



ņä£ ļĪĀ
ņןĻ▒░ļ”¼ ļ¼┤ĻĖ░ņŚÉ ļīĆĒĢ£ Ļ░£ļ░£ņŚÉ ļö░ļźĖ ļĀłņØ┤ļŹö ĻĖ░ņłĀņØś ļ░£ņĀäņØĆ ĒāÉņ¦Ć ļ░Å ņČöņĀüņØś ļ▓öņ£äļź╝ ņ”ØĻ░Ćņŗ£ĒéżĻ│Ā ņ׳ņ£╝ļ®░, ņØ┤ņŚÉ ļö░ļØ╝ ņ×æņØĆ RCSļź╝ Ļ░¢ļŖö Ēæ£ņĀüņØä ņןĻ▒░ļ”¼ņŚÉņä£ ļ╣Āļź┤Ļ│Ā ņĀĢĒÖĢĒ׳ ĒāÉņ¦Ć ļ░Å ņČöņĀüĒĢśĻĖ░ ņ£äĒĢ£ ĻĖ░ņłĀņØś ĒĢäņÜöņä▒ņØ┤ ļīĆļæÉļÉśņŚłļŗż. ļé«ņØĆ ņŗĀĒśĖ ļīĆ ņ×ĪņØī ļ╣ä ĒÖśĻ▓ĮņŚÉņä£ Ēæ£ņĀüņØĆ ņŗĀĒśĖņĀüņ£╝ļĪ£ Ēü┤ļ¤¼Ēä░ņÖĆ ĻĄ¼ļ│äļÉĀ ņłś ņ׳ļŖö Ļ░ĢĒĢ£ ņŗĀĒśĖņäĖĻĖ░ļź╝ Ļ░¢ņ¦Ć ļ¬╗ĒĢ£ļŗż. ņØ┤ļĢī ņØ╝ļ░śņĀüņØĖ ļĀłņØ┤ļŹö ņŗĀĒśĖņ▓śļ”¼ļź╝ ņłśĒ¢ēĒĢĀ Ļ▓ĮņÜ░, ļ¦ż ņĖĪņĀĢņŻ╝ĻĖ░ļ¦łļŗż Ēæ£ņĀüņØś ņŗĀĒśĖĻ░Ć Ļ▓ĆņČ£ ļÉ£ļŗżļŖö ļ│┤ņןņØ┤ ņŚåņ¢┤ ļé«ņØĆ ĒāÉņ¦ĆĒÖĢļźĀņØä Ļ░¢Ļ▓ī ļÉ£ļŗż[1].
ņØ┤ļ¤¼ĒĢ£ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ£ TBD ņĢīĻ│Āļ”¼ņ”śņØĆ ņØ╝ļ░śņĀüņØĖ ņČöņĀü ņĢīĻ│Āļ”¼ņ”śĻ│╝ ļŗ¼ļ”¼ ņŗĀĒśĖņäĖĻĖ░ ļ¼ĖĒä▒ņ╣śļź╝ ņØ┤ņÜ®ĒĢ£ ņĖĪņĀĢņ╣ś ņäĀļ│äĻ│╝ņĀĢņØä Ļ▒░ņ╣śņ¦Ć ņĢŖņØĆ ņä╝ņä£ ļŹ░ņØ┤Ēä░ļź╝ ņé¼ņÜ®ĒĢ£ļŗż. TBD ņĢīĻ│Āļ”¼ņ”śņØĆ Ēæ£ņĀü ĒāÉņ¦ĆņÖĆ ņČöņĀüņØ┤ ļÅÖņŗ£ņŚÉ ņØ┤ļŻ©ņ¢┤ņ¦Ćļ®░ Ļ│ĄĻ░äņĀĢļ│┤ņÖĆ ņŗ£Ļ░äņĀü ņāüĻ┤ĆņØä ņĄ£ļīĆĒĢ£ ĒÖ£ņÜ®ĒĢśņŚ¼ ļé«ņØĆ SNR Ēæ£ņĀüņØś ĒāÉņ¦Ć Ļ░ĆļŖźņä▒ņØä Ē¢źņāüņŗ£Ēé©ļŗż. ņ”ē, ņŚ¼ļ¤¼ ņŚ░ņåŹ ĒöäļĀłņ×äņØä ļÅÖņŗ£ņŚÉ ņ▓śļ”¼ĒĢśņŚ¼ Ēæ£ņĀüņØä ņČöņĀüĒĢśļ®░ ļé«ņØĆ SNR Ēæ£ņĀü ĒÖśĻ▓ĮņŚÉņä£ņØś ĒāÉņ¦Ć ļ░Å ņČöņĀü ņä▒ļŖźņØ┤ ņÜ░ņłśĒĢśļŗż.
