚī ŪÜĶÍ≥Ąž†ĀžúľŽ°ú žį®žĚīÍįÄ žěąŽäĒžßÄŽ•ľ Í≤Äž¶ĚŪēėžėÄŽč§.
3.1 ŽćįžĚīŪĄį žąėžßĎ ŽįŹ ž†Ąž≤ėŽ¶¨
Ž≥ł žóįÍĶ¨žóźžĄú žā¨žö©Ūēú ŽĎźÍįÄžßÄ ŽćįžĚīŪĄįžóź ŽĆÄŪēú žĄ§Ž™ÖžĚÄ Žč§žĚĆÍ≥ľ ÍįôŽč§.
žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįŽäĒ ž†Ąžą†ž†ĀžĚł žÉĀŪô©žóźžĄú žě†ŽßĚÍ≤Ş̥ ŽĻĄŽ°ĮŪēú Žßąžä§Ū䳎•ľ žė¨Ž¶¨Í≥† Ūē≠ŪēīŪēėŽäĒ žě†žąėŪē®žĚĄ ŪÉźžßÄŪēėŽäĒ Í≤ɞ̥ ŪēôžäĶžčúŪā§Íłį žúĄŪēī žā¨žö©ŪēúŽč§. žĚīŽ•ľ žúĄŪēī Žßąžä§Ū䳎•ľ žė¨Ž¶¨Í≥† Ūē≠ŪēīŪēėŽäĒ žě†žąėŪē®, Ž∂ÄžÉĀŪēú žě†žąėŪē® ŽďĪžĚė žě†žąėŪē® ŽćįžĚīŪĄįžôÄ žąėžÉĀŪē®žóźžĄú žě†žąėŪē® Žßąžä§Ū䳎°ú žė§žĚłŪē† žąė žěąŽäĒ ÍĻÉŽĆÄŽ∂ÄžĚī, ŽďĪŽ∂ÄŪĎú, žĖīŽßĚ Ž∂ÄžĚī, žÜĆŪėē žĖīžĄ†, ŽŹĆÍ≥†Žěė žßĎ䟎ü¨ŽĮł ŽďĪ Žč§žĖĎŪēú ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįŽ•ľ ÍĶ¨ÍłÄ ŽįŹ ŽĄ§žĚīŽ≤Ą žĚīŽĮłžßÄŽ•ľ Í≤ÄžÉČŪēėžó¨ žąėžßĎŪēėžėÄŽč§. žĚīŽēĆ, ŪėĄžč§žóźžĄú Ž∂ąÍ∑†ŪėēžĚī ŽįúžÉĚŪē† Í≤ɞ̥ Í≥†Ž†§Ūēėžó¨ žě†žąėŪē® 882žě•, ŽĻĄžě†žąėŪē® 4,010žě• žīĚ 4,892žě•žĚĄ žąėžßĎŪēėžėÄŽč§.
ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįŽäĒ Ūē®ž†ēžĚī ŪöćŽďĚŪēú žėĀžÉĀžúľŽ°ú ž£ľŽ≥Ä žĄ†ŽįēÍ≥ľ ÍĶįŪē®žĚĄ Ž∂ĄŽ•ėŪēėŽäĒ Í≤ɞ̥ ŪēôžäĶžčúŪā§Íłį žúĄŪēī žā¨žö©ŪēėŽ©į, žĄ†ŽįēžěźŽŹôžčĚŽ≥Ąžčúžä§ŪÖúžĚĄ Ž≥īžôĄŪēėÍłį žúĄŪēú žąėŽč®žúľŽ°ú Ūôúžö©ŪēėŽäĒ Í≤ÉžĚī Ž™©ž†ĀžĚīŽč§. žĚīŽ•ľ žúĄŪēī ÍĶįŪē®, žó¨ÍįĚžĄ†, žú†ž°įžĄ†, LNGžĄ† ŽďĪžĚė žĚīŽĮłžßÄŽ•ľ žļźÍłÄ(Kaggle)žĚĄ ŪÜĶŪēī ŪôēŽ≥ī ŪēėžėÄÍ≥†, ŪôēŽ≥īŪēú žĚīŽĮłžßÄŽ°ú ÍĶ¨žĄĪŪē† žąė žěąŽäĒ Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚė ŽćįžĚīŪĄį žąėŽüȞ̥ Žā®Íłī ŽāėŽ®łžßÄŽäĒ žěĄžĚėŽ°ú žā≠ž†úŪēėžėÄŽč§. ŽĒįŽĚľžĄú ÍĶįŪē® 758žě•, ŽĻĄÍĶįŪē® 6,675žě• žīĚ 7,433žě•žĚĄ žąėžßĎŪēėžėÄŽč§. žąėžßĎŪēú žě†žąėŪē®/ŽĻĄžě†žąėŪē®, ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįžĚė žėąŽäĒ Fig. 3Í≥ľ ÍįôŽč§.

žąėžßĎŪēú žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįŽäĒ 1(Positive): 5 (Negative)žĚė Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ ÍįÄžßÄÍ≥† žěąÍ≥†, Ž∂ąÍ∑†Ūėē ŽĻĄžú®žóź ŽĒįŽ•ł žĄĪŽä•žĚĄ ŪôēžĚłŪēėÍłį žúĄŪēī žĚī ž§Ď žě†žąėŪē® ŽćįžĚīŪĄįŽ•ľ ŽěúŽć§ŪēėÍ≤Ć žā≠ž†úŪēėžó¨ 1(Positive): 10(Negative)žĚė Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ ÍįĞߥ ŽćįžĚīŪĄįžĄłŪ䳎•ľ ž∂ĒÍįÄŽ°ú ÍĶ¨žĄĪŪēėžėÄŽč§. žąėžßĎŪēú ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįŽäĒ 1(Positive): 10(Negative)žĚė Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ ÍįÄžßÄÍ≥† žěąžóąžúľŽāė Žßąžį¨ÍįÄžßÄŽ°ú ÍĶįŪē® ŽćįžĚīŪĄįŽ•ľ ŽěúŽć§ŪēėÍ≤Ć žā≠ž†úŪēėžó¨ 1(Positive): 20(Negative)žĚė Ž∂ąÍ∑†Ūėē ŽĻĄžú® ŽćįžĚīŪĄįžĄłŪ䳎•ľ ž∂ĒÍįÄŽ°ú ÍĶ¨žĄĪŪēėžėÄŽč§. žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįžôÄ ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįžĚė Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ Žč§Ž•īÍ≤Ć Ūēú žĚīžú†ŽäĒ žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįŽäĒ ž†Āž†ąŪēú žąėŽüČžĚė žě†žąėŪē® ŽćįžĚīŪĄįŽ•ľ žú†žßÄŪēėŽ©īžĄú ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄį ŽĻĄžú®žĚĄ 20ÍĻĆžßÄ ŽÜížĚľŽßĆŪĀľ ž∂©Ž∂ĄŪēú ŽćįžĚīŪĄįŽ•ľ ŪôēŽ≥īŪēėŽäĒ Í≤ÉžĚī ž†úŪēúŽźėžóąÍłį ŽēĆŽ¨łžĚīŽč§.
ŪõąŽ†®ŽćįžĚīŪĄį(Training data)žôÄ Í≤Äž¶ĚŽćįžĚīŪĄį(Validation data)ŽäĒ žĚľŽįėž†ĀžúľŽ°ú 7:3, 8:2, 9:1žĚė ŽĻĄžú®Ž°ú ŽāėŽąĆ žąė žěąŽäĒŽćį, Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ ŽßéžĚī žā¨žö©ŽźėŽäĒ 8:2žĚė ŽĻĄžú®Ž°ú ŽāėŽąĄžóąÍ≥†, ŪÖĆžä§Ū䳎ćįžĚīŪĄį(Test data)ŽäĒ ŪÖĆžä§Ūäł ž†ēŪôēŽŹĄžĚė ž†ēŪôēžĄĪžĚĄ žúĄŪēėžó¨ Ž≥ĄŽŹĄŽ°ú 100ÍįúžĚė ŽćįžĚīŪĄįŽ•ľ Í∑†žĚľŪēėÍ≤Ć ÍįÄžßÄŽŹĄŽ°Ě ÍĶ¨žĄĪŪēėžėÄŽč§. žĄłŽ∂Ä ŽćįžĚīŪĄį ÍĶ¨žĄĪžĚÄ Table 1Í≥ľ ÍįôŽč§.
