



м„ң лЎ
мөңк·ј лӮЁл¶Ғ к°„ л¶Ҳнҷ•мӢӨн•ң көӯм ң м •м„ё л°Ҹ н•ҙм•ҲкІҪкі„ мҙҲмҶҢ мІ мҲҳ л“ұ н•ҙм•Ҳ кІҪкі„лҠҘл Ҙ м•Ҫнҷ”лЎң мқҙм—җ лҢҖмқ‘н•ҳкё° мң„н•ң мҲҳлӢЁмңјлЎң л¬ҙмқёмҲҳмғҒм •(USV, Unmanned Surface Vehicle) к°ңл°ң л°Ҹ ліҙкёүмқҙ мӢңкёүн•ң мӢӨм •мқҙлӢӨ.
н•ҙмҷём—җм„ңлҠ” лҜёкөӯмқҳ Spartan Scout USV, ASW USV, UISS, мҳҒкөӯмқҳ C-Sweep, н”„лһ‘мҠӨмқҳ Mk2, мәҗлӮҳлӢӨмқҳ Dolphin, мқҙмҠӨлқјм—ҳмқҳ Protector л“ұмқҙ к°ңл°ңлҗҳм—Ҳмңјл©° көӯлӮҙм—җм„ңлҠ” мөңк·ј LIGл„ҘмҠӨмӣҗмқҳ н•ҙкІҖв… м—җ мқҙм–ҙ н•ҙкІҖв…Ўк°Җ к°ңл°ң мӨ‘м—җ мһҲлӢӨ[1].
л¬ҙмқёмҲҳмғҒм • мҲҳмҡ”к°Җ кёүмҰқн•Ём—җ л”°лқј мқҙлҘј мһҗмңЁм ҒмңјлЎң мҡҙмҡ©н•ҳкё° мң„н•ң мһҗмңЁ мҡҙн•ӯ кё°мҲ , мһҘм• л¬ј мқёмӢқ л°Ҹ 충лҸҢ нҡҢн”ј кё°мҲ л“ұмқҳ к°ңл°ңмқҙ нҷңл°ңн•ҳкІҢ 진н–үлҗҳкі мһҲмңјл©°, л¬ҙмқёмҲҳмғҒм •мқҖ мһҗмңЁ мҡҙн•ӯ мӢң мӮ¬мҡ©мһҗк°Җ м„Өм •н•ң кІҪлЎңлҘј л”°лқј м•Ҳм „н•ҳкІҢ лӘ©м Ғм§Җк№Ңм§Җ лҸ„м°©н•ҙм•јн•ңлӢӨ. кІҪлЎң кі„нҡҚмқҖ нҒ¬кІҢ м „м—ӯ кІҪлЎңмҷҖ м§Җм—ӯ кІҪлЎңкі„нҡҚмңјлЎң лӮҳлҲҢ мҲҳ мһҲлӢӨ. м „м—ӯ кІҪлЎңлҠ” л¬ҙмқёмҲҳмғҒм •мқҙ нҷҳкІҪм—җ лҢҖн•ң м •ліҙлҘј м§ҖлҸ„нҳ•нғңлЎң лҜёлҰ¬ м•Ңкі мһҲлӢӨкі к°Җм •н•ҳкі м§ҖлҸ„м—җ н‘ңкё°лҗң м§Җнҳ• л°Ҹ мқёкіөкө¬мЎ°л¬јкіј 충лҸҢн•ҳм§Җ м•ҠлҠ” мөңм Ғ кІҪлЎңлҘј мғқм„ұн•ҳлҠ” кІғмқҙкі м§Җм—ӯ кІҪлЎңлҠ” мӢңк°„м—җ л”°лқј ліҖн•ҳлҠ” лҸҷм Ғ нҷҳкІҪм—җм„ң 충лҸҢмқ„ нҡҢн”јн•ҳкё° мң„н•ҙ м „м—ӯ кІҪлЎңлҘј нҒ¬кІҢ лІ—м–ҙлӮҳм§Җ м•Ҡмңјл©ҙм„ң м•Ҳм „н•ң нҡҢн”ј кІҪлЎңлҘј кі„нҡҚн•ҳлҠ” кІғмқҙлӢӨ[2вҖ“3].
Dynamic Window Approach(DWA) м•Ңкі лҰ¬мҰҳмқҖ м§Җм—ӯ кІҪлЎң кі„нҡҚмңјлЎң мқҙлҸҷмІҙмқҳ мҶҚлҸ„, л°©н–Ҙ л°Ҹ м„јм„ң м •ліҙлЎңл¶Җн„° м–»лҠ” мһҘм• л¬јкіјмқҳ кұ°лҰ¬лҘј нҶ лҢҖлЎң мөңм Ғмқҳ м„ мҶҚлҸ„мҷҖ к°ҒмҶҚлҸ„лҘј лҸ„м¶ңн•ҳм—¬ мһҘм• л¬јмқ„ нҡҢн”јн•ҳкі лӘ©м Ғм§Җм—җ лҸ„лӢ¬н•ҳлҠ” л°©лІ•мқҙлӢӨ[3]. кІ°кіјм ҒмңјлЎң DWAлҠ” м ҒмқҖ м—°мӮ°лҹүм—җ мқҳн•ң л№ лҘё мҲҳн–үмҶҚлҸ„лЎң мӢӨм ң нҷҳкІҪм—җм„ң мҡ°мҲҳн•ң мһҘм• л¬ј 충лҸҢ нҡҢн”ј м„ұлҠҘмқ„ ліҙмқёлӢӨ. к·ёлҹ¬лӮҳ кё°мЎҙмқҳ DWAлҠ” лӘ©м Ғм§Җ к°„мқҳ м§Ғм„ мңјлЎң мқҙлЈЁм–ҙм§ҖлҠ” кІҪлЎңм„ м—җ лҢҖн•ң 추종мқҖ кі л Өн•ҳм§Җ м•Ҡм•„ 충лҸҢ нҡҢн”ј кё°лҸҷ мқҙнӣ„, кІҪлЎңм„ м—җм„ң лІ—м–ҙлӮң мҡҙн•ӯмқ„ н• мҲҳ мһҲлӢӨ[3]. мқҙлҹ¬н•ң л¬ём ңлҠ” кІҪлЎңм„ м¶”мў…мқ„ мң„н•ң к°ңм„ лҗң DWA м•Ңкі лҰ¬мҰҳ(2017)м—җ мқҳн•ҙ ліҙмҷ„н• мҲҳ мһҲлӢӨ. н•ҳм§Җл§Ң м—¬м „нһҲ кІҪлЎңм„ мқёк·јм—җ мһҘм• л¬јмқҙ л§Һкұ°лӮҳ мһҘм• л¬ј мӮ¬мқҙмқҳ мўҒмқҖ мҳҒм—ӯмқ„ нҶөкіјн•ҳлҠ” кІҪмҡ°, 진мһ…н•ҳм§Җ лӘ»н•ҙ нҒ¬кІҢ мҡ°нҡҢн•ҳкұ°лӮҳ м§ҖлӮҳм№ң к°җмҶҚмңјлЎң мҡҙн•ӯ мқҙ м§Җм—°лҗңлӢӨ. лҳҗн•ң DWAмқҳ лӘ©м Ғн•ЁмҲҳлҠ” лӘ©м Ғм§Җм—җ лҢҖн•ң л°©н–Ҙ, мҶҚлҸ„, мһҘм• л¬јкіјмқҳ кұ°лҰ¬мҷҖ кҙҖл Ёлҗң н•ЁмҲҳмқҳ н•©мңјлЎң н‘ңнҳ„лҗҳл©°, н•ҙлӢ№ н•ЁмҲҳм—җ к°ҖмӨ‘м№ҳлҘј мЎ°м Ҳн•Ём—җ л”°лқј м„ л°•мқҳ мҡҙлҸҷ нҠ№м„ұмқҙ кІ°м •лҗҳкё° л•Ңл¬ём—җ кІҪлЎңм„ м¶”мў…м—җ мһҲм–ҙ мөңм Ғмқҳ к°ҖмӨ‘м№ҳк°Җ мЈјліҖ нҷҳкІҪм—җ л”°лқј лӢ¬лқјм§„лӢӨ. мҰү, нҠ№м • кІҪлЎңм„ м¶”мў… мӢң нҒ¬кІҢ мҡ°нҡҢн•ҳкұ°лӮҳ мўҒмқҖ мҳҒм—ӯмқ„ к°ҖлЎңм§Ҳлҹ¬м•јн•ҳлҠ” кІҪмҡ° л“ұ лӘЁл“ мғҒнҷ©м—җм„ң мөңм Ғмқҳ к°ҖмӨ‘м№ҳлҘј м•Ң мҲҳ мһҲлӢӨл©ҙ нҡЁмңЁм Ғмқё кІҪлЎң кі„нҡҚмқҙ к°ҖлҠҘн• кІғмқҙлӢӨ. к·ёлҹ¬лӮҳ нңҙлҰ¬мҠӨнӢұн•ҳкІҢ кІ°м •н•ң к°ҖмӨ‘м№ҳлҘј лӘЁл“ мғҒнҷ©м—җм„ң мӢӨн—ҳмқ„ нҶөн•ҙ лҸ„м¶ңн•ҳкё° м–ҙл өлӢӨ. мқҙлҹ¬н•ң л¬ём ңлҠ” к°•нҷ”н•ҷмҠө кё°лІ•мқ„ нҷңмҡ©н•ҳм—¬ н•ҷмҠөмқ„ нҶөн•ҙ мӢң뮬л Ҳмқҙм…ҳ мғҒм—җм„ң к°ҖмӨ‘м№ҳлҘј кІ°м •н• мҲҳ мһҲлӢӨ[4].