ļīĆĒæ£ņĀüņØĖ TBD ĻĖ░ļ▓Ģņ£╝ļĪ£ļŖö velocity filtering ĻĖ░ļ░śņØś VF-TBD[2], dynamic programming ĻĖ░ļ░śņØś DP-TBD[3], particle filtering ĻĖ░ļ░śņØś PF-TBD[4]Ļ░Ć ņĪ┤ņ×¼ĒĢ£ļŗż.
VF-TBDņÖĆ DP-TBDļŖö ļæÉ Ļ░£ņØś ļŗżņżæ ĒöäļĀłņ×ä ņØ╝Ļ┤äņ▓śļ”¼ ĻĖ░ļ░ś ļ░®ļ▓Ģņ£╝ļĪ£, ļīĆņāüņØś SNRņØä Ē¢źņāüņŗ£ĒéżĻĖ░ ņ£äĒĢ┤ ņŚ¼ļ¤¼ ņŚ░ņåŹ ĒöäļĀłņ×äņŚÉ Ļ▒Ėņ│É ļīĆņāüņØś ņŚÉļäłņ¦Ćļź╝ ĒåĄĒĢ®ņŗ£Ēé©ļŗż. PF-TBDļŖö ļÅÖņĀü ņŗ£ņŖżĒģ£ņŚÉņä£ ļ¬¼Ēģīņ╣╝ļĪ£ ĻĖ░ļ▓ĢņØä Ļ░äļŗ©ĒĢśĻ▓ī ĻĄ¼ĒśäĒĢ£ ĻĖ░ļ▓ĢņØ┤ļŗż. PF-TBDļŖö ņĢīĻ│Āļ”¼ņ”ś ņä▒ļŖźņØä Ē¢źņāüņŗ£ĒéżĻĖ░ ņ£äĒĢ┤ ļ¦ÄņØĆ ĒīīĒŗ░Ēü┤ļōżņØ┤ ĒĢäņÜöĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņŚ░ņé░ ļ╣äņÜ®ņØ┤ Ēü¼ļŗżļŖö ļŗ©ņĀÉņØ┤ ņ׳ļŗż.
ņØ╝ļ░śņĀüņ£╝ļĪ£ Ēæ£ņĀüņČöņĀüņØĆ Ēæ£ņĀüņØś ļ░£ņāØ ņŗ£Ļ░äĻ│╝ Ļ░£ņłśļź╝ ņĢī ņłś ņŚåļŖö ļŗżņłśņØś Ēæ£ņĀüļōżĻ│╝ Ēü┤ļ¤¼Ēä░(Ļ▒░ņ¦ōĒæ£ņĀü)Ļ░Ć ņĪ┤ņ×¼ĒĢśļŖö ņāüĒÖ®ņŚÉņä£ ņłśĒ¢ēļÉ£ļŗż. ņØ┤ļŖö ļīĆņāü Ēæ£ņĀüļōżņØś ņĪ┤ņ×¼ņ£Āļ¼┤ņÖĆ ĻĘĖ Ēæ£ņĀüļōżņØś ĻČżņĀüĻ│╝ Ļ┤ĆļĀ©ļÉ£ ĒīīļØ╝ļ»ĖĒä░ļōżņØä ļ»Ėļ”¼ ņĢī ņłś ņŚåļŖö ĒÖśĻ▓ĮņŚÉņä£ Ēæ£ņĀüņČöņĀüņØ┤ ņØ┤ļŻ©ņ¢┤ņ¦ĆĻ▓ī ļÉ©ņØä ļéśĒāĆļéĖļŗż. ļö░ļØ╝ņä£ Ēæ£ņĀüņČöņĀüņØä ņ£äĒĢ┤ņä£ļŖö ņ¢┤ļ¢ż ņĖĪņĀĢņ╣śĻ░Ć Ēæ£ņĀüņØś ņĖĪņĀĢņ╣śņØĖņ¦Ćļź╝ ĒīÉļ│äĒĢśĻ│Ā ĒīÉļ│äļÉ£ ņĖĪņĀĢņ╣śļĪ£ ņČöņĀüĒĢäĒä░ļź╝ ņćäņŗĀĒĢśļŖö ņ×ÉļŻīĻ▓░ĒĢ®ĻĖ░ļ▓ĢĻ│╝ ĒŖĖļ×ÖņØä ņ┤łĻĖ░ĒÖöĒĢśĻ│Ā ĒŖĖļ×ÖņØś ļ▓łĒśĖņÖĆ ņĀÉņłśļź╝ ļČĆņŚ¼ĒĢśņŚ¼ ĒŖĖļ×ÖņØä ĒīÉļ│äĒĢśļŖö ĒŖĖļ×ÖĻ┤Ćļ”¼ ĻĖ░ņłĀņØ┤ ĒĢäņłśņĀüņØ┤ļŗż.
Ēü┤ļ¤¼Ēä░Ļ░Ć ņĪ┤ņ×¼ĒĢśĻ│Ā ļŗżņłśņØś Ēæ£ņĀüņØ┤ ĻĘ╝ņĀæĒĢ£ ņāüĒÖ®ņŚÉņä£ ņ×ÉļÅÖņĀüņ£╝ļĪ£ ĒŖĖļ×ÖņØä ņāØņä▒ĒĢśĻ│Ā Ļ┤Ćļ”¼ĒĢĀ ņłś ņ׳ļŖö ļ│┤ĒÄĖņĀüņØĖ ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ļŖö IPDA(Integrated Probabilistic Data Association)[5]ņÖĆ JIPDA(Joint IPDA)[6]Ļ░Ć ņ׳ļŗż. Ļ░ü ņĢīĻ│Āļ”¼ņ”śņØś ŌĆśIŌĆÖļŖö IntegratedņØś ņĢĮņ¢┤ļĪ£ ņ×ÉļŻīĻ▓░ĒĢ®ņØä ņłśĒ¢ēĒĢśļ®┤ņä£ Ēæ£ņĀüņØś ņĪ┤ņ×¼ĒÖĢļźĀņØä ņé░ņČ£ĒĢśļŖö ņĢīĻ│Āļ”¼ņ”śņØä ņØśļ»ĖĒĢ£ļŗż. Ēæ£ņĀüņØś ņĪ┤ņ×¼ĒÖĢļźĀņØ┤ļ×Ć ĒĢ┤ļŗ╣ ĒŖĖļ×ÖņØ┤ ņŗżņĀ£ Ēæ£ņĀüņØä ņČöņĀü ņżæņØĖņ¦Ć ņĢäļŗīņ¦Ćļź╝ ĒÖĢļźĀņĀüņ£╝ļĪ£ ĒÅēĻ░ĆĒĢ£ Ļ░Æņ£╝ļĪ£ ĒŖĖļ×ÖĻ┤Ćļ”¼ņŚÉ ņ׳ņ¢┤ ņżæņÜöĒĢ£ ļ│ĆņłśĻ░Ć ļÉ£ļŗż.