Table 1.
Data set information
3.2 ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®Žćł ÍĶ¨ž∂ē ŽįŹ ŽĻĄÍĶź žč§Ūóė
3.2.1 ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®Žćł ÍĶ¨ž∂ē
Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ žĚīŽĮłžßÄŽ•ľ ŪēôžäĶžčúŪā§Íłį žúĄŪēī žā¨ž†Ą ŪēôžäĶŽźú(Pre-trained) CNN Ž™®ŽćłžĚĄ ž†ĄžĚīŪēôžäĶžčúŪā§ŽäĒ Í≥ľž†ēžĚĄ ÍĪįž≥§Žč§.
CNN Ž™®ŽćłžĚÄ žĚīŽĮłžßÄŽ•ľ ŪēôžäĶžčúŪā§ŽäĒŽćį žĶúž†ĀŪôĒŽźėžĖīžěąŽäĒ ŽĒ•Žü¨ŽčĚ žēĆÍ≥†Ž¶¨ž¶ėžĚė Ūēú Žį©Ž≤ēžúľŽ°úžĄú ŪĀ¨Í≤Ć žĽ®Ž≥ľŽ£®žÖėžłĶ(Convolution layer)Í≥ľ ŪíÄŽßĀžłĶ(Pooling layer), žôĄž†ĄžóįÍ≤įžłĶ(Fully-connected layer)žúľŽ°ú ÍĶ¨žĄĪŽźúŽč§[13]. žĽ®Ž≥ľŽ£®žÖėžłĶžĚÄ žěÖŽ†•žĚīŽĮłžßÄžôÄ ŪēĄŪĄį(Filter)žôÄžĚė žĽ®Ž≥ľŽ£®žÖė žóįžāįžĚĄ ŪÜĶŪēī žĚīŽĮłžßÄžĚė ŪäĻžßēžĚĄ ž∂Ēž∂úŪēėŽäĒ žłĶžúľŽ°ú, ŪēôžäĶžĚĄ ŪÜĶŪēī ž†ēŪēīž†łžēľ ŪēėŽäĒ ŪĆĆŽĚľŽĮłŪĄį(Parameter)žĚł ÍįÄž§ĎžĻė(Weight)žôÄ ŽįĒžĚīžĖīžä§(Bias)ÍįÄ ž†ēŪēīžßĄŽč§. ŪíÄŽßĀžłĶ(Pooling layer)žĚÄ žĚīŽĮłžßÄžĚė žį®žõźžĚĄ ž∂ēžÜĆŪēėžó¨ ŪēĄžöĒŪēú žóįžāįŽüȞ̥ ÍįźžÜĆžčúŪā§Í≥†, žĚīŽĮłžßÄžĚė ÍįēŪēú ŪäĻžßēŽßƞ̥ žĄ†Ž≥ĄŪēėŽäĒ žłĶžúľŽ°ú ŪĆĆŽĚľŽĮłŪĄįŽ•ľ ÍįĖžßÄ žēäŽäĒŽč§ŽäĒ ŪäĻžĄĪžĚī žěąŽč§. žôĄž†ĄžóįÍ≤įžłĶ(Fully-connected layer)žĚÄ žĽ®Ž≥ľŽ£®žÖėžłĶžĚė 3žį®žõź ž∂úŽ†•ÍįížĚĄ 1žį®žõź Ž≤°ŪĄįŽ°ú ŽßƎ硫©į, Ž™®Žď† žú†ŽčõŽď§žĚī žĚīž†Ą žłĶžĚė žú†ŽčõŽď§Í≥ľ žóįÍ≤įŽźėžĖī žěąžĖī Žč§žąėžĚė ŪĆĆŽĚľŽĮłŪĄįŽ•ľ ÍįÄžßÄŽäĒ žłĶžĚīŽč§. ÍįÄžě• ŽßąžßÄŽßČžĚė žôĄž†ĄžóįÍ≤įžłĶžĚÄ ž∂úŽ†•žłĶžĚė žó≠Ūē†žĚĄ ŪēėŽ©į, ž∂úŽ†•žłĶžĚÄ ŪôúžĄĪŪôĒŪē®žąėŽ•ľ ÍĪįžĻú ž∂úŽ†•Íįížóź ŽĒįŽĚľ žĚīŽĮłžßÄžĚė ŪĀīŽěėžä§Ž•ľ žėąžł°ŪēúŽč§.
žā¨ž†Ą ŪēôžäĶŽźú CNN Ž™®ŽćłžĚīŽěÄ ŽĆÄŽüČžĚė ŽćįžĚīŪĄįžĄłŪ䳎•ľ žĚīžö©Ūēī ŽĮłŽ¶¨ ŪõąŽ†®ŽźėžĖī žěąŽäĒ CNN ŽĄ§ŪäłžõĆŪĀ¨Ž°ú, žĚľŽįėž†ĀžúľŽ°ú ILSVRC(Imagenet Large Scale Visual Recognition Competition)žóźžĄú 100ŽßĆžě•žĚī ŽĄėŽäĒ žĚīŽĮłžßÄ ŽćįžĚīŪĄįžĄłŪ䳞̳ žĚīŽĮłžßÄŽĄ∑(Imagenet)žĚĄ žĚīžö©Ūēėžó¨ ŪēôžäĶŪēú Ž™®ŽćłžĚī žā¨žö©ŽźúŽč§. žĚī Ž™®ŽćłžóźžĄú ŪēôžäĶŽźú ÍįÄž§ĎžĻėžôÄ ŽįĒžĚīžĖīžä§žôÄ ÍįôžĚÄ ŪĆĆŽĚľŽĮłŪĄįžôÄ ŽĄ§ŪäłžõĆŪĀ¨žĚė ÍĶ¨ž°įŽ•ľ žĚīžö©ŪēėŽ©ī ŽĄ§ŪäłžõĆŪĀ¨žĚė ŽßąžßÄŽßČ žłĶ Ž™á ÍįúŽßĆ žě¨ŪēôžäĶŪēėŽäĒ Í≤ÉŽßĆžúľŽ°úŽŹĄ ŽÜížĚÄ žĄĪŽä•žĚĄ Žāľ žąė žěąŽäĒŽćį, žĚīŽü¨Ūēú ŪēôžäĶ Žį©Ž≤ēžĚĄ ž†ĄžĚīŪēôžäĶžĚīŽĚľ ŪēúŽč§.
Ž≥ł žóįÍĶ¨žóźžĄú ž†ĄžĚīŪēôžäĶžĚĄ žúĄŪēī žā¨žö©Ūēú žā¨ž†Ą ŪēôžäĶŽźú Ž™®ŽćłžĚÄ VGG16[14]žĚīŽč§. VGG16žĚÄ 2014ŽÖĄ ILSVRCžóźžĄú ž§ÄžöįžäĻŪēú Ž™®ŽćłŽ°ú Žč§Ž•ł Ž™®ŽćłÍ≥ľ ŽĆÄŽĻĄŪēėžó¨ ÍĶ¨ž°įÍįÄ ÍįĄŽč®ŪēėÍ≥† žĄĪŽä•žĚī žöįžąėŪēėžó¨ žĚīŽĮłžßÄžĚė ž†ĄžĚīŪēôžäĶ Ž™®ŽćłŽ°ú ŽßéžĚī žā¨žö©ŽźúŽč§. Fig. 4ŽäĒ VGG16žĚė ÍĶ¨ž°įŽ•ľ ŽŹĄžčĚŪôĒŪēīžĄú Ž≥īžó¨ž£ľŽäĒŽćį, 13ÍįúžĚė žĽ®Ž≥ľŽ£®žÖėžłĶÍ≥ľ 5ÍįúžĚė ŪíÄŽßĀžłĶ, 3ÍįúžĚė žôĄž†ĄžóįÍ≤įžłĶžúľŽ°ú ÍĶ¨žĄĪŽźú Í≤ɞ̥ žēĆ žąė žěąŽč§.