ліё л…јл¬ём—җм„ңлҠ” мң„м—җ м–ёкёүн•ң л¬ём ңм җл“Өмқ„ ліҙмҷ„н•ҳм—¬ 충лҸҢ мң„н—ҳмқҙ лҶ’мқҖ нҷҳкІҪм—җм„ң мһҘм• л¬јмқ„ нҡҢн”јн•ҳкі м§Җм •лҗң кІҪлЎңм„ м¶”мў…мқ„ мһҳ мҲҳн–үн• мҲҳ мһҲлҠ” к°•нҷ”н•ҷмҠө кё°л°ҳ DWA м•Ңкі лҰ¬мҰҳмқ„ м ңм•Ҳн•ңлӢӨ. лЁјм Җ кё°мЎҙмқҳ DWA м•Ңкі лҰ¬мҰҳкіј м ңмӢңлҗң м•Ңкі лҰ¬мҰҳмқ„ м„ӨлӘ…н•ҳкі ліёлЎ м—җм„ң мӢң뮬л Ҳмқҙм…ҳ кІ°кіјлҘј нҶөн•ң 비көҗ кІҖмҰқмқ„ мҲҳн–үн•ҳкі мһҗ н•ңлӢӨ.
Dynamic Window Approach
DWA м•Ңкі лҰ¬мҰҳмқҖ нҳ„мһ¬ м„ л°•мқҳ мҶҚлҸ„м—җм„ң лӢӨмқҢ мӢңк°„к№Ңм§Җ м·Ён• мҲҳ мһҲлҠ” лӘ©н‘ң м„ мҶҚлҸ„мҷҖ к°ҒмҶҚлҸ„мқҳ мһ…л Ҙ лІ”мң„лҘј лӮҳнғҖлӮҙлҠ” Dynamic WindowлҘј мғқм„ұн•ҳкі мқҙ мҳҒм—ӯ м•Ҳ м„ мҶҚлҸ„(v)мҷҖ к°ҒмҶҚлҸ„(w) мҢҚ мӨ‘м—җ лӘ©м Ғн•ЁмҲҳмқҳ к°’мқҙ мөңлҢҖк°Җ лҗҳлҠ” лӘ©н‘ң м„ мҶҚлҸ„мҷҖ к°ҒмҶҚлҸ„мқҳ мҢҚмқ„ лҸ„м¶ңн•ңлӢӨ.


мң„ Fig 1м—җм„ң Vd мҳҒм—ӯмқҖ лӢӨмқҢ мӢңк°„к№Ңм§Җ м·Ён• мҲҳ мһҲлҠ” м„ мҶҚлҸ„мҷҖ к°ҒмҶҚлҸ„мқҳ мҳҒм—ӯмқ„ лӮҳнғҖлӮё кІғмңјлЎң мӢқ (1)лЎң н‘ңнҳ„лҗҳл©°, м„ л°•мқҳ к°Җк°җ мҶҚлҸ„мҷҖ нҡҢм „ мҶҚлҸ„ мӮ¬м–‘мқ„ л°ҳмҳҒн• мҲҳ мһҲлӢӨ. VsлҠ” м„ л°•мқҙ мң„м№ҳн•ң кіөк°„ лӮҙм—җ м·Ён• мҲҳ мһҲлҠ” мөңлҢҖ, мөңмҶҢ мҳҒм—ӯмқ„ лӮҳнғҖлӮҙл©°, VaлҠ” м„ л°•мқҳ нҳ„мһ¬ мҶҚлҸ„м—җм„ң мһҘм• л¬јкіј 충лҸҢн•ҳм§Җ м•Ҡкі м ңлҸҷ к°ҖлҠҘн•ң мҶҚлҸ„ лІ”мң„мқҙл©°, мөңмў…м ҒмңјлЎң мӢқ (2)кіј к°ҷмқҙ 3к°ң мҳҒм—ӯмқҳ көҗ집합м—җ н•ҙлӢ№н•ҳлҠ” Vr лӮҙмқҳ м ңм–ҙ мһ…л Ҙмқ„ мӮ¬мҡ©н•ңлӢӨ[5].
Vr мҳҒм—ӯм—җм„ң м·Ён•ң v, wмқҖ DWA м•Ңкі лҰ¬мҰҳмқҳ лӘ©м Ғн•ЁмҲҳмқё мӢқ (3)м—җм„ң лҢҖмһ…лҗҳм–ҙ лӘ©м Ғн•ЁмҲҳ G(v,w)к°Җ мөңлҢҖк°Җ лҗҳлҠ” v, w мҢҚмқ„ м„ л°•мқҳ лӘ©н‘ң м„ мҶҚлҸ„мҷҖ к°ҒмҶҚлҸ„лЎң кІ°м •н•ңлӢӨ.
headingкіј clearance, velocityн•ӯмқҖ м„ л°•мқҳ л°©н–Ҙ, 충лҸҢ л°Ҹ мҶҚлҸ„м—җ кҙҖл Ёлҗң н•ЁмҲҳмқҙкі Оұ, ОІ, ОілҠ” н•ҙлӢ№ н•ЁмҲҳмқҳ к°ҖмӨ‘м№ҳмқҙлӢӨ. headingмқҖ м ңм–ҙ мһ…л Ҙ мӢң м„ л°•кіј лӘ©н‘ңм җкіјмқҳ л°©н–Ҙ м°ЁмқҙлҘј лӮҳнғҖлӮҙл©°, лӘ©н‘ңм җмқ„ н–Ҙн•ҙ к°Җл ӨлҠ” м„ұм§Ҳмқ„ к°Җ진лӢӨ. clearanceлҠ” м ңм–ҙ мһ…л Ҙ мқҙнӣ„ м„ л°• мң„м№ҳм—җм„ң к°ҖмһҘ к°Җк№Ңмҡҙ мһҘм• л¬јкіјмқҳ кұ°лҰ¬лЎң мҡ°нҡҢмқҳ нҠ№м„ұмқ„ к°Җм§Җл©° velocityлҠ” м„ л°•мқҳ мөңлҢҖ мҶҚлҸ„ лҢҖ비 м ңм–ҙ мһ…л Ҙ мқҙнӣ„мқҳ мҶҚлҸ„лЎң м·Ён• мҲҳ мһҲлҠ” к°ҖмһҘ лҶ’мқҖ мҶҚлҸ„лҘј м„ нғқн•ңлӢӨ[5].
2.1 м„ л°• мҡҙлҸҷ
2.2 кІҪлЎңм„ м¶”мў…мқ„ мң„н•ң к°ңм„ лҗң DWA м•Ңкі лҰ¬мҰҳ
к°ңм„ лҗң DWAм—җм„ңлҠ” м„ л°•мқҙ 충лҸҢнҡҢн”ј мқҙнӣ„м—җлҸ„ кІҪлЎңм„ м¶”мў…мқ„ мң„н•ҙ м„ л°•мқҳ мң„м№ҳмҷҖ кІҪлЎңм„ кіјмқҳ кұ°лҰ¬лҘј нҸүк°Җн•ҳлҠ” н•ЁмҲҳ dlineмҷҖ мқҙм—җ лҢҖн•ң к°ҖмӨ‘м№ҳ ОҙлҘј 추к°Җн•ҳм—¬ м•„лһҳ мӢқ (5)мҷҖ к°ҷмқҙ м •мқҳлҗңлӢӨ[6].