ļŗżņłśņØś Ēæ£ņĀüļōżņØ┤ ĻĘ╝ņĀæĒĢśņŚ¼ ņØ┤ļÅÖĒĢśļŖö ĒÖśĻ▓ĮņŚÉņä£, ņČöņĀüņżæņØĖ Ēæ£ņĀüņØś ņ£ĀĒÜ©ņĖĪņĀĢņśüņŚŁĻ│╝ ļŗżļźĖ Ēæ£ņĀüņØś ņ£ĀĒÜ©ņĖĪņĀĢņśüņŚŁņØ┤ ņä£ļĪ£ Ļ▓╣ņ╣śļŖö ņāüĒÖ®ņØ┤ ļ░£ņāØļÉ£ļŗżļ®┤ Ēæ£ņĀüļōżņŚÉ ļīĆĒĢ£ ņČöņĀĢ ņĀĢļ│┤Ļ░Ć ņä£ļĪ£ ļ░öļĆīĻ▒░ļéś ĒĢ®ņ│Éņ¦ĆļŖö ļ¼ĖņĀ£Ļ░Ć ļ░£ņāØĒĢ£ļŗż. IPDAļŖö ļŗ©ņØ╝Ēæ£ņĀü ņČöņĀüņØä ņ£äĒĢ£ ņ×ÉļŻīĻ▓░ĒĢ® ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ ļŗżņżæĒæ£ņĀü ĒÖśĻ▓ĮņŚÉ ņĀüņÜ®ņØĆ Ļ░ĆļŖźĒĢśņ¦Ćļ¦ī, Ēæ£ņĀüļōżņØ┤ ĻĘ╝ņĀæĒĢśļŖö ĒÖśĻ▓ĮņŚÉņä£ļŖö ņČöņĀüņä▒ļŖźņØ┤ ļ¢©ņ¢┤ņ¦äļŗż. JIPDAļŖö ĒŖĖļ×ÖĻ│╝ ņĖĪņĀĢņ╣ś ņé¼ņØ┤ņØś ļ░£ņāØ Ļ░ĆļŖźĒĢ£ ļ¬©ļōĀ FJE(Feasible Joint Event)ļź╝ Ļ│äņé░ĒĢśņŚ¼ ņ×ÉļŻīņŚ░Ļ┤ĆņØä ņłśĒ¢ēĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņĄ£ņĀüņØś ļŗżņżæĒæ£ņĀü ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ ņĢīļĀżņĀĖ ņ׳ļŗż. ĒĢśņ¦Ćļ¦ī ĻĘ╝ņĀæĒĢ£ Ēæ£ņĀüĻ│╝ ņĖĪņĀĢņ╣śņØś Ļ░£ņłśņŚÉ ļö░ļØ╝ ņŚ░ņé░ļ¤ēņØ┤ ĻĖēĻ▓®Ē׳ ņ”ØĻ░ĆĒĢśņŚ¼ ņŗżņĀ£ ĒÖśĻ▓ĮņŚÉ ņĀüņÜ®ņØ┤ ļČłĻ░ĆļŖźĒĢśļŗż.
ļé«ņØĆ SNR Ēæ£ņĀüņČöņĀü ĒÖśĻ▓ĮņŚÉņä£ VF-TBDņÖĆ DP-TBDņØś Ļ▓ĮņÜ░ ļŗżņżæ ĒöäļĀłņ×ä ņØ╝Ļ┤äņ▓śļ”¼ ĻĖ░ļ▓Ģņ£╝ļĪ£ ļŹ░ņØ┤Ēä░ļź╝ ļ¬©ņ£╝ļŖö ļÅÖņĢł Ēæ£ņĀüņČöņĀüņØ┤ ļČłĻ░ĆļŖźĒĢśĻ│Ā, PF-TBDļŖö ņÜ░ņłśĒĢ£ ņä▒ļŖźņØä Ļ░¢ĻĖ░ ņ£äĒĢ┤ ļ¦ÄņØĆ ĒīīĒŗ░Ēü┤ļōżņØä ņé¼ņÜ®ĒĢśļ®┤ ņŚ░ņé░ ļ╣äņÜ®ņØ┤ Ēü¼ļŗż. ņØ┤ļĢī, ļŗżņżæĒæ£ņĀü ĒÖśĻ▓ĮņØ┤ļØ╝ļ®┤ ņĢ×ņä£ ņ¢ĖĻĖēĒĢ£ TBDĻĖ░ļ▓ĢļōżņØĆ ņĀüņÜ®ņØ┤ ļŹöņÜ▒ ņ¢┤ļĀĄļŗż. JIPDA, JITS[7]ņÖĆ Ļ░ÖņØĆ ļŗżņżæĒæ£ņĀüņČöņĀü ĻĖ░ļ▓ĢņØĆ ņŗĀĒśĖņ▓śļ”¼ Ļ│╝ņĀĢņØä Ļ▒░ņ╣śņ¦Ć ņĢŖņØĆ ņĖĪņĀĢņ╣ś ņĀĢļ│┤ļź╝ ņé¼ņÜ®ĒĢśĻĖ░ņŚö ņŚ░ņé░ ĒÜ©ņ£©ņØ┤ ņóŗņ¦Ć ņĢŖļŗż.
ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ļŖö ļé«ņØĆ SNRņØś ļŗżņżæĒæ£ņĀü ĒÖśĻ▓ĮņŚÉ ņĀüĒĢ®ĒĢ£ Ēæ£ņĀüņČöņĀü ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ iJIPDA-AI(iterative JIPDA using Amplitude Information) ĻĖ░ļ▓ĢņØä ņĀ£ņĢłĒĢ£ļŗż. iJIPDA [8,9]ļŖö ĻĖ░ņĪ┤ JIPDAļź╝ ņ×¼ĻĘĆņĀü ĒśĢĒā£ļĪ£ Ļ│äņé░ļÉśļŖö MCD (Modulated Clutter Density)ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ņ£ĀļÅäļÉśļ®░, IPDA ņØś ņ×ÉļŻīĻ▓░ĒĢ®ĒÖĢļźĀ ļ░Å ņĪ┤ņ×¼ĒÖĢļźĀ ņé░ņČ£ņŚÉ ņé¼ņÜ®ļÉśļŖö Ēü┤ļ¤¼Ēä░ ļ░ĆļÅä ļīĆņŗĀ MCDļź╝ ņé¼ņÜ®ĒĢ©ņ£╝ļĪ£ņŹ© JIPDA ĻĄ¼ĒśäņØ┤ Ļ░ĆļŖźĒĢśļŗż. ĻĖ░ņĪ┤ JIPDAņØś Ļ▓ĮņÜ░ ļ░£ņāØ Ļ░ĆļŖźĒĢ£ ļ¬©ļōĀ FJEļź╝ ĻĄ¼ĒĢśĻ│Ā Ļ░üĻ░üņØś FJEņŚÉ ļīĆĒĢ£ ĒÖĢļźĀņĀü ĒÅēĻ░Ćļź╝ ņłśĒ¢ēĒĢ┤ņĢ╝ļ¦ī ĒŖĖļ×Öļ│ä ņ×ÉļŻīĻ▓░ĒĢ®ĒÖĢļźĀ ļ░Å ņĪ┤ņ×¼ĒÖĢļźĀ ņé░ņČ£ņØ┤ Ļ░ĆļŖźĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ļ│æļĀ¼ņ▓śļ”¼ ļ░®ņŗØņ£╝ļĪ£ Ļ░ü ĒŖĖļ×Öļ│ä ĒÖĢļźĀ Ļ│äņé░ņØ┤ ļČłĻ░ĆļŖźĒĢśļŗż. ļ░śļ®┤ iJIPDAļŖö IPDAņÖĆ ļÅÖņØ╝ĒĢ£ ņŚ░ņé░ĻĄ¼ņĪ░ļź╝ Ļ░Ćņ¦Ćļ®░, MCD ļśÉĒĢ£ Ļ░£ļ│äņĀüņ£╝ļĪ£ ņŚ░ņé░ņØ┤ Ļ░ĆļŖźĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ņŚ¼ļ¤¼ Ļ░£ņØś ĒŖĖļ×ÖņŚÉ ļīĆĒĢ£ Ļ░ü ĒÖĢļźĀļōżņØä ļŗżņłśņØś ņŚ░ņé░ ĒöäļĪ£ņäĖņä£ļź╝ ņØ┤ņÜ®ĒĢśņŚ¼ ļÅÖņŗ£ņŚÉ ņé░ņČ£ņØ┤ Ļ░ĆļŖźĒĢśļŗż. ļśÉĒĢ£ iJIPDAļŖö MCDļź╝ ņ×¼ĻĘĆņĀü ĒśĢĒā£ņØś ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ ĻĄ¼ĒĢśļ®░, ņŚ¼ĻĖ░ņä£ ņ×¼ĻĘĆņŚ░ņé░ Ēܤņłś(ĒÄĖņØśņāü LevelļĪ£ Ēæ£ĻĖ░)ļŖö iJIPDA ņØś ņä▒ļŖźĻ│╝ ņŚ░ņé░ļ¤ēņŚÉ ļīĆĒĢ£ Trade Off ļ│ĆņłśĻ░Ć ļÉ£ļŗż. iJIPDAļŖö LevelņŚÉ ļö░ļØ╝ IPDA(Level 0)ļČĆĒä░ JIPDA(Full Level)Ļ╣īņ¦Ć ĻĄ¼ĒśäņØ┤ Ļ░ĆļŖźĒĢśļŗż. ņČöņĀüĒĢäĒä░ņŚÉ ņ×ģļĀźļÉśļŖö ņĖĪņĀĢņ╣ś ņĀĢļ│┤ļŖö ņśżĻ▓Įļ│┤ ĒÖĢļźĀ(Probability of False Alarm)ņØä ņĪ░ņĀłĒĢśņŚ¼ Ēæ£ņĀüņČöņĀüņØ┤ Ļ░ĆļŖźĒĢ£ ņłśņżĆņØś ĒāÉņ¦ĆĒÖĢļźĀņŚÉņä£ ņČöņČ£ļÉśļŖö Ēæ£ņĀüĻ│╝ Ēü┤ļ¤¼Ēä░ ņĀĢļ│┤ļź╝ ņé¼ņÜ®ĒĢśņśĆļŗż. ļśÉĒĢ£ Ēü┤ļ¤¼Ēä░ņÖĆ Ēæ£ņĀüņŚÉ ļīĆĒĢ£ ļČäļ│äļĀźņØä ļåÆņØ╝ ņłś ņ׳ļÅäļĪØ iJIPDAņØś ņćäņŗĀ ļŗ©Ļ│äņŚÉņä£ Ļ▒░ļ”¼ņĀĢļ│┤ņÖĆ ņŗĀĒśĖņäĖĻĖ░ ņĀĢļ│┤ļź╝ ļÅÖņŗ£ņŚÉ ĒÖ£ņÜ®ĒĢśņŚ¼ iJIPDA-AIļĪ£ ĒÖĢņןĒĢśņśĆļŗż.
ņŗ£ņŖżĒģ£ ļ¬©ļŹĖļ¦ü
2ņ░©ņøÉ Ļ│ĄĻ░äņŚÉņä£ Ēæ£ņĀüņØś ņāüĒā£ ļ▓ĪĒä░ļŖö X k ┬Ā = ┬Ā [ x k ┬Ā y k ┬Ā x ╦Ö k ┬Ā y ╦Ö k ] T z k ┬Ā = ┬Ā [ z k , x ┬Ā z k , ┬Ā y ] T
ņŚ¼ĻĖ░ņä£ wk, vkļŖö Ļ░üĻ░ü Ļ│ĄņĀĢ ņ×ĪņØīĻ│╝ ņĖĪņĀĢ ņ×ĪņØīņØä ļéśĒāĆļé┤ļ®░, FļŖö ļō▒ņåŹļÅä ļ¬©ļŹĖņØś ņāüĒā£ņ▓£ņØ┤ Ē¢ēļĀ¼, HļŖö ņĖĪņĀĢņ╣ś Ē¢ēļĀ¼ ĻĘĖļ”¼Ļ│Ā I2ļŖö 2ņ░©ņøÉņØś ļŗ©ņ£äĒ¢ēļĀ¼ņØ┤ļŗż. TļŖö ņĖĪņĀĢņŻ╝ĻĖ░ļź╝ ņØśļ»ĖĒĢ£ļŗż.