Ž≥ł žóįÍĶ¨žóźžĄú ž†úžčúŪēú ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚÄ žĚľŽįė CNN Ž™®ŽćłÍ≥ľŽäĒ žÜźžč§Ūē®žąė(Cost function)Ž•ľ Žč§Ž•īÍ≤Ć ž†Āžö©žčúŪā®Žč§ŽäĒ ŪäĻžßēžĚī žěąŽč§. žúĄžĚė CNN Ž™®ŽćłžĚĄ ŪŹ¨Ūē®Ūēú ŽĒ•Žü¨ŽčĚ Ž™®ŽćłžóźžĄúŽäĒ žÜźžč§Ūē®žąėŽ•ľ ž†ēžĚėŪēėÍ≥† žĚīŽ•ľ žĶúžÜĆŪôĒŪēėŽäĒ Žį©ŪĖ•žúľŽ°ú ÍįúžĄ†ŪēúŽč§. žÜźžč§Ūē®žąėŽ•ľ ž†ēžĚėŪēėÍłį žúĄŪēīžĄúŽäĒ žöįžĄ† ŽćįžĚīŪĄįŽ•ľ ÍįÄž§ĎžĻėžôÄ ŽįĒžĚīžĖīžä§Ž•ľ ŪŹ¨Ūē®Ūēú ÍįÄžĄ§Ūē®žąėŽ°ú ŽāėŪÉÄŽāł ŪõĄ ÍįÄžĄ§Ūē®žąėÍįÄ žč§ž†úŽćįžĚīŪĄįžôÄ žĖľŽßąŽāė Žč§Ž•łžßÄŽ•ľ ŽāėŪÉÄŽāīŽäĒŽćį žĚīŽ•ľ žÜźžč§Ūē®žąėŽĚľ ŪēėŽ©į, ÍįÄž§ĎžĻėžôÄ ŽįĒžĚīžĖīžä§Ž•ľ žóÖŽćįžĚīŪäł ŪēėŽ©īžĄú žÜźžč§Ūē®žąėŽ•ľ žĶúžÜĆŪôĒžčúŪā®Žč§.
žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ¨łž†úžóźžĄú ž£ľŽ°ú žā¨žö©ŽźėŽäĒ žÜźžč§Ūē®žąė ž§Ď ŪĀīŽěėžä§ÍįÄ 2Íįú žĚľ ŽēĆ ž†Āžö©ŪēėŽäĒ žĚīžßĄ ÍĶźžį® žóĒŪ䳎°úŪĒľ Ūē®žąė(Binary cross entropy function)Ž•ľ ŽćįžĚīŪĄį ŪēėŽāėžóź ŽĆÄŪēī ŽāėŪÉÄŽāīŽ©ī (1)Í≥ľ ÍįôžĚī ž†ēžĚėŽź† žąė žěąŽč§.
žó¨ÍłįžĄú tkŽäĒ ž†ēŽčĶ Ž†ąžĚīŽłĒ, ykŽäĒ Ž™®ŽćłžĚė ž∂úŽ†•, kŽäĒ ŽćįžĚīŪĄįžĚė žį®žõź, KŽäĒ ŽćįžĚīŪĄįžĚė ž†Ąž≤ī žį®žõź žąėŽ•ľ žĚėŽĮłŪēúŽč§. žĚīŽēĆ ŽćįžĚīŪĄįÍįÄ NÍįúŽĚľŽ©ī žčĚžĚÄ (2)žôÄ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§. žĚī žčĚžĚī žĚėŽĮłŪēėŽäĒ ŽįĒŽäĒ ÍįĀ ŽćįžĚīŪĄįžĚė ÍĶźžį® žóĒŪ䳎°úŪĒľ Ūē®žąėŽ•ľ NÍįúžĚė ŽćįžĚīŪĄįŽ°ú Ūôēžě•Ūēú ŪõĄ, Žč§žčú NžúľŽ°ú ŽāėŽąĒžúľŽ°úžć® ž†ēÍ∑úŪôĒŪēú Í≤ÉžúľŽ°ú[15], žĚľŽįėž†ĀžĚł žĚīžßĄ Ž∂ĄŽ•ėŽ¨łž†úžĚė žÜźžč§Ūē®žąėŽ°ú žā¨žö©ŪēėŽäĒ žčĚžĚīŽč§.
(2) žč̞̥ ŪĀīŽěėžä§ Ž≥ĄŽ°ú ÍĶźžį® žóĒŪ䳎°úŪĒľ Ūē®žąėŽ•ľ ÍĶ¨ŪēėÍ≥† ÍįĀ ŪĀīŽěėžä§žĚė ÍĶźžį® žóĒŪ䳎°úŪĒľ Ūē®žąėŽ•ľ ŽćĒŪēīž£ľŽäĒ Žį©žčĚžúľŽ°ú ž†ēžĚėŪēėŽ©ī (3)Í≥ľ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§.
žó¨ÍłįžĄú tjmkŽäĒ ž†ēŽčĶ Ž†ąžĚīŽłĒ, yjmkŽäĒ Ž™®ŽćłžĚė ž∂úŽ†•, tjmkŽäĒ ŽćįžĚīŪĄįžĚė žį®žõź, KŽäĒ ŽćįžĚīŪĄįžĚė ž†Ąž≤ī žį®žõź žąė, mžĚÄ jŪĀīŽěėžä§žĚė mŽ≤ąžßł ŽćįžĚīŪĄį, MjžĚÄ jŪĀīŽěėžä§ÍįÄ ÍįĖŽäĒ ŽćįžĚīŪĄįžĚė žąė, NžĚÄ ž†Ąž≤ī ŽćįžĚīŪĄįžĚė žąėŽ•ľ žĚėŽĮłŪēúŽč§.
Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ žā¨žö©Ūēú ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚė žÜźžč§Ūē®žąėŽäĒ ŪĀīŽěėžä§ Ž≥ĄŽ°ú ÍįÄž§ĎžĻėŽ•ľ Žč§Ž•īÍ≤Ć ž†Āžö©Ūēú Žį©Ž≤ēžúľŽ°ú (4)žôÄ ÍįôžĚī ž†ēžĚėŽź† žąė žěąŽč§.
(4)
žó¨ÍłįžĄú M0žĚÄ Žč§žąėŪĀīŽěėžä§žĚė ŽćįžĚīŪĄį žąė, M1žĚÄ žÜĆžąėŪĀīŽěėžä§žĚė ŽćįžĚīŪĄį žąė, CŽäĒ ŪĀīŽěėžä§ ÍįÄž§ĎžĻėŽ•ľ žĚėŽĮłŪēúŽč§. ž¶Č žÜĆžąėŪĀīŽěėžä§Ž•ľ žė§Ž∂ĄŽ•ė ŪĖąžĚĄ Í≤ĹžöįžóźŽäĒ C ŽįįŽßĆŪĀľ ŪĀį žÜźžč§Ūē®žąė ÍįížĚĄ ÍįĖÍ≤Ć Žź®žĚĄ žĚėŽĮłŪēúŽč§. žó¨ÍłįžĄú ž†ēŽčĶ Ž†ąžĚīŽłĒžĚł tjmkžĚÄ 0ŽėźŽäĒ 1 ž§Ď ŪēėŽāėžĚė ÍįížĚĄ ÍįĖÍ≤Ć ŽźėŽ©į, Žč§žąėŪĀīŽěėžä§žĚėtjmkžĚÄ 0, žÜĆžąėŪĀīŽěėžä§žĚė tjmkžĚÄ 1žĚī ŽźúŽč§. ŽĒįŽĚľžĄú (4)ŽäĒ (5)žôÄ ÍįôžĚī Žč§žčú ž†ēžĚėŪē† žąė žěąŽč§.
ŪĀīŽěėžä§ ÍįÄž§ĎžĻė C Ž•ľ Í≤įž†ēŪēėŽäĒ Žį©Ž≤ēžóź ŽĆÄŪēī žĚľŽįėŪôĒŽźú žĚīŽ°†žĚÄ žēĄžßĀ žēĆŽ†§žßÄžßÄ žēäžēėžúľŽ©į, ŪÜĶžÉĀ Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ žó≠žúľŽ°ú ŽįėžėĀŪēėžó¨ Í∑†ŪėēžĚĄ žĚīŽ£®Í≤Ć ŪēėŽäĒ Žį©Ž≤ēžĚī ŽßéžĚī Ūôúžö©ŽźėÍ≥† žěąŽč§[16].
3.2.2 ŽĻĄÍĶź žč§Ūóė
ŽĻĄÍĶź žč§ŪóėžĚĄ žúĄŪēī žöįžĄ†ž†ĀžúľŽ°ú ŪēėžĚīŪćľŪĆĆŽĚľŽĮłŪĄįŽ•ľ žĄ§ž†ēŪēėžėÄŽč§. ŪēėžĚīŪćľŪĆĆŽĚľŽĮłŪĄįŽěÄ žóįÍĶ¨žěźÍįÄ žßÄž†ēŪēī ž£ľžĖīžēľ ŪēėŽäĒ Žč§žĖĎŪēú ÍįížúľŽ°ú ŽĄ§ŪäłžõĆŪĀ¨ ÍĶ¨ž°įžĚė žąėž†ē ž†ēŽŹĄ, žĖľŽßąŽāė ŽßéžĚÄ žłĶžĚĄ žě¨ŪēôžäĶ žčúŪā¨ Í≤ɞ̳žßÄ žó¨Ž∂ÄžôÄ žôĄž†ĄžóįÍ≤įžłĶžĚė žú†Žčõ(Unit)žĚė Íįúžąė, ŪôúžĄĪŪôĒ Ūē®žąė, ŪēôžäĶžĄłŽĆÄ(Epoch), ŽįįžĻė(Batch), ŪēôžäĶŽ•†(Learning rate) ŽďĪžĚī Í∑ł žėąžĚīŽč§. Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ VGG16žĚė ŽĄ§ŪäłžõĆŪĀ¨ ÍĶ¨ž°į ž§Ď ŽßąžßÄŽßČ žôĄž†ĄžóįÍ≤į 3ÍįúžłĶžĚĄ žā≠ž†úŪēėÍ≥† žÉąŽ°úžöī 1ÍįúžłĶžĚĄ ÍĶ¨žĄĪŪēú Ží§ žôĄÍ≤įžóįÍ≤įžłĶžĚė žú†Žčõ Íįúžąė, ŪēôžäĶŽ•†, ŽįįžĻė ŽďĪžĚĄ Ž≥ÄÍ≤ĹŪēīÍįÄŽ©į ŪēôžäĶÍ≤įÍ≥ľŽ•ľ ŪôēžĚłŪēėžėÄŽč§. ŪēėžĚīŪćľŪĆĆŽĚľŽĮłŪĄį ŪäúŽčĚžĚė žĄłŽ∂ÄÍįížĚÄ Table 2žôÄ ÍįôŽč§. ŽėźŪēú, ŽŹôžĚľŪēú ŪēėžĚīŪćľŪĆĆŽĚľŽĮłŪĄį žĄ§ž†ē ž°įÍĪīžĚĄ ÍįĞߥŽč§Í≥† ŪēėŽćĒŽĚľŽŹĄ ÍįÄž§ĎžĻė žīąÍłįÍįížĚī Žß§Ž≤ą Žč¨ŽĚľžßÄŽ©īžĄú žč§Ūóė Í≤įÍ≥ľžĚė žė§žį®ÍįÄ ž°įÍłąžĒ© ŽįúžÉĚŪē† žąė žěąÍłį ŽēĆŽ¨łžóź ŽŹôžĚľ ž°įÍĪīžóźžĄú 3‚ąľ4Ž≤ąžĒ© ŪēôžäĶžčúžľįŽč§. ž¶Č ŪēėŽāėžĚė ŽćįžĚīŪĄįžĄłŪ䳞󟞥ú ŪēėžĚīŪćľŪĆĆŽĚľŽĮłŪĄįžĚė žĄ§ž†ēžĚī Žč§Ž•ł 6ÍįÄžßÄ Í≤ĹžöįŽ°ú ÍįĀÍįĀ 3‚ąľ4Ž≤ą ŪēôžäĶžĚĄ ŪēėŽźė, žĚīŽ•ľ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė Ž™®ŽćłžóźžĄú 20ŪöĆ ŪēôžäĶŪēėÍ≥† žĚľŽįė Ž™®ŽćłžóźžĄú 20ŪöĆ ŪēôžäĶŪēėžėÄŽč§. ŽŹôžĚľŪēú žč§ŪóėžĚĄ žīĚ 4ÍįÄžßÄ ŽćįžĚīŪĄįžĄłŪ䳞󟞥ú žč§žčúŪēėžėÄÍłį ŽēĆŽ¨łžóź 160ŪöĆžĚė žč§Ūóė ŪõĄ ÍįĀÍįĀžĚė Í≤įÍ≥ľŽ•ľ ŪôēžĚłŪēėžėÄŽč§. žĄłŽ∂Äž†ĀžĚł žč§Ūóė Í≥ľž†ēžĚÄ Fig. 5žôÄ ÍįôŽč§. žĚī ž§Ď ŽĻĄžö©ŽĮľÍįźŪēôžäĶ žčú žÜĆžąėŪĀīŽěėžä§žóź ŽĆÄŪēú ÍįÄž§ĎžĻėŽäĒ žā¨ž†ĄŽ∂ĄžĄĚžĚĄ ŪÜĶŪēī Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚė žó≠žĚīŽāė Í∑ł žĚīžÉĀžĚľ ŽēĆ žĄĪŽä•žĚī ŪĖ•žÉĀŽź®žĚĄ ŪôēžĚłŪēėÍ≥†, žĚīŽ•ľ ŽįėžėĀŪēėžó¨ Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ žó≠žúľŽ°ú ŽįėžėĀŪēėŽäĒ Žį©Ž≤ēžĚĄ žā¨žö©ŪēėžėÄŽč§. ž¶Č Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚī 1(Positive): 10(Negative)žĚł Í≤Ĺžöį žÜĆžąėŪĀīŽěėžä§žĚł žĖĎžĄĪžóź 10žĚė ÍįÄž§ĎžĻėŽ•ľ ž†Āžö©ŪēėžėÄŽč§.
Table 2.
Hyperparameter tuning
| Fully-connected layer number | Fully-connected layer unit number | Activation function | |
| 1 | 256, 512, 1024 | relu | |
| Drop out ratio(%) | Epoch | Batch size | Learning rate |
| 0.5 | 200 | 32, 100 | 10‚ąí4, 10‚ąí5 |
Ž™®Žćł žĄĪŽä•žĚĄ žł°ž†ēŪēėÍłį žúĄŪēī ŪôēžĚłŪēú žĄĪŽä•ŪŹČÍįÄ žßÄŪĎúŽäĒ ž†ēŪôēŽŹĄ(Accuracy), ž†ēŽįÄŽŹĄ(Precision), žě¨ŪėĄžú®(Recall), F1-scorežĚīŽ©į, žĚī ž§Ď F1-scorežĚĄ Íłįž§ÄžúľŽ°ú Ž™®Žćł žĄĪŽä•žĚĄ ŪŹČÍįÄŪēėžėÄŽč§. ÍįĀ žĄĪŽä•ŪŹČÍįÄ žßÄŪĎúŽď§žĚī žĚėŽĮłŪēėŽäĒ ŽįĒŽäĒ Table 3Í≥ľ ÍįôžĚÄ ž†ēžė§Ž∂ĄŽ•ėŪĎú(Confusion matrix)Ž•ľ žĚīžö©Ūēī ŽāėŪÉÄŽāľ žąė žěąŽäĒŽćį, Í∑ł žĚėŽĮłŽäĒ žēĄŽěėžôÄ ÍįôŽč§.
Table 3.
Confusion matrix
| - |
True condition |
||
|---|---|---|---|
| Positive | Negative | ||
| Predicted condition | Positive | True positive (TP) | False positive (FP) |
| Negative | False negative (FN) | True negative (TN) | |

žĚľŽįėž†ĀžúľŽ°ú Ž®łžč†Žü¨ŽčĚžĚīŽāė ŽĒ•Žü¨ŽčĚžĚė Ž∂ĄŽ•ėŽ™®ŽćłžóźžĄú žĄĪŽä•ŪŹČÍįÄŽ•ľ žúĄŪēī ÍįÄžě• ŽßéžĚī žā¨žö©ŪēėŽäĒ žßÄŪĎúŽäĒ ž†ēŪôēŽŹĄ(Accuracy)žĚīŽč§. ž†ēŪôēŽŹĄŽäĒ (6)Í≥ľ ÍįôžĚī ž†ēžĚėŪē† žąė žěąŽč§.
Í∑łŽü¨Žāė ž†ēŪôēŽŹĄŽäĒ Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžóźžĄú Žč®žĚľ žĄĪŽä•ŪŹČÍįÄ žßÄŪĎúŽ°ú žā¨žö©ŽźėÍłįžóźŽäĒ ž†úŪēúžā¨Ūē≠žĚī žěąŽč§. 90ÍįúžĚė žĚĆžĄĪ ŽćįžĚīŪĄįžôÄ 10ÍįúžĚė žĖĎžĄĪžĚł ŽćįžĚīŪĄįÍįÄ žěąŽäĒ žÉĀŪô©žĚĄ žÉĚÍįĀŪēī Ž≥ľŽēĆ, ŽßĆžēĹ 100ÍįúžĚė ŽćįžĚīŪĄį ž†Ąž≤īŽ•ľ žĚĆžĄĪžúľŽ°ú Ž∂ĄŽ•ėŽ•ľ ŪēėŽäĒ Ž™®ŽćłžĚī žěąŽč§Ž©ī ž†ēŪôēŽŹĄŽäĒ 90 %ŽĚľÍ≥† Ūē† žąė žěąŽč§. ŪēėžßÄŽßĆ, žĄłŽ∂Äž†ĀžúľŽ°ú žāīŪéīŽ≥īŽ©ī žĚī Ž™®ŽćłžĚī žĖĎžĄĪžĚł ŽćįžĚīŪĄįŽ•ľ Ž∂ĄŽ•ėŪēī Žāľ ÍįÄŽä•žĄĪžĚÄ 0 %žĚł Í≤ÉžĚīŽč§. ŽĒįŽĚľžĄú Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄįžóźžĄúŽäĒ ž†ēŽįÄŽŹĄ(Precision), žě¨ŪėĄžú®(Recall), F1-scorežôÄ ÍįôžĚÄ žĄĪŽä•ŪŹČÍįÄ žßÄŪĎúŽ•ľ ž∂ĒÍįÄž†ĀžúľŽ°ú ŪôēžĚłŪēėžó¨žēľ ŪēúŽč§.
ž†ēŽįÄŽŹĄ(Precision)ŽäĒ Ž™®ŽćłžĚī žĖĎžĄĪ(Positive class)žúľŽ°ú Í≤Äž∂úŪēīŽāł Í≤É ž§Ď žč§ž†ú žĖĎžĄĪžĚł Í≤ɞ̥ žĚėŽĮłŪēėŽäĒ Íłįž§ÄžúľŽ°ú (7)Í≥ľ ÍįôžĚī ŽāėŪÉÄŽāľ žąė žěąŽč§.
žě¨ŪėĄžú®(Recall)žĚÄ žč§ž†ú ŪēīŽčĻ ŽćįžĚīŪĄį ž§Ď Ž™®ŽćłžĚī žė¨ŽįĒŽ•īÍ≤Ć žĖĎžĄĪžúľŽ°ú Í≤Äž∂úŪēīŽāł Í≤ɞ̥ žĚėŽĮłŪēėŽäĒ Íłįž§ÄžúľŽ°ú žĖĎžĄĪžĚł Í≤ɞ̥ ŽÜďžĻėžßÄ žēäÍ≥† žčĚŽ≥ĄŪēī ŽāīŽäĒžßÄŽ•ľ ŪĆźŽč®ŪēėŽäĒ žßÄŪĎúžĚīŽ©į (8)Í≥ľ ÍįôŽč§.
ž†ēŽįÄŽŹĄžôÄ žě¨ŪėĄžú®žĚÄ Ūēú žąėžĻėÍįÄ ŽÜížēĄžßÄŽ©ī Žč§Ž•ł žąėžĻėÍįÄ ŽāģžēĄžßÄŽäĒ ÍīÄÍ≥ĄŽ•ľ ÍįÄžßÄÍ≥† žěąÍłį ŽēĆŽ¨łžóź, ž†ēŽįÄŽŹĄžôÄ žě¨ŪėĄžú® ž§Ď ŪēėŽāėžĚė žąėžĻėÍįÄ Í∑ĻŽč®ž†ĀžúľŽ°ú ŽÜížĚÄ Í≤ÉŽ≥īŽč§ŽäĒ ŽĎź žąėžĻėÍįÄ ž†Āž†ąŪēėÍ≤Ć ž°įŪôĒŽ•ľ žĚīŽ£®ŽäĒ Ž™®ŽćłžĚī ŽćĒ žĘčžĚÄ Ž™®ŽćłžĚīŽĚľÍ≥† Ūē† žąė žěąŽč§[17]. žĚīŽ•ľ žúĄŪēú ŪŹČÍįÄ žßÄŪĎúžĚł F1-scoreŽäĒ (9)žôÄ ÍįôžĚī ž†ēŽįÄŽŹĄžôÄ žě¨ŪėĄžú®žĚė ž°įŪôĒŪŹČÍ∑†žúľŽ°ú ŽāėŪÉÄŽāľ žąė žěąŽč§.
160ŪöĆ žč§ŪóėžĚė F1-score Í≤įÍ≥ľÍįíÍ≥ľ ŪÜĶÍ≥ĄŽüČžĚÄ Table 4žôÄ ÍįôžĚī žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįžĄłŪ䳞󟞥ú Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚī 1(Positive): 5(Negative)žĚł Í≤Ĺžöį ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė F1-score ŪŹČÍ∑†ÍįížĚī 70.50 %Ž°ú žĚľŽįė Ž™®ŽćłžĚė 58.45 % Ž≥īŽč§ 12.05 % ŽÜížēėÍ≥†, 1(Positive): 10(Negative)žĚł Í≤ĹžöįžóźŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė ÍįížĚī 70.38 %Ž°ú žĚľŽįė Ž™®ŽćłŽ≥īŽč§ 22.32 % ŽÜížēėŽč§. ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįžĄłŪ䳞󟞥ú Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚī 1(Positive): 10(Negative)žĚł Í≤Ĺžöį ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė F1-score ŪŹČÍ∑†ÍįížĚī 89.84 %Ž°ú žĚľŽįė Ž™®ŽćłžĚė 87.91 % Ž≥īŽč§ 1.93 % ŽÜížēėÍ≥†, 1(Positive): 20(Negative)žĚł Í≤ĹžöįŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė ÍįížĚī 81.53 %Ž°ú žĚľŽįė Ž™®ŽćłŽ≥īŽč§ 4.73 % ŽÜížēėŽč§.
Table 4.
F1-score results for each model
ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚĄ ž†Āžö©Ūē®žóź ŽĒįŽ•ł žĄĪŽä• ÍįúžĄ†žĚÄ Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚī ŽÜížĚĄžąėŽ°Ě žĽ§žßźžĚĄ žēĆ žąė žěąžóąŽč§. Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚī žÉĀŽĆÄž†ĀžúľŽ°ú ŽāģžĚĄ ŽēĆ ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚĄ ž†Āžö©ŪēėžßÄ žēäžēėžĚĄ ŽēĆžĚė F1-scorežĚī žė§Ū칎†§ ŽÜížĚÄ Í≤ĹžöįÍįÄ žĚľŽ∂Ä žěąžóąžßÄŽßĆ, Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚī ŽÜížĚĄ ŽēĆŽäĒ Í∑ł Í≤ĹžöįÍįÄ ž§ĄžĖīŽď§žóąŽč§. ŪŹČÍ∑† ŽėźŪēú Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚī ŽÜížĚĄ ŽēĆ ŽćĒ ŪĀ¨Í≤Ć ŪĖ•žÉĀŽźėžóąžúľŽ©į,ŪĎúž§ÄŪéłžį®ŽäĒ 4ÍįúžĚė Í∑łŽ£ĻžóźžĄú Ž™®ŽĎź ž§ĄžĖīŽď† Í≤ɞ̥ ŪôēžĚłŪē† žąė žěąžóąŽč§. žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįžĄłŪäłžôÄ ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįžĄłŪäłÍįÄ ŽŹôžĚľŪēú Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚł 1(Positive): 10(Negative)žóźžĄú ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ž†Āžö© žó¨Ž∂Äžóź ŽĒįŽ•ł žĄĪŽä• ÍįúžĄ† Ūö®Í≥ľÍįÄ ŪĀ¨Í≤Ć žį®žĚī ŽāėŽäĒ Í≤ÉžĚÄ ŽĎź ŽćįžĚīŪĄįžĄłŪäłžĚė ŽćįžĚīŪĄį žąėŽüČ žį®žĚīžôÄ ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄį žĄłŪäłžĚė ŪĎúž†Ā ŪĀ¨ÍłįÍįÄ ŪĀ¨Í≥† ŪäĻžßēžĚī žÉĀŽĆÄž†ĀžúľŽ°ú ŽöúŽ†∑Ūēī ÍĶ¨Ž≥ĄžĚī žö©žĚīŪēėÍłį ŽēĆŽ¨łžĚł Í≤ÉžúľŽ°ú ŪĆźŽč®ŪēėžėÄŽč§.
ŪÜĶÍ≥Ąž†Ā Í≤Äž¶Ě
žĶúžĘÖž†ĀžúľŽ°ú ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė žĄĪŽä•žĚī ŪÜĶÍ≥Ąž†ĀžúľŽ°ú žú†žĚėŽĮłŪēėÍ≤Ć žöįžąėŪēėŽč§ŽäĒ Í≤ɞ̥ ŪôēžĚłŪēėÍłį žúĄŪēī RŪĒĄŽ°úÍ∑łŽě®žĚĄ žĚīžö©Ūēėžó¨ ŽŹÖŽ¶ĹŪĎúŽ≥ł t-Í≤Äž†ēžĚĄ žč§žčúŪēėžėÄŽč§.
t-Í≤Äž†ēžĚĄ žčúŪĖČŪēėÍłį žúĄŪēīžĄúŽäĒ t-Í≤Äž†ēžĚė ÍįÄž†ēžĚł ž†ēÍ∑úžĄĪ(Normality)Í≥ľ ŽďĪŽ∂ĄžāįžĄĪ(Homoskedasticity)žĚĄ ŪôēžĚłŪēėžó¨žēľ ŪēúŽč§. ŽćįžĚīŪĄįÍįÄ ž†ēÍ∑úžĄĪžĚĄ ŽßĆž°ĪŪē† ŽēĆžóź t-Í≤Äž†ēžĚĄ žč§žčúŪē† žąė žěąÍ≥†, ŽďĪŽ∂ĄžāįžĄĪžĚĄ ŪôēžĚłŪēėžó¨ ŽďĪŽ∂ĄžāįžĚľ Í≤Ĺžöį ŽďĪŽ∂Ąžāį t-Í≤Äž†ē, žĚīŽ∂Ąžāį(Heteroskedasticity)žĚľ Í≤Ĺžöį žĚīŽ∂Ąžāį t-Í≤Äž†ēžĚĄ žčúŪĖČŪēúŽč§.
4.1 ž†ēÍ∑úžĄĪ ŪôēžĚł
ž†ēÍ∑úžĄĪ ŪôēžĚłžĚÄ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłŽ°ú ŪŹČÍįÄŪēú 20ÍįúžĚė F1-scoreÍįíÍ≥ľ žĚľŽįė Ž™®ŽćłŽ°ú ŪŹČÍįÄŪēú 20ÍįúžĚė F1-scoreÍįíŽď§žĚė ÍįĀÍįĀžĚė ž†ēÍ∑úžĄĪ žó¨Ž∂ÄŽ•ľ ŪŹČÍįÄŪēúŽč§. Ž≥ł žóįÍĶ¨žóźžĄúŽäĒ 4ÍįúžĚė ŽćįžĚīŪĄįžĄłŪ䳎•ľ Ūôúžö©ŪēėžėÄÍłį ŽēĆŽ¨łžóź žīĚ 8ÍįúžĚė Í∑łŽ£Ļžóź ŽĆÄŪēī ž†ēÍ∑úžĄĪžĚĄ ŪôēžĚłŪēėžėÄŽč§.
ž†ēÍ∑úžĄĪžĚÄ žčúÍįĀž†Ā Žį©Ž≤ēÍ≥ľ Í≤Äž†ēžĚĄ ŪÜĶŪēī ŪôēžĚłŪē† žąė žěąŽč§. žčúÍįĀž†ĀžúľŽ°úŽäĒ Q-QŽŹĄŽ•ľ ŪÜĶŪēī ŪôēžĚłŪē† žąė žěąŽäĒŽćį, Q-QŽŹĄŽäĒ ŽćįžĚīŪĄįÍįÄ ŪäĻž†ē Ž∂ĄŪŹ¨Ž•ľ ŽĒįŽ•īŽäĒžßÄŽ•ľ žčúÍįĀž†ĀžúľŽ°ú Í≤ÄŪ܆ŪēėŽäĒ Žį©Ž≤ēžĚīŽč§. žó¨ÍłįžĄú QŽäĒ Ž∂ĄžúĄžąė(Quantile)žĚė žēĹžĖīŽ°ú, Ž∂ĄžúĄžąėŽď§žĚĄ žį®Ūäłžóź Í∑łŽ¶¨Í≥† ŽāėŽ©ī ŽćįžĚīŪĄįžôÄ ŽĻĄÍĶźŪēėÍ≥†žěź ŪēėŽäĒ Ž∂ĄžúĄžąė ÍįĄžóź žßĀžĄ† ÍīÄÍ≥ĄÍįÄ Ž≥īžĚīŽäĒžßÄ ŪôēžĚłŪē† žąė žěąŽč§[18]. Q-QŽŹĄŽ•ľ Ūôúžö©Ūēėžó¨ ž†ēÍ∑úŽ∂ĄŪŹ¨Ž•ľ ŪôēžĚłŪē† ŽēĆžóźŽäĒ ŽćįžĚīŪĄįÍįÄ 45ŽŹĄ žĄ†žóź ÍįÄÍĻĆžöłžąėŽ°Ě ž†ēÍ∑úžĄĪžĚĄ ÍįĞߥŽč§Í≥† ŽßźŪē† žąė žěąŽäĒŽćį, Ž≥ł žóįÍĶ¨žóźžĄú žā¨žö©Ūēú Í∑łŽ£ĻŽ≥Ą 20Íįú F1-scoreÍįížĚĄ Q-QŽŹĄŽ°ú ŽāėŪÉÄŽāł Í≤įÍ≥ľÍįíŽď§žĚÄ 45ŽŹĄžóź ÍįÄÍĻĚÍ≤Ć Ž∂ĄŪŹ¨Ūē®žĚĄ ŪôēžĚłŪē† žąė žěąžóąŽč§.
Í∑łŽü¨Žāė žčúÍįĀž†Ā ŪôēžĚłŽßĆžúľŽ°úŽäĒ ž†ēÍ∑úžĄĪžĚĄ ÍįĞߥŽč§Í≥† ŽßźŪē† žąė žěąŽäĒžßÄ žó¨Ž∂ÄÍįÄ Ž∂ąŪôēžč§ŪēėŽč§. ŽĒįŽĚľžĄú ž†ēÍ∑úžĄĪ Í≤Äž†ē Žį©Ž≤ē ž§Ď ŪēėŽāėžĚł žÉ§ŪĒľŽ°ú žúĆŪĀ¨ Í≤Äž†ē(Shapiro-wilk's test)žúľŽ°ú ŪôēžĚłŪēī Ž≥īžēėŽč§. žÉ§ŪĒľŽ°ú žúĆŪĀ¨ Í≤Äž†ēžĚė Í∑ÄŽ¨īÍįÄžĄ§žĚÄ ŽćįžĚīŪĄįÍįÄ ž†ēÍ∑úŽ∂ĄŪŹ¨ŽĚľŽäĒ Í≤ÉžĚīŽ©į, ŽĆÄŽ¶ĹÍįÄžĄ§žĚÄ ž†ēÍ∑úŽ∂ĄŪŹ¨žôÄ Žč§Ž•īŽč§ŽäĒ Í≤ÉžĚīŽč§.
žÉ§ŪĒľŽ°ú žúĆŪĀ¨ Í≤Äž†ē Í≤įÍ≥ľ p-valueÍįížĚÄ Table 5žôÄ ÍįôžĚī ŪÜĶžÉĀž†ĀžúľŽ°ú žú†žĚėžąėž§ÄžúľŽ°ú žā¨žö©ŪēėŽäĒ 0.1, 0.05, 0.01 Ž≥īŽč§ Ž™®ŽĎź ŪĀį ÍįížúľŽ°ú Í∑ÄŽ¨īÍįÄžĄ§žĚĄ ÍłįÍįĀŪē† žąė žóÜŽč§. ŽĒįŽĚľžĄú ÍįĀ ŽćįžĚīŪĄįŽď§žĚÄ ž†ēÍ∑úžĄĪžĚĄ ÍįĞߥŽč§Í≥† ŽßźŪē† žąė žěąŽč§.
Table 5.
Results of shapiro-wilk's test
4.2 ŽďĪŽ∂ĄžāįžĄĪ ŪôēžĚł
ŽďĪŽ∂ĄžāįžĄĪžĚÄ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłŽ°ú ŪŹČÍįÄŪēú F1-scoreÍįíŽď§Í≥ľ žĚľŽįė Ž™®ŽćłŽ°ú ŪŹČÍįÄŪēú F1-scoreÍįíŽď§žĚė Ž∂ĄžāįžĚī ŽŹôžĚľŪēúžßÄ žó¨Ž∂ÄŽ•ľ ŪŹČÍįÄŪēúŽč§. ŽďĪŽ∂ĄžāįžĄĪžĚĄ Í≤Äž†ē Žį©Ž≤ēžúľŽ°ú ŪôēžĚłŪēėÍłįžóź žē장ú žÉĀžěźÍ∑łŽ¶ľ(Boxplot)žĚĄ ŪÜĶŪēī ŽćįžĚīŪĄįžĚė Ž∂ĄŪŹ¨Ž•ľ žčúÍįĀž†ĀžúľŽ°ú ŪôēžĚłŪēī Ž≥īžēėŽč§. žÉĀžěźÍ∑łŽ¶ľžĚÄ ŽćįžĚīŪĄįžĚė 1¬∑3žā¨Ž∂ĄžúĄžąė, ž§ĎžēôÍįí(Median), žĶúŽĆÄÍįí, žĶúžÜĆÍįí, žĚīžÉĀžĻė ŽďĪžĚĄ ŽāėŪÉÄŽāīŽäĒ Í∑łŽ¶ľžúľŽ°ú žÉĀžěź žēąžóź 1¬∑3žā¨Ž∂ĄžúĄžąė Žāīžóź žěąŽäĒ ŽćįžĚīŪĄįŽď§žĚī ž°īžě¨ŪēúŽč§. žčúÍįĀžÉĀ žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįŽ°ú ŪēôžäĶžčúŪā® Ž™®ŽćłžĚė ŪÖĆžä§Ūäł F1-scoreÍįížĚÄ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłÍ≥ľ žĚľŽįė Ž™®ŽćłžĚė ŪŹČÍ∑† ŽįŹ Ž∂Ąžāį žį®žĚīÍįÄ ŽĻĄÍĶźž†Ā ŪĀ¨Í≥†, ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįŽ°ú ŪēôžäĶžčúŪā® Ž™®ŽćłžĚÄ ŪŹČÍ∑†žĚÄ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė Í≤įÍ≥ľÍįÄ ŽÜížßÄŽßĆ Ž∂ĄžāįžĚÄ ŪĀ¨Í≤Ć Žč§Ž•īžßÄ žēäžĚƞ̥ žēĆ žąė žěąžóąŽč§.
ŪēėžßÄŽßĆ žčúÍįĀŽßĆžúľŽ°úŽäĒ ŽďĪŽ∂ĄžāįžĄĪžĚĄ ÍįÄžßÄŽäĒžßÄ žó¨Ž∂ÄŽ•ľ ž†ēŪôēŪēėÍ≤Ć Žč®ž†ēŪēėÍłį žĖīŽ†ĶŽč§. ŽĒįŽĚľžĄú ž∂ĒÍįÄž†ĀžúľŽ°ú ŽĎź Í∑łŽ£ĻžĚė Ž∂ĄžāįžĚĄ ŽĻĄÍĶźŪēėŽäĒ F-Í≤Äž†ēžĚĄ ŪÜĶŪēī ŽďĪŽ∂ĄžāįžĄĪžĚĄ ŪôēžĚłŪēī Ž≥īžēėŽč§. F-Í≤Äž†ēžĚė Í∑ÄŽ¨īÍįÄžĄ§žĚÄ ŽĎź žßώ讞Ěė ŽćįžĚīŪĄįŽäĒ Ž∂ĄžāįžĚī ÍįôŽč§ŽäĒ Í≤ÉžĚīŽ©į, ŽĆÄŽ¶ĹÍįÄžĄ§žĚÄ ŽĎź žßώ讞Ěė ŽćįžĚīŪĄįŽäĒ Ž∂ĄžāįžĚī Žč§Ž•īŽč§ŽäĒ Í≤ÉžĚīŽč§. žú†žĚėžąėž§ÄžĚÄ 0.05Ž°ú žßÄž†ēŪēėžėÄŽč§.
F-Í≤Äž†ē Í≤įÍ≥ľ Table 6Í≥ľ ÍįôžĚī žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįŽ°ú ŪēôžäĶžčúŪā® Ž™®ŽćłžĚė p-valueÍįížĚÄ 0.05Ž≥īŽč§ žěĎžēĄ Í∑ÄŽ¨īÍįÄžĄ§žĚĄ ÍłįÍįĀ, ŽĆÄŽ¶ĹÍįÄžĄ§žĚĄ žĪĄŪÉĚŪē† žąė žěąÍ≥†, ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįŽ°ú ŪēôžäĶžčúŪā® Ž™®ŽćłŽď§žĚė p-valueÍįížĚÄ 0.05Ž≥īŽč§ žĽ§ Í∑ÄŽ¨īÍįÄžĄ§žĚĄ ÍłįÍįĀŪē† žąė žóÜŽč§. ŽĒįŽĚľžĄú žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚīŪĄįŽ°ú ŪēôžäĶžčúŪā® Ž™®ŽćłžĚÄ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė ŪÖĆžä§Ūäł F1-scoreÍįíÍ≥ľ žĚľŽįė Ž™®ŽćłžĚė ŪÖĆžä§Ūäł F1-scoreÍįížĚė Ž∂ĄžāįžĚī Žč§Ž•īŽ©į, ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįŽ°úŪēôžäĶžčúŪā® Ž™®ŽćłžĚÄ ŽĎź Í∑łŽ£ĻÍįĄ Ž∂ĄžāįžĚī ÍįôŽč§Í≥† Ūē† žąė žěąŽč§.
4.3 t-Í≤Äž†ē
ž†ēÍ∑úžĄĪ Í≤Äž†ēÍ≥ľ ŽďĪŽ∂ĄžāįžĄĪ Í≤Äž†ē Í≤įÍ≥ľŽ•ľ ŽįĒŪÉēžúľŽ°ú, 2ÍįÄžßÄ ŽćįžĚīŪĄįŽ°ú Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ žĄúŽ°ú Žč¨Ž¶¨Ūēėžó¨ ÍĶ¨žĄĪŽźú žīĚ 4ÍįúžĚė ŽćįžĚīŪĄįžĄłŪ䳎•ľ žĚīžö©Ūēėžó¨ ŪēôžäĶŪēú Ž™®ŽćłŽď§žĚė F1-scoreÍįížóź ŽĆÄŪēú t-Í≤Äž†ēžĚĄ žč§žčúŪēėžėÄŽč§. Í≤Äž†ē Žāīžö©žĚÄ ÍįĀ ŽćįžĚīŪĄįžĄłŪäł Ž≥ĄŽ°ú ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė ŪÖĆžä§Ūäł F1-score ŪŹČÍ∑†ÍįíÍ≥ľ žĚľŽįė Ž™®ŽćłžĚė ŪÖĆžä§Ūäł F1-score ŪŹČÍ∑†ÍįížĚī ŪÜĶÍ≥Ąž†ĀžúľŽ°ú žú†žĚėŽĮłŪēėÍ≤Ć Žč§Ž•łžßÄ ŪôēžĚłŪēėŽäĒ Í≤ÉžĚīŽč§. žĚīŽ•ľ žúĄŪēú ÍįÄžĄ§ žĄ§ž†ēžĚÄ Žč§žĚĆÍ≥ľ ÍįôŽč§.
žĚīŽēĆ őľcost-sensitive ŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė ŪÖĆžä§Ūäł F1-score ŪŹČÍ∑†ÍįížĚīÍ≥†, őľgeneralŽäĒ žĚľŽįė Ž™®ŽćłžĚė ŪÖĆžä§Ūäł F1-score ŪŹČÍ∑†ÍįížĚīŽč§. žú†žĚėžąėž§ÄžĚÄ 0.05Ž°ú žĄ†ž†ēŪēėžėÄŽč§.
Í≤Äž†ē Í≤įÍ≥ľŽäĒ Table 7Í≥ľ ÍįôžĚī 4ÍįÄžßÄ ŽćįžĚīŪĄįžĄłŪ䳞󟞥ú Ž™®ŽĎź p-valueÍįížĚī 0.05Ž≥īŽč§ žěĎžēĄ Í∑ÄŽ¨īÍįÄžĄ§žĚĄ ÍłįÍįĀŪēėÍ≥†, ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė ŪÖĆžä§Ūäł F1-score ŪŹČÍ∑†ÍįížĚī žĚľŽįė Ž™®ŽćłžĚė ŪÖĆžä§Ūäł F1-score ŪŹČÍ∑†ÍįíŽ≥īŽč§ ŪĀ¨Žč§ŽäĒ ŽĆÄŽ¶ĹÍįÄžĄ§žĚĄ žĪĄŪÉĚŪēėžėÄŽč§. ŽĒįŽĚľžĄú ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė žĄĪŽä•žĚī žöįžąėŪē®žĚĄ ŪÜĶÍ≥Ąž†ĀžúľŽ°ú Í≤Äž¶ĚŪēėžėÄŽč§.
Table 7.
Results of t-test
Í≤į Ž°†
Ž≥ł žóįÍĶ¨ŽäĒ ÍĶ≠Žį©Ž∂Ąžēľ žĚīŽĮłžßÄ Ž∂ĄŽ•ėžĚė Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄį Ž¨łž†úŽ•ľ ÍįúžĄ†ŪēėÍłį žúĄŪēú Žį©žēąžúľŽ°ú žě†žąėŪē®/ŽĻĄžě†žąėŪē® ŽćįžĚī ŪĄįžĄłŪäłžôÄ ÍĶįŪē®/ŽĻĄÍĶįŪē® ŽćįžĚīŪĄįžĄłŪäłžóź ŽĆÄŪēī ŪĀīŽěėžä§žóź ŽĒįŽĚľ žĄúŽ°ú Žč§Ž•ł ŽĻĄžö©žĚĄ Ž∂Äžó¨ŪēėŽäĒ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ(Cost-sensitive learining)žĚĄ ž†Āžö©Ūēėžó¨ CNN Ž™®ŽćłžĚĄ ŪÜĶŪēī ŪēôžäĶžčúžľįŽč§.
2ÍįÄžßÄ ŽćįžĚīŪĄįŽ°ú Ž∂ąÍ∑†Ūėē ŽĻĄžú®žĚĄ žĄúŽ°ú Žč¨Ž¶¨Ūēú žīĚ 4ÍįúžĚė ŽćįžĚīŪĄįžĄłŪ䳎•ľ žĚīžö©Ūēėžó¨ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė Ž™®Žćł 80Íįú, žĚľŽįė Ž™®Žćł 80ÍįúŽ•ľ ÍĶ¨ž∂ē ŪõĄ ŽŹôžĚľŪēú ŪÖĆžä§Ū䳎ćįžĚīŪĄįžóź ŽĆÄŪēú žėąžł° žĄĪŽä•žĚĄ ŪŹČÍįÄŪēėžėÄŽč§.
Í≤įÍ≥ľž†ĀžúľŽ°ú 4ÍįúžĚė ŽćįžĚīŪĄįžĄłŪ䳞󟞥ú ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė F1-score ŪŹČÍ∑†ÍįížĚī žĚľŽįė Ž™®ŽćłžĚė F1-score ŪŹČÍ∑†ÍįíŽ≥īŽč§ žĶúŽĆÄ 22.32 %žóźžĄú žĶúžÜĆ 1.93 % ŽÜížēėŽč§. ŽėźŪēú žĚī Í≤įÍ≥ľÍįÄ ŪÜĶÍ≥Ąž†ĀžúľŽ°ú žú†žĚėŽĮłŪēúžßÄ ŪôēžĚłŪēėÍłį žúĄŪēī ž†ēÍ∑úžĄĪ Í≤Äž†ēÍ≥ľ ŽďĪŽ∂ĄžāįžĄĪ Í≤Äž†ē Í≤įÍ≥ľŽ•ľ ŽįĒŪÉēžúľŽ°ú t-Í≤Äž†ēžĚĄ žč§žčúÍ≤įÍ≥ľ 4ÍįÄžßÄ ŽćįžĚīŪĄįžĄłŪ䳞󟞥ú Ž™®ŽĎź p-valueÍįížĚī 0.05Ž≥īŽč§ žěĎžēĄ ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ÍłįŽįė žĚīŽĮłžßÄ Ž∂ĄŽ•ėŽ™®ŽćłžĚė F1-score ŪŹČÍ∑†ÍįížĚī ŪĀ¨Žč§ŽäĒ ŽĆÄŽ¶ĹÍįÄžĄ§žĚī žú†žĚėŽĮłŪē®žĚĄ ŪôēžĚłŪēėžėÄŽč§.
Ž≥ł žóįÍĶ¨žĚė ž†úŪēúžā¨Ūē≠žĚÄ Žč§žĖĎŪēú Ž∂ąÍ∑†ŪėēŽćįžĚīŪĄį ž≤ėŽ¶¨ÍłįŽ≤ēžĚĄ ž†Āžö©Ūēī Ž≥īžßÄ Ž™ĽŪĖąŽč§ŽäĒ ž†źžĚīŽč§. ŪĀīŽěėžä§Ž≥Ą ŽćįžĚīŪĄį Ūôēžě•(Data augmentation), GAN(Generative Adversarial Network)žĚĄ ŪÜĶŪēú žė§Ž≤ĄžÉėŪĒĆŽßĀžĚīŽāė žĚīŽĮłžßÄ žā≠ž†úŽ•ľ ŪÜĶŪēú žĖłŽćĒžÉėŪĒĆŽßĀ ŽďĪžĚė Žį©Ž≤ēÍ≥ľ ŽĻĄžö©ŽĮľÍįźŪēôžäĶžĚė Ūö®Í≥ľŽŹĄ ŽĻĄÍĶźŽ•ľ žßĄŪĖČŪēėžßÄ Ž™ĽŪēėžėÄŽč§. ŽėźŪēú, ŽĻĄžö©ŽĮľÍįźŪēôžäĶ ž§Ď Ž≥ł žóįÍĶ¨žóźžĄú žßĄŪĖČŪēú žÜźžč§Ūē®žąėŽ•ľ žąėž†ēŪēėŽäĒ Žį©Ž≤ē žôł žēĆÍ≥†Ž¶¨ž¶ėžóź ÍīÄŪēú žóįÍĶ¨Ž°ú žßĄŪĖČŽźėÍ≥† žěąŽäĒ žóĒŪ䳎°úŪĒľ(Entropy) ÍłįŽįė SVM, ŽĻĄžö©ŽĮľÍįź ŽěúŽć§ ŪŹ¨Ž†ąžä§Ūäł(Cost-sensitive random forest) ŽďĪÍ≥ľžĚė ŽĻĄÍĶźŽäĒ ŪĖ•ŪõĄ ž∂ĒÍįÄ žóįÍĶ¨Ž•ľ ŪÜĶŪēī Ž≥īžôĄŪēīžēľŪē† Í≥ľž†úžĚīŽč§.