м—¬кё°м„ң, kлҠ” мһҘм• л¬ј к°җм§Җ мң л¬ҙм—җ лҢҖн•ң кі„мҲҳлЎң, мһҘм• л¬ј к°җм§Җ мӢң 1, 비 к°җм§Җ мӢң 0мңјлЎң кІ°м •лҗңлӢӨ. dlineмқҖ вҲҶt мӢңк°„ нӣ„м—җ м„ л°•мқ„ кІҪлЎңм—җ к·јм ‘мӢңнӮӨлҠ” v, wмЎ°н•©мқҙ мөңкі к°Җ лҗҳкІҢ н•ҳм—¬ м„ л°•мқ„ кІҪлЎңм—җ к·јм ‘н•ҳлҸ„лЎқ мң лҸ„н•ңлӢӨ[6]. к·ёлҹ¬лӮҳ Fig. 3м—җм„ң ліҙл“Ҝмқҙ лӢЁмҲңнһҲ м„јм„ңм—җм„ң мһҘм• л¬ј к°җм§Җ мӢң kк°Җ 1мқҙ лҗҳл©ҙ dlineмқҙ мғҒмҮ„лҗҳм–ҙ, кё°мЎҙмқҳ DWA лӘ©м Ғн•ЁмҲҳмҷҖ лҸҷмқјн•ң кө¬мЎ°к°Җ лҗҳкё° л•Ңл¬ём—җ мһҘм• л¬јмқҙ л§Һкі мқҙлҸҷ к°ҖлҠҘн•ң мҳҒм—ӯмқҙ мўҒмқҖ кІҪмҡ°, кІҪлЎңм„ м¶”мў…мқҙ к°ҖлҠҘн•Ём—җлҸ„ л¶Ҳкө¬н•ҳкі нҒ¬кІҢ мҡ°нҡҢн•ҳлҠ” м§Җм—ӯ кІҪлЎңлҘј мғқм„ұн•ңлӢӨ. лҳҗн•ң 추к°Җлҗң dline н•ЁмҲҳмқҳ к°ҖмӨ‘м№ҳ мқёмһҗ Оҙм—җ лҢҖн•ҙм„ңлҸ„ м—¬м „нһҲ мӢӨн—ҳмқ„ нҶөн•ҙ к°’мқ„ м„Өм •н•ҙм•јн•ҳкё° л•Ңл¬ём—җ м§Җм—ӯ мөңм Ғнҷ”м—җ л№ м§Ҳ мҲҳ мһҲлӢӨ.

ліё л…јл¬ём—җм„ңлҠ” мһҘм• л¬јкіјмқҳ м•Ҳм „кұ°лҰ¬к°Җ нҷ•ліҙлҗң кІҪмҡ°, к°җм§Җ м—¬л¶ҖмҷҖ кҙҖкі„м—Ҷмқҙ кІҪлЎңм„ м¶”мў…мқҙ к°ҖлҠҘн•ң л°©лІ•мқ„ м ңм•Ҳн•ҳкі кё°мЎҙмқҳ нңҙлҰ¬мҠӨнӢұн•ҳкІҢ кІ°м •н–ҲлҚҳ к°ҖмӨ‘м№ҳ мқёмһҗл“Өмқ„ к°•нҷ”н•ҷмҠө кё°лІ•мқ„ нҶөн•ҙ н•ҷмҠөмӢңмјң кІҪлЎң кі„нҡҚ мӢң мөңм Ғмқҳ м„ мҶҚлҸ„мҷҖ к°ҒмҶҚлҸ„лҘј лҸ„м¶ңн•ҳкі мһҗ н•ңлӢӨ.
кІҪлЎңм„ м¶”мў…мқ„ мң„н•ң к°•нҷ”н•ҷмҠө кё°л°ҳ Dynamic Window Approach
к°ңм„ лҗң DWAм—җм„ң лӢЁмҲңнһҲ мһҘм• л¬ј к°җм§Җ м—¬л¶Җм—җ л”°лқј кІҪлЎң 추종 н•ЁмҲҳк°Җ л°ҳмҳҒлҗҳм§Җ м•ҠлҠ” л¬ём ңм җмқ„ ліҙмҷ„н•ҳкё° мң„н•ҙ мӢқ (5)мқҳ мһҘм• л¬ј к°җм§Җ мң л¬ҙ кі„мҲҳ kлҘј 충лҸҢ нҡҢн”ј м—¬л¶Җ кі„мҲҳ kлЎң ліҖкІҪн•ҳм—¬ мӢқ (6)кіј к°ҷмқҙ м •мқҳн•ҳмҳҖлӢӨ.
О»лҠ” м ңм–ҙ мһ…л Ҙ нӣ„м—җ м„ л°•мқҳ мң„м№ҳ xвҖІ, yвҖІ м—җм„ң к°ҖмһҘ к°Җк№Ңмҡҙ мһҘм• л¬јмқҳ кұ°лҰ¬к°Җ м ңлҸҷкұ°лҰ¬ dbrakeмҷҖ м•Ҳм „кұ°лҰ¬ dsafeмқҳ н•© ліҙлӢӨ мһ‘мңјл©ҙ 1, нҒ¬л©ҙ 0мқ„ л°ҳнҷҳн•ңлӢӨ. dbrakeлҠ” мӢқ (7)м—җм„ң м„ л°•мқҳ нҳ„мһ¬ м„ мҶҚлҸ„мҷҖ к°ҖмҶҚлҸ„ v, aлҘј нҶөн•ҙ к°„лӢЁнһҲ кі„мӮ°лҗҳл©° dsafeлҠ” мһҘм• л¬јмқ„ м•Ҳм „н•ҳкІҢ нҡҢн”јн•ҳкё° мң„н•ң м—¬мң к°’мқ„ лӮҳнғҖлӮёлӢӨ. мҰү, мһҘм• л¬јмқҙ к°җм§Җлҗҳм–ҙлҸ„ О»к°Җ 1мқҙ м•„лӢҢ кІҪмҡ°, кІҪлЎңм„ м¶”мў…мқҙ к°ҖлҠҘн•ҙ진лӢӨ.
мөңмў…м ҒмңјлЎң мң„ лӮҙмҡ©мқ„ м Ғмҡ©н•ң лӘ©м Ғн•ЁмҲҳ G(v,w)лҠ” мӢқ (8)кіј к°ҷмқҙ н‘ңнҳ„лҗңлӢӨ.
(8)
к°ҖмӨ‘м№ҳ мқёмһҗ Оұ, ОІ, Оі, ОҙмҷҖ м•Ҳм „кұ°лҰ¬ dsafeлҠ” к°•нҷ”н•ҷмҠөм—җ м Ғмҡ©н•ҳкё° мң„н•ҙ мӢқ (9)мҷҖ к°ҷмқҙ н•ҷмҠө нҢҢлқјлҜён„°лЎң м •мқҳн•ҳмҳҖлӢӨ. л¬ҙмқёмҲҳмғҒм •мқҖ м–ҙл– н•ң кІҪмҡ°м—җлҸ„ мһҘм• л¬јкіј 충лҸҢн•ҳм§Җ м•Ҡм•„м•јн•ҳл©°, мһҘм• л¬јмқҙ м—ҶлҠ” нҷҳкІҪм—җм„ңлҠ” мЈјм–ҙ진 кІҪлЎңм„ мқ„ 추종н•ҙм•јн•ҳкё° л•Ңл¬ём—җ л°©н–ҘмқҙлӮҳ мҶҚлҸ„ кҙҖл Ё к°ҖмӨ‘м№ҳл“Өмқҳ 비н•ҙ лҶ’мқҖ к°’мқ„ к°Җм ём•ј н•ңлӢӨ. ліё м—°кө¬м—җм„ңлҠ” к°ҖмӨ‘м№ҳ ОІ, ОілҠ” 1лЎң м§Җм •н•ҳмҳҖлӢӨ.
(9)
ліё л…јл¬ём—җм„ңлҠ” Fig. 4мҷҖ к°ҷмқҙ м ңм•Ҳлҗң DWA м•Ңкі лҰ¬мҰҳк°•нҷ”н•ҷмҠө кө¬мЎ°м—җ 추к°Җн•ҳм—¬ мӢқ (9)мқҳ к°ҖмӨ‘м№ҳ мқёмһҗлҘј н•ҷмҠөн•ҳмҳҖлӢӨ. к°•нҷ”н•ҷмҠөмқҙлһҖ мЈјм–ҙ진 нҷҳкІҪ(Environment) м—җм„ң к°қмІҙ(Agent)к°Җ нҷҳкІҪмқҳ мғҒнғң(State)лҘј мқёмӢқн•ҙ м„ нғқн•ҳлҠ” н–үлҸҷ(Action)м—җ л”°лқј ліҙмғҒ(Reward)мқ„ мөңлҢҖнҷ”н•ҳлҠ” мөңм Ғмқҳ м •мұ…мқ„ н•ҷмҠөн•ҳлҠ” л°©лІ•мқҙлӢӨ[7].
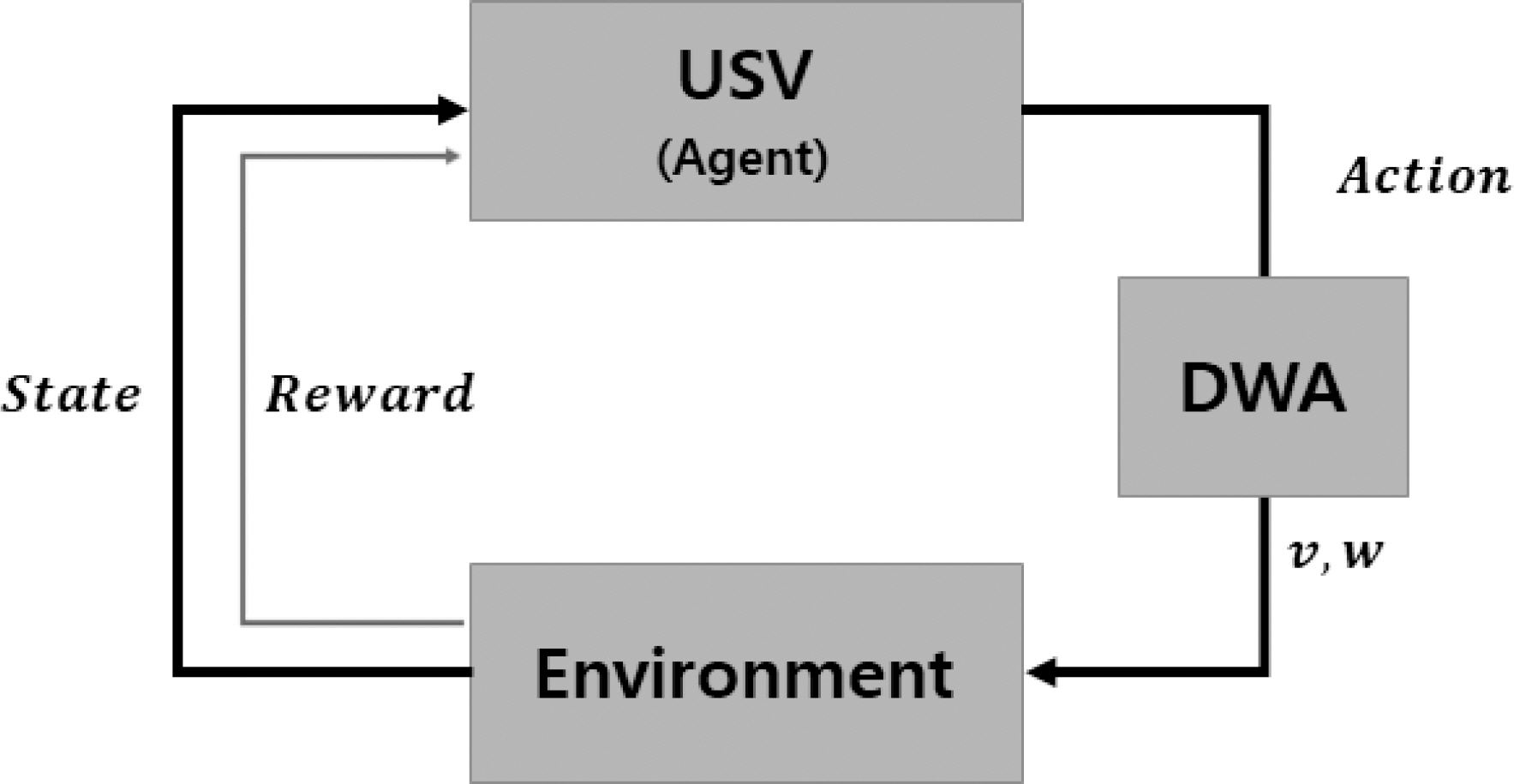
н•ҷмҠөмқ„ мҲҳн–үн•ҳкё° м „м—җ State, Action к·ёлҰ¬кі RewardлҘј м •мқҳн•ҙм•јн•ңлӢӨ. мӢқ (10)м—җм„ң StateлҠ” мғҒнғң кҙҖмёЎ к°’мқ„ мқҳлҜён•ҳл©°, мӢӨмӢңк°„ нғҗм§Җм„јм„ңлЎңл¶Җн„° мһҘм• л¬ј мң„м№ҳм—җ л”°лқј м„ё к°Җм§Җ мғҒнҷ©мқ„ м •мҲҳнҳ•нғңлЎң 분лҘҳн•ҳмҳҖлӢӨ. ActionмқҖ мӢқ (9)мқҳ к°ҖмӨ‘м№ҳ мқёмһҗлҘј мқҳлҜён•ңлӢӨ. лІЎн„° нҳ•нғңлЎң DWA лӘ©м Ғн•ЁмҲҳм—җ м „лӢ¬лҗҳм–ҙ м„ мҶҚлҸ„(v)мҷҖ к°ҒмҶҚлҸ„(w)лҘј кі„мӮ°н•ҳкі л¬ҙмқёмҲҳмғҒм •мқҳ мң„м№ҳлҘј к°ұмӢ н•ңлӢӨ.
(10)
мөңмў…м ҒмңјлЎң нҷҳкІҪмңјлЎңл¶Җн„° Table 1м—җ м •мқҳлҗң ліҙмғҒк·ңм№ҷм—җ л”°лқј RewardлҘј л°ӣлҠ”лӢӨ. м–‘мқҳ ліҙмғҒмқҖ л¬ҙмқёмҲҳмғҒм •мқҙ лӘ©н‘ңм§Җм җм—җ лҸ„м°©н•ҳкұ°лӮҳ кІҪлЎңм„ м¶”мў… мӢң м ‘к·ј нҡҹмҲҳм—җ л”°лқј мЈјм–ҙ진лӢӨ. мқҢмқҳ ліҙмғҒмқҳ кІҪмҡ°, 충лҸҢмқҙ л°ңмғқн•ҳкұ°лӮҳ мһ„л¬ҙ мҳҒм—ӯмқ„ мқҙнғҲн–Ҳмқ„ л•Ң мЈјм–ҙм§Җл©°, мӢңк°„м—җ л”° лҘё м•Ҫн•ң мқҢмқҳ ліҙмғҒмқ„ л¶Җм—¬н•ЁмңјлЎңмҚЁ 비нҡЁмңЁм Ғмқё кІҪлЎң кі„нҡҚмқ„ л°©м§Җн•ҳмҳҖлӢӨ.
TableВ 1.
Definition of rewards
| (+) Reward |
|
вҖў лӘ©н‘ңм§Җм җ лҸ„м°©: +2 вҖў кІҪлЎңм„ м ‘к·ј нҡҹмҲҳ: мҙқ нҡҹмҲҳ Г— 0.5 |
| (вҖ“) Reward |
|
вҖў мһҘм• л¬ј 충лҸҢ: вҲ’2 вҖў кІҪлЎңл§ө мқҙнғҲ: вҲ’2 вҖў мӢңк°„ мҶҢмҡ”: вҲ’0.01 (0.1мҙҲлӢ№) |
3.1 PPO м•Ңкі лҰ¬мҰҳ
ліё л…јл¬ём—җм„ң к°•нҷ”н•ҷмҠө л°©мӢқмқҖ Proximal Policy Optimization(PPO) м•Ңкі лҰ¬мҰҳмқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ. 2017л…„ OpenAI нҢҖм—җ мқҳн•ҙ лҸ„мһ…лҗң кё°лІ•мңјлЎң PPOлҠ” к°қмІҙк°Җ нҷҳкІҪкіј мғҒнҳёмһ‘мҡ©мқ„ нҶөн•ҙ лҚ°мқҙн„°лҘј мғҳн”Ңл§Ғ н•ҳлҠ” кІғкіј нҷ•лҘ м Ғ кё°мҡёкё° мғҒмҠ№мқ„ мӮ¬мҡ©н•ҙ лҢҖлҰ¬ лӘ©н‘ң н•ЁмҲҳлҘј мөңм Ғнҷ” н•ҳлҠ” кІғмқ„ л°ҳліөн•ҳм—¬ н•ҷмҠөн•ҳлҠ” кё°лІ•мқҙлӢӨ[7]. мҳӨн”Ҳ мҶҢмҠӨ н”Ңлҹ¬к·ёмқё Unity ML-AgentлҘј мӮ¬мҡ©н•ҳмҳҖмңјл©°, ML-Agent м—җм„ң мӢң뮬л Ҳмқҙм…ҳ нҷҳкІҪ л°Ҹ м—җмқҙм „нҠёлҘј м„Өкі„н•ҳл©ҙ мһҗмІҙм ҒмңјлЎң к°•нҷ”н•ҷмҠө мҲҳн–үн•ҳл©° мӢ кІҪл§қ лӘЁлҚёмқ„ мғқм„ұн•ҙмӨҖлӢӨ[8]. Fig. 5мҷҖ к°ҷмқҙ Unity3D Learning нҷҳкІҪм—җм„ң мҲҳ집лҗң ліҖмҲҳ к°’л“Өмқ„ мҷёл¶Җ н”„лЎңм„ёмҠӨлЎң м „мҶЎн•ҳкі PPO м•Ңкі лҰ¬мҰҳмңјлЎң н•ҷмҠөлҗң кІ°кіјлҘј лӢӨмӢң Unity3DлЎң м „мҶЎн•ҙмЈјл©ҙм„ң н•ҷмҠөмқҙ мҲҳн–үлҗңлӢӨ.
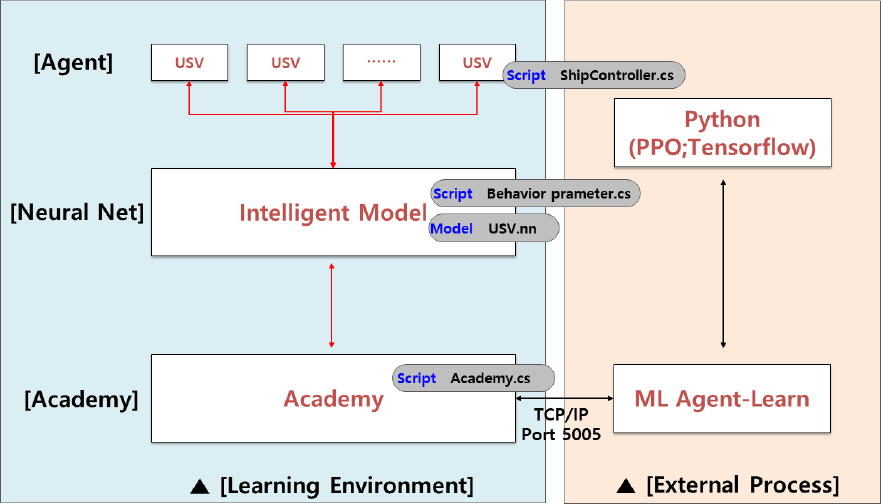
Fig. 6мқҖ PPO м•Ңкі лҰ¬мҰҳмқҳ к°„лӢЁн•ң мқҳмӮ¬мҪ”л“ңлҘј лӮҳнғҖлӮёлӢӨ. н•ҷмҠөмқҳ мЈјмІҙ actorлҠ” мӢң뮬л Ҳмқҙм…ҳ мҲҳн–ү лҸҷм•Ҳ мЈјм–ҙ진 нҷҳкІҪм—җм„ң policy ПҖОёoldм—җ л”°лқј н–үлҸҷмқ„ м·Ён•ҳкі TмӢңк°„ лҸҷ м•Ҳ мҲҳ집н•ң кІ°кіјм—җ м¶”м • ліҙмғҒмқ„ кі„мӮ°н•ңлӢӨ. м¶”м • ліҙмғҒмқ„ нҶ лҢҖлЎң policyк°Җ к°ұмӢ лҗҳл©° м„Өм •лҗң л°ҳліө нҡҹмҲҳ(iteration) лҸҷм•Ҳ мқҙлҹ¬н•ң н”„лЎңм„ёмҠӨлЎң н•ҷмҠөмқҙ мҲҳн–үлҗңлӢӨ. ліё л…јл¬ём—җм„ңлҠ” PPOм—җ кҙҖн•ң лӮҙмҡ©мқҖ к°„лӢЁн•ң мқҳмӮ¬мҪ”л“ңл§Ң м–ёкёүн•ҳкі м°ёкі л¬ён—ҢмңјлЎң лҢҖмІҙн•ңлӢӨ[9].

3.2 н•ҷмҠө мҲҳн–ү
Unity3D ML-Agent н”Ңлҹ¬к·ёмқёмқ„ мӮ¬мҡ©н•ҳкё° мң„н•ҙ лҸҷмқјн•ң нҷҳкІҪм—җм„ң мӢң뮬л Ҳмқҙн„°лҘј кө¬нҳ„н•ҳмҳҖлӢӨ. Fig. 7кіј к°ҷмқҙ н•ҷмҠөнҡЁкіјлҘј лҶ’мқҙкі н•ҷмҠөмӢңк°„мқ„ мӨ„мқҙкё° мң„н•ҙ лӢӨм–‘н•ҳкІҢ нҷҳкІҪмқ„ кө¬м„ұн•ҳмҳҖлӢӨ. м—¬кё°м„ң мһҘм• л¬ј к°җм§Җ лІ”мң„лҠ” л°ҳкІҪ 200 m, мӢңм•ј к°Ғ(Field Of View) Вұ60В°лЎң м„Өм •н•ҳмҳҖкі кІҪлЎңл§өмқҳ нҒ¬кё°лҠ” 1000 m Г— 1000 mлЎң кІ©мһҗ н•ң м№ёмқҖ 100 mмқҙлӢӨ.

н•ҷмҠөмқҖ мҙқ 30000лІҲ, н•ҷмҠөлҘ 0.003мңјлЎң мҲҳн–үлҗҳм—Ҳмңјл©° н•ҷмҠө мҶҚлҸ„ н–ҘмғҒмқ„ мң„н•ҙ мӢқ (9)мқҳ мқёмһҗ лІ”мң„лҘј 0.1, 0.2, 0.3кіј к°ҷмқҙ мқҙмӮ° к°’мңјлЎң м§Җм •н•ҳмҳҖлӢӨ. м•„лһҳ Fig 8м—җм„ң ліҙл“Ҝмқҙ н•ҷмҠөмқҙ 진н–үлҗЁм—җ л”°лқј лҲ„м Ғ ліҙмғҒмқҳ мҰқк°ҖмҷҖ мҶҗмӢӨ н•ЁмҲҳмқҳ к°җмҶҢн•ҳлҠ” к·ёлһҳн”„лҘј нҶөн•ҙ н•ҷмҠөмқҙ мһҳ мҲҳн–үлҗҳм—ҲмқҢмқ„ нҷ•мқён•ҳмҳҖлӢӨ. н•ҷмҠөмқҙ 진н–үлҗҳлҠ” лҸҷм•Ҳ лӢӨм–‘н•ң нҷҳкІҪмқ„ кө¬м„ұн•ң кІғмқҖ мӢқ (9)мқҳ лӘ©м Ғн•ЁмҲҳлҘј кө¬м„ұн•ҳлҠ” к°ҖмӨ‘м№ҳ кі„мҲҳ к°’мқҙ кі м •лҗҳм§Җ м•Ҡкі мғҒнҷ©м—җ л”°лқј мң м—°н•ң к°’мқ„ к°Җм§ҖлҸ„лЎқ мң лҸ„н•ҳмҳҖлӢӨ.

мӢң뮬л Ҳмқҙм…ҳ мҲҳн–ү
ліё л…јл¬ём—җм„ң м ңм•Ҳлҗң к°•нҷ”н•ҷмҠө кё°л°ҳ DWA м•Ңкі лҰ¬мҰҳкіј кё°мЎҙмқҳ DWAм•Ңкі лҰ¬мҰҳмқ„ 비көҗ кІҖмҰқн•ҳкё° мң„н•ҙ Unity3Dкё°л°ҳ мӢң뮬л Ҳмқҙн„°лҘј к°ңл°ңн•ҳмҳҖлӢӨ. ліё мӢң뮬л Ҳмқҙн„°лҠ” кІҪлЎң мғқм„ұ м•Ңкі лҰ¬мҰҳ кІҖмҰқ мҲҳн–үмқ„ мң„н•ң кІғмңјлЎң н•ҙмғҒнҷҳкІҪкіј м„ мІҙ кұ°лҸҷмқҖ кі л Өн•ҳм§Җ м•Ҡкі мғқм„ұ кІҪлЎңлҘј м„ л°•мқҙ мҷ„м „нһҲ 추종н•ңлӢӨлҠ” к°Җм • н•ҳм—җ лӘЁмқҳлҘј 진н–үн•ҳмҳҖлӢӨ. кІҪлЎңм„ мқҖ мЈјнҷ©мғү м җм„ , мқҙлҸҷ к¶Өм ҒмқҖ мӢӨм„ мңјлЎң н‘ңмӢңн•ҳмҳҖкі лӘЁл“ кі м • мһҘм• л¬јмқҖ нҡҢмғүмңјлЎң н‘ңмӢңн•ҳмҳҖлӢӨ. м—¬кё°м„ң кё°мЎҙмқҳ м•Ңкі лҰ¬мҰҳ DWAмҷҖ к°ңм„ лҗң DWAлҠ” нҺёмқҳмғҒ Method A, Method BлЎң н‘ңкё°н•ҳмҳҖлӢӨ.
비көҗ кІҖмҰқ мӢң м•Ңкі лҰ¬мҰҳ нҠ№м„ұмқ„ лӢ¬лҰ¬н•ҳкё° мң„н•ҙ к°ңм„ лҗң DWA(2017)м—җм„ң мӮ¬мҡ©лҗң к°ҖмӨ‘м№ҳ 비мңЁ мқҙмҷём—җ 추к°ҖлЎң мӢқ (5)мқҳ л°©н–Ҙ кҙҖл Ё к°ҖмӨ‘м№ҳ Оұк°’мқ„ лӢӨлҘҙкІҢ м„Өм •н•ҳм—¬ Method B вҖ“ 1, 2лЎң м•„лһҳмҷҖ к°ҷмқҙ м„Өм •н•ҳмҳҖлӢӨ.
лЁјм Җ мӢң뮬л Ҳмқҙн„° кө¬лҸҷ м–‘мғҒмқ„ нҷ•мқён•ҳкё° мң„н•ҙ Method A, B м•Ңкі лҰ¬мҰҳмқ„ кө¬нҳ„н•ҳкі мһҘм• л¬ј нҡҢн”јмҷҖ кІҪлЎң추종 кё°лҠҘмқ„ Fig. 9мҷҖ к°ҷмқҙ мӢң뮬л Ҳмқҙм…ҳ мғҒм—җм„ң нҷ•мқён•ҳмҳҖлӢӨ. кё°мЎҙмқҳ л°©мӢқ Method AмҷҖ лӢ¬лҰ¬ кІҪлЎңм„ м¶”мў…мқ„ кі л Өн•ң Method BлҠ” мһҘм• л¬ј нҡҢн”ј мқҙнӣ„ лӢӨмӢң кІҪлЎңм„ мңјлЎң ліөк·Җн•ҳм—¬ ліё мӢң뮬л Ҳмқҙн„°к°Җ мһҳ лҸҷмһ‘н•Ёмқ„ нҷ•мқён•ҳмҳҖлӢӨ.

ліё м—°кө¬м—җм„ң м ңм•Ҳн•ң к°•нҷ”н•ҷмҠө кё°л°ҳ DWA м•Ңкі лҰ¬мҰҳкіј Method B вҖ“ 1, 2мқҳ 비көҗ кІҖмҰқмқ„ мң„н•ҙ кІҪлЎңм„ мғҒ мһҘм• л¬ј Obs-1мҷҖ ліөк·Җ кІҪлЎңм—җ мқём ‘н•ң Obs-2лҘј нҡҢн”јн•ҳлҠ” к°„лӢЁн•ң мӢңлӮҳлҰ¬мҳӨ AмҷҖ 2к°ң мқҙмғҒ кІҪлЎңм җ 추종 мӢң лӢӨмҲҳмқҳ мһҘм• л¬јмқҙ кІҪлЎңм„ мғҒм—җ мң„м№ҳн•ң ліөмһЎн•ң мғҒнҷ©мқҳ мӢңлӮҳлҰ¬мҳӨ BлҘј м„Өм •н•ҳмҳҖлӢӨ.
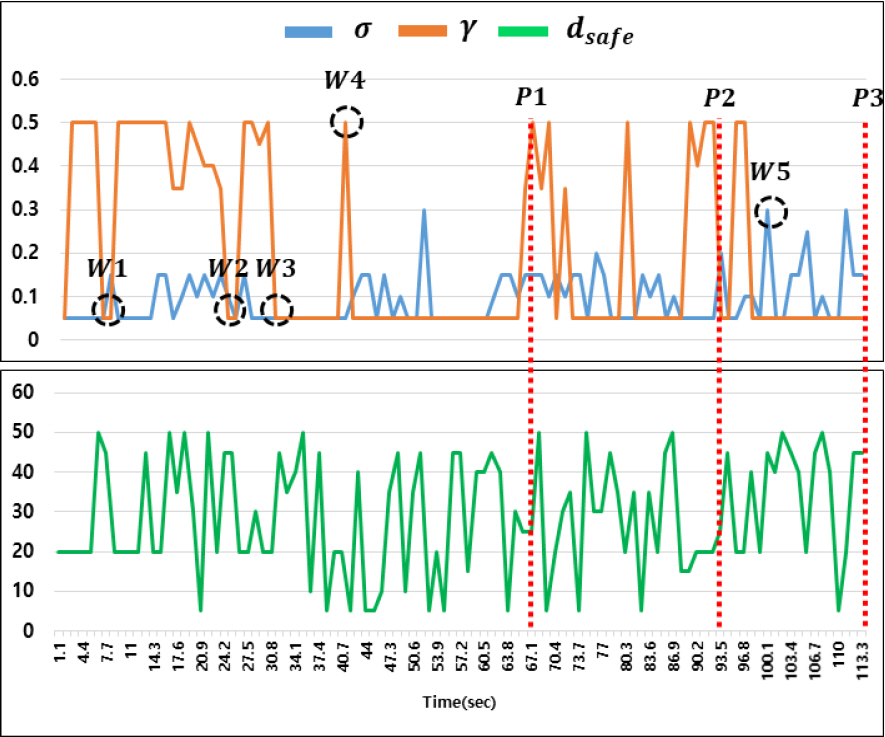
Fig. 10, 11мқҖ мӢңлӮҳлҰ¬мҳӨ A, Bм—җ лҢҖн•ң мӢң뮬л Ҳмқҙм…ҳ кІ°кіјлҘј лӮҳнғҖлӮҙкі Fig. 12, 13мқҖ мқҙлҸҷ к¶Өм Ғкіј кІҪлЎңм„ к°„мқҳ мқјм№ҳ м •лҸ„лҘј лӮҳнғҖлӮҙлҠ” к·ёлһҳн”„лЎң ліё л…јл¬ём—җм„ңлҠ” кІҪлЎң л¶Ҳмқјм№ҳм„ұ(PI, Path-Inconsistency)мқҙлқј м •мқҳн•ҳмҳҖлӢӨ. PI лҠ” мқјм •кө¬к°„ л§ҲлӢӨ мқҙлҸҷ к¶Өм Ғкіј кІҪлЎңм„ мқҳ л–Ём–ҙ진 мҲҳм§Ғкұ°лҰ¬лҘј кІҪлЎңл§ө л°ҳкІҪ(500 m)мңјлЎң лӮҳлҲҲ к°’мңјлЎң л–Ём–ҙ진 кұ°лҰ¬к°Җ нҒ¬л©ҙ нҒҙмҲҳлЎқ 1м—җ к°Җк№ҢмӣҢм§Җкі к°Җк№ҢмҡёмҲҳлЎқ 0м—җ к°Җк№Ңмҡҙ к°’мқ„ к°Җ진лӢӨ. лӘЁл“ PIмқҳ н•©мқ„ кІҪлЎң кө¬к°„мңјлЎң лӮҳлҲҲ нҸүк· PIлҘј кІҪлЎңм„ м¶”мў… м§Җн‘ңлЎң мӮ¬мҡ©н•ҳмҳҖмңјл©°, мғҒлҢҖм ҒмңјлЎң лӮ®мқҖ к°’мқҙ кІҪлЎңм„ мқ„ мһҳ 추종н–ҲлӢӨкі н•ҙм„қн• мҲҳ мһҲлӢӨ. Table 2лҠ” мӢңлӮҳлҰ¬мҳӨ A, Bм—җм„ң к°Ғ м•Ңкі лҰ¬мҰҳм—җ лҢҖн•ң нҸүк· PIмҷҖ мҶҢмҡ”мӢңк°„мқ„ лӮҳнғҖлӮёлӢӨ.
TableВ 2.
Results of scenario A, B
| Method | Path-Inconsistency | Arrival Time | ||
|---|---|---|---|---|
| A | B | A | B | |
| Method B вҖ“ 1 | 0.338 | 0.160 | 61.5s | 130s |
| Method B вҖ“ 2 | 0.159 | 0.063 | 88.5s | 177s |
| Ours | 0.141 | 0.061 | 47.5s | 114s |
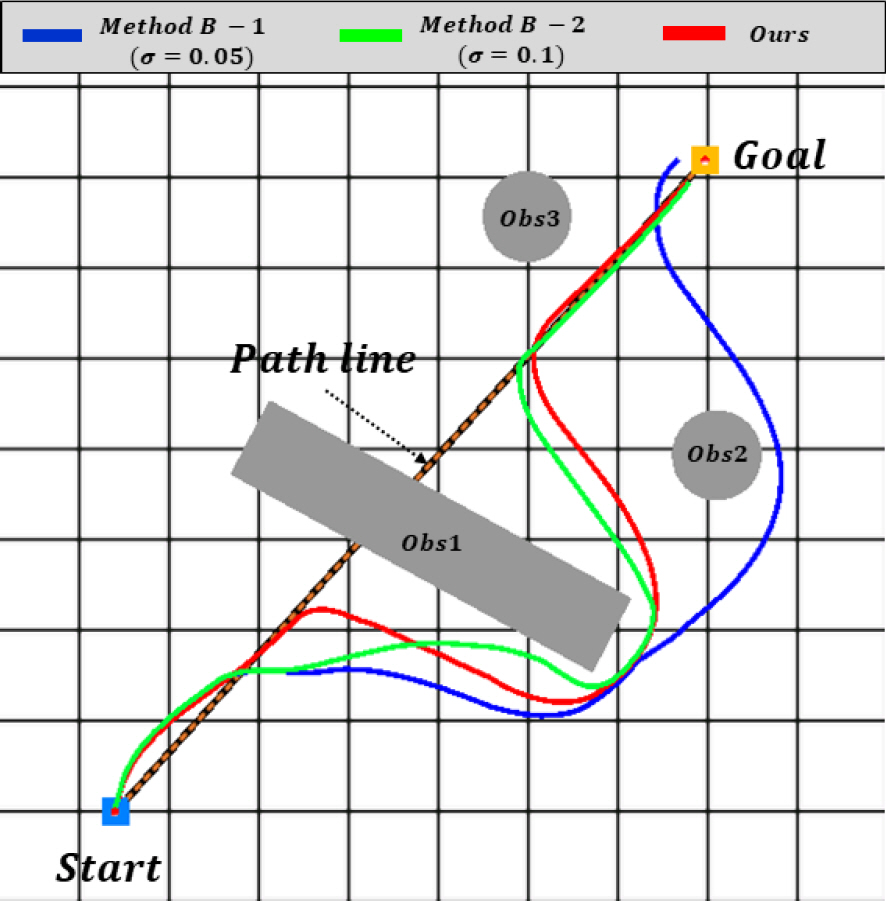


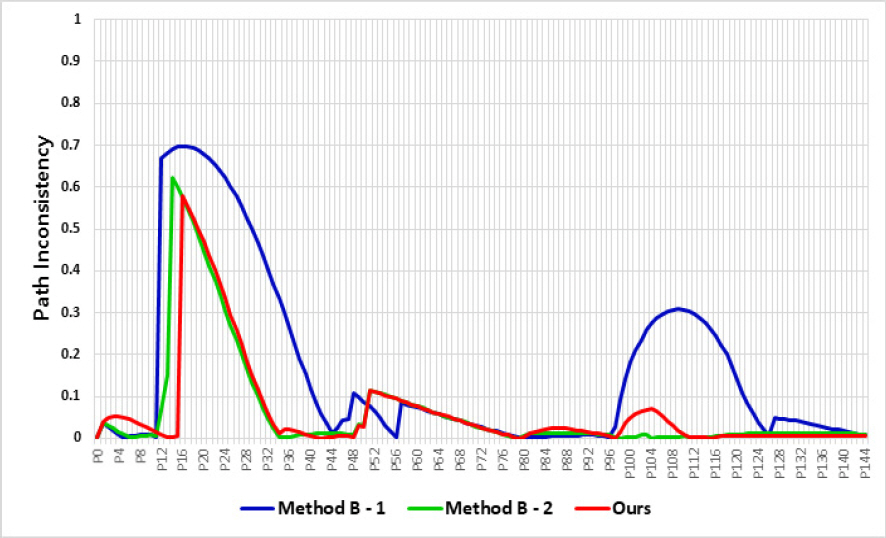
Table 2м—җм„ң ліҙл“Ҝмқҙ мӢңлӮҳлҰ¬мҳӨ Aм—җм„ң м ңм•Ҳлҗң м•Ңкі лҰ¬мҰҳмқҙ нҸүк· PI 0.141, мҶҢмҡ”мӢңк°„ 47.5мҙҲлЎң Method B вҖ“ 1, 2м—җ 비н•ҙ л№ лҘё мқҙлҸҷмҶҚлҸ„мҷҖ м •нҷ•н•ң кІҪлЎң 추종мқ„ лӮҳнғҖлғҲлӢӨ. л§Ҳм°¬к°Җм§ҖлЎң кІҪлЎңм җмқҙ л§ҺмқҖ мӢңлӮҳлҰ¬мҳӨ Bм—җм„ңлҸ„ Method B вҖ“ 2мҷҖ мң мӮ¬н•ң кІҪлЎң 추종결과лҘј ліҙмҳҖм§Җл§Ң мҶҢмҡ”мӢңк°„ 114мҙҲлЎң мӣ”л“ұн•ң м„ұлҠҘмқ„ лӮҳнғҖлӮё кІғмқ„ нҷ•мқён•ҳмҳҖлӢӨ.
мӢң뮬л Ҳмқҙм…ҳ 결과분м„қ
DWA м•Ңкі лҰ¬мҰҳмқҖ лӘ©м Ғн•ЁмҲҳмқҳ к°ҖмӨ‘м№ҳ к°’м—җ л”°лқј мҡҙлҸҷнҠ№м„ұмқҙ лӢ¬лқјм§„лӢӨ. Fig. 10, 11м—җм„ң Method B вҖ“ 1мқҖ мҶҚлҸ„ к°ҖмӨ‘м№ҳ(Оі)к°Җ л°©н–Ҙ к°ҖмӨ‘м№ҳ(Оұ)ліҙлӢӨ лҶ’м•„ м—җм„ң ліҙл“Ҝмқҙ мһҘм• л¬ј Obs1 нҡҢн”ј нӣ„ к°җмҶҚн•ҳм—¬ кІҪлЎңм„ л°©н–ҘмңјлЎң 진мһ…н•ҳм§Җ лӘ»н•ҳкі л№ лҘё мҶҚлҸ„лЎң мһҘм• л¬ј Obs2лҘј нҒ¬кІҢ мҡ°нҡҢн•ҳлҠ” кІ°кіјлҘј лӮҳнғҖлғҲлӢӨ. лҳҗн•ң кІҪлЎңм җ P1 нҶөкіј мӢң л¶Җм •нҷ•н•ң л°©н–Ҙм„ұмқ„ ліҙмҳҖлӢӨ. л°ҳл©ҙм—җ Method B вҖ“ 2лҠ” ліё л…јл¬ём—җм„ң м ңм•Ҳлҗң м•Ңкі лҰ¬мҰҳкіј мң мӮ¬н•ң кІҪлЎң 추종мқ„ ліҙмҳҖмңјлӮҳ мһҘм• л¬јмқҙ м—ҶлҠ” кө¬к°„м—җлҸ„ л°©н–Ҙкіј мҶҚлҸ„м—җ лҢҖн•ң к°Җм№ҳлҘј лҸҷмқјн•ҳкІҢ кі л Өн•ҳкё° л•Ңл¬ём—җ лӘЁл“ мӢңлӮҳлҰ¬мҳӨм—җм„ң к°ҖмһҘ лҠҗлҰ° кІ°кіјлҘј лӮҳнғҖлғҲлӢӨ.
мқҙмІҳлҹј DWA лӘ©м Ғн•ЁмҲҳм—җм„ң кі м •лҗң к°ҖмӨ‘м№ҳ мқёмһҗлҘј к°–лҠ” кІҪмҡ°, лӢӨм–‘н•ң мғҒнҷ©м—җм„ң мөңм Ғ кІҪлЎңлҘј кі„нҡҚн•ҳкё° м–ҙл өлӢӨ. л”°лқјм„ң мһҘм• л¬ј нғҗм§Җ мЎ°кұҙм—җ л”°лқј мөңм Ғмқҳ к°ҖмӨ‘м№ҳлҘј DWA лӘ©м Ғн•ЁмҲҳм—җ м Ғмҡ©н•ңлӢӨл©ҙ нҡЁмңЁм Ғмқё кІҪлЎңкі„нҡҚмқҙ к°ҖлҠҘн•ҳлӢӨ. ліё л…јл¬ём—җм„ңлҠ” к°•нҷ”н•ҷмҠөмқ„ нҶөн•ҙ мқҙлҹ¬н•ң л¬ём ңм җмқ„ н•ҙкІ°н–Ҳмңјл©° мӢңлӮҳлҰ¬мҳӨ Bм—җм„ң мһҘм• л¬ј нғҗм§Җ мЎ°кұҙм—җ л”°лқј к°ҖмӨ‘м№ҳ мқёмһҗ к°’мқҙ ліҖнҷ”н•ҳлҠ” кІғмқ„ Fig. 14м—җм„ң нҷ•мқё н• мҲҳ мһҲлӢӨ. Fig. 11мқҳ W1вҲј5 мң„м№ҳм—җм„ң к°ҖмӨ‘м№ҳ к°’мқ„ ліҙл©ҙ л°©н–Ҙ м „нҷҳ мӢң мҶҚлҸ„ к°ҖмӨ‘м№ҳ(Оі)к°Җ мөңмҶҹк°’мқ„ к°Җм§Җкі м§Ғм„ кІҪлЎңм—җм„ңлҠ” мөңлҢ“к°’мқ„ к°Җм§ҖлҠ” кІғмқ„ нҷ•мқён• мҲҳ мһҲлӢӨ. лҳҗн•ң мҶҚлҸ„ к°ҖмӨ‘м№ҳ(Оі)к°Җ мһ‘мқҖ к°’мқ„ к°Җм§Ҳ л•Ң м•Ҳм „кұ°лҰ¬ dsafeмқҳ к°’мқҙ лҢҖмІҙм ҒмңјлЎң нҒ° к°’мқ„ к°Җм§ҖлҠ” кІғмңјлЎң ліҙм•„ мһҘм• л¬јмқҙ мқём ‘н•ң кө¬к°„мһ„мқ„ мң м¶”н• мҲҳ мһҲлӢӨ.
кІ° лЎ
л¬ҙмқёмҲҳмғҒм •мқҖ мң мӮ¬мӢң мһҘм• л¬ј 충лҸҢ нҡҢн”јлҠ” л¬јлЎ нҠ№м • кІҪлЎңм„ мқ„ л”°лқј м •м°° к°җмӢңлҘј мҲҳн–үн• мҲҳ мһҲлҠ” м§Җм—ӯ кІҪлЎңкі„нҡҚ кё°лҠҘмқҙ н•„мҡ”н•ҳлӢӨ. Dynamic Window Approach (DWA) м•Ңкі лҰ¬мҰҳмқҖ мқҙлҸҷмІҙмқҳ лҸҷм ҒмғҒнғңлҘј л°ҳмҳҒн•ҳлҠ” м§Җм—ӯ кІҪлЎңкі„нҡҚ кё°лІ•мңјлЎң лӘ©н‘ңм§Җм җм—җ лҢҖн•ң л°©н–Ҙ, мҶҚлҸ„, мһҘм• л¬јкіјмқҳ кұ°лҰ¬лҘј нҶ лҢҖлЎң мөңм Ғмқҳ мҶҚлҸ„мҷҖ к°ҒмҶҚлҸ„лҘј лҸ„м¶ң н• мҲҳ мһҲлӢӨ. н•ҳм§Җл§Ң DWA м•Ңкі лҰ¬мҰҳ нҠ№м„ұмғҒ лӘ©м Ғн•ЁмҲҳмқҳ к°ҖмӨ‘м№ҳлҘј нңҙлҰ¬мҠӨнӢұн•ҳкІҢ кІ°м •н•ҙм•јн•ҳкё° л•Ңл¬ём—җ 비көҗм Ғ мўҒмқҖ мһҘм• л¬ј мӮ¬мқҙлҘј нҶөкіјн•ҳкұ°лӮҳ мһҘм• л¬јмқ„ нҒ° л°ҳкІҪмңјлЎң мҡ°нҡҢн•ҳлҠ” кІҪмҡ° л“ұ лӘЁл“ мғҒнҷ©м—җ лҢҖн•ҙ м Ғм Ҳн•ң мөңм Ғмқҳ к°ҖмӨ‘м№ҳлҘј л°ҳмҳҒн•ҳкё° м–ҙл өлӢӨ. л”°лқјм„ң ліё л…јл¬ём—җм„ңлҠ” к°•нҷ”н•ҷмҠөмқ„ нҶөн•ң DWA м•Ңкі лҰ¬мҰҳмқ„ м ңм•Ҳн•ҳмҳҖкі лӢӨм–‘н•ң мһҘм• л¬ј нғҗм§Җ мЎ°кұҙм—җ л”°лқј м Ғм Ҳн•ң к°ҖмӨ‘м№ҳ мқёмһҗлҘј кІ°м •н•ҳм—¬ нҡЁмңЁм Ғмқё кІҪлЎңм„ м¶”мў…мқҙ к°ҖлҠҘн•Ёмқ„ нҷ•мқён•ҳмҳҖлӢӨ. к·ёлҹ¬лӮҳ кі м • мһҘм• л¬јм—җ лҢҖн•ң 충лҸҢ нҡҢн”јл§Ң кі л Өн–Ҳкё° л•Ңл¬ём—җ лҸҷм Ғ нҷҳкІҪм—җм„ңлҠ” м Ғмҡ©мқҙ м–ҙл Өмҡ°л©° DWA м•Ңкі лҰ¬мҰҳ нҠ№м„ұмғҒ 충лҸҢм—җ лҢҖн•ң нҡҢн”јк°Җ к°ҖмһҘ нҒ° л¶Җ분мқ„ м°Ём§Җн•ҳкё° л•Ңл¬ём—җ нҡҢн”ј кІҪлЎңк°Җ м „м—ӯ мөңм ҒкІҪлЎңмқём§Җ нҷ•мқёмқҙ н•„мҡ”н•ҳлӢӨ. л”°лқјм„ң н–Ҙнӣ„ мқҙлҹ¬н•ң л¬ём ңлҘј н•ҙкІ°н•ҳкё° мң„н•ң 추к°Җ м—°кө¬лҘј 진н–үн•ҳм—¬ ліё л…јл¬ём—җм„ң м ңм•Ҳн•ң к°•нҷ”н•ҷмҠө кё°л°ҳ DWA м•Ңкі лҰ¬мҰҳмқҳ нҡЁмҡ©м„ұмқ„ м ңкі мӢңнӮӨкі мһҗ н•ңлӢӨ.