ņŗĀĒśĖņäĖĻĖ░ņŚÉ ļīĆĒĢ£ Ēæ£ņĀüĻ│╝ Ēü┤ļ¤¼Ēä░ņØś ĒÖĢļźĀ ļČäĒżļŖö Žć2-Distribution ĒÖĢļźĀ ļ¬©ļŹĖņØä ņé¼ņÜ®ĒĢśņśĆļŗż. ņŗĀĒśĖņäĖĻĖ░(a)ņÖĆ Ēæ£ņĀüņŚÉ ļīĆĒĢ£ SNR Ļ░ÆņØ┤ ╬┤ļĪ£ ņŻ╝ņ¢┤ņĪīņØä ļĢī, Ēæ£ņĀüņŚÉ ņØśĒĢ┤ ņāØņä▒ļÉśļŖö ņŗĀĒśĖņØś ņäĖĻĖ░ņŚÉ ļīĆĒĢ£ Probability Density Function(PDF)ļź╝ f1(a), Ēü┤ļ¤¼Ēä░ņŚÉ ņØśĒĢ┤ ņāØņä▒ļÉśļŖö ņŗĀĒśĖ ņäĖĻĖ░ņŚÉ ļīĆĒĢ£ PDFļź╝ f0(a)ļØ╝Ļ│Ā ĒĢ£ļŗżļ®┤ Ļ░üĻ░ü
ņÖĆ Ļ░ÖņØ┤ ļéśĒāĆļé╝ ņłś ņ׳ņ£╝ļ®░, ņŗĀĒśĖņØś ņäĖĻĖ░ ņŗØ (3)Ļ│╝ (4)ļź╝ ņé¼ņÜ®ĒĢĀ Ļ▓ĮņÜ░, Ēæ£ņĀüņØś ĒāÉņ¦ĆĒÖĢļźĀ(Detection Probability)ņÖĆ Ēü┤ļ¤¼Ēä░ņŚÉ ņØśĒĢ£ ņśżĻ▓Įļ│┤ ĒÖĢļźĀ(False Alarm Probability)ļŖö ņŗØ (3)Ļ│╝ (4)Ļ░Ć ņØ╝ņĀĢĒĢ£ ĒāÉņ¦Ć ļ¼ĖĒä▒Ļ░ÆņØä ļäśļŖö Ļ▓ĮņÜ░ļĪ£ņŹ© ĒāÉņ¦Ć ļ¼ĖĒä▒Ļ░ÆņØä ŽäļØ╝Ļ│Ā ĒĢĀ ļĢī Ēæ£ņĀüņØś ĒāÉņ¦ĆĒÖĢļźĀ PD ņÖĆ ņśżĻ▓Įļ│┤ ĒÖĢļźĀ PfaļŖö ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ļéśĒāĆļé╝ ņłś ņ׳ļŗż.
ņ×¼ĻĘĆņŚ░ņé░ĒśĢ JIPDA: iterative JIPDA
iJIPDAļŖö Ēæ£ņĀüņĪ┤ņ×¼ĒÖĢļźĀ ļ░Å ņ×ÉļŻīĻ▓░ĒĢ®ĒÖĢļźĀ ņé░ņČ£ņŚÉ ĒĢäņÜöĒĢ£ Ēü┤ļ¤¼Ēä░ ļ░ĆļÅäļź╝ ņāłļĪ£ņÜ┤ Modulated Clutter Density (MCD)ļĪ£ Ļ│äņé░ĒĢśņŚ¼ ņØ┤ņÜ®ĒĢ©ņ£╝ļĪ£ņä£ IPDAņÖĆ ļÅÖņØ╝ĒĢ£ ņŚ░ņé░ĻĄ¼ņĪ░ļź╝ Ļ░Ćņ¦Ćļ®░, MCD ļśÉĒĢ£ Ļ░£ļ│äņĀüņ£╝ļĪ£ ņŚ░ņé░ņØ┤ Ļ░ĆļŖźĒĢśņŚ¼ ļŗżņłśņØś ĒŖĖļ×ÖņŚÉ ļīĆĒĢ£ Ļ░ü ĒÖĢļźĀļōżņØä ņŚ¼ļ¤¼ Ļ░£ņØś ņŚ░ņé░ ĒöäļĪ£ņäĖņä£ļź╝ ĒåĄĒĢ┤ ļÅÖņŗ£ņŚÉ ņé░ņČ£ņØ┤ Ļ░ĆļŖźĒĢśļŗż. ņØ┤ļ¤¼ĒĢ£ ĒŖ╣ņ¦ĢņØĆ ļŗżņżæĒæ£ņĀü ĒÖśĻ▓ĮņŚÉņä£ ņČöņĀü ņĢīĻ│Āļ”¼ļō¼ņØä ņŗżņĀ£ ņ▓┤Ļ│ä ņĀüņÜ®ņŚÉ Ļ░Ćņן ļ¼ĖņĀ£Ļ░Ć ļÉśļŖö ņŚ░ņé░ņŗ£Ļ░ä ņĖĪļ®┤ņŚÉņä£ Ēü░ ņןņĀÉņØ┤ ļÉ£ļŗż. ļśÉĒĢ£ iJIPDAņŚÉļŖö MCDļź╝ ņ×¼ĻĘĆņĀü ĒśĢĒā£ņØś ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ ĻĄ¼ĒĢśļ®░, ņ×¼ĻĘĆņŚ░ņé░ Ēܤņłś(Level)ļŖö iJIPDAņØś ņŚ░ņé░ļ¤ē(Ļ│äņé░ņØś ļ│Ąņ×ĪļÅä)Ļ│╝ ņä▒ļŖźņŚÉ ļīĆĒĢ£ Trade Off ļ│ĆņłśĻ░Ć ļÉ£ļŗż. 0 LevelņØ╝ Ļ▓ĮņÜ░ IPDAņÖĆ ļÅÖņØ╝ĒĢśļ®░, Full Level (ņŚ░ņé░ Ļ░ĆļŖźĒĢ£ ņĄ£ļīĆ Level)Ļ╣īņ¦Ć Ļ│äņé░ĒĢĀ Ļ▓ĮņÜ░ JIPDAņÖĆ ļÅÖņØ╝ĒĢ┤ņ¦äļŗż. ļĢīļ¼ĖņŚÉ ņØ┤ļ¤¼ĒĢ£ ĒŖ╣ņ¦ĢņØä ņØ┤ņÜ®ĒĢśņŚ¼ ĒÖśĻ▓ĮņŚÉ ļö░ļØ╝ LevelņØä ņäĀĒāØĒĢĀ ņłś ņ׳ļÅäļĪØ ņČöņĀü ĒĢäĒä░ ņäżĻ│äĻ░Ć Ļ░ĆļŖźĒĢśļŗż. JIPDA ĻĖ░ļ▓ĢĻ│╝ ļ¦łņ░¼Ļ░Ćņ¦ĆļĪ£ event ņ”ØĻ░ĆņŚÉ ļö░ļźĖ ņŚ░ņé░ņØä ņżäņØ┤ĻĖ░ ņ£äĒĢ┤ Ēü┤ļ¤¼ņŖżĒä░ļ¦ü ĻĖ░ļ▓ĢņØä ņé¼ņÜ®ĒĢ£ļŗż. Ēü┤ļ¤¼ņŖżĒä░ļ¦ü ĻĖ░ļ▓ĢņØĆ ĻĘ╝ņĀæĒĢ£ ĒŖĖļ×ÖļōżņØś ņ£ĀĒÜ©ņĖĪņĀĢņśüņŚŁņŚÉ Ļ│ĄĒåĄņ£╝ļĪ£ Ļ│Ąņ£ĀĒĢśļŖö ņĖĪņĀĢņ╣śĻ░Ć ņ׳ņØä Ļ▓ĮņÜ░ ĒĢ┤ļŗ╣ ĒŖĖļ×ÖļōżĻ│╝ ĻĘĖ ĒŖĖļ×ÖļōżņØś ņ£ĀĒÜ©ņĖĪņĀĢņśüņŚŁņŚÉ ĒżĒĢ©ļÉśļŖö ļ¬©ļōĀ ņĖĪņĀĢņ╣śļōżņØä ĒĢśļéśļĪ£ ļ¼ČļŖö ļ░®ļ▓ĢņØ┤ļŗż. Ēü┤ļ¤¼ņŖżĒä░ ņ¦æĒĢ®ņØĆ {Tki, zk}ļĪ£ ņĀĢņØśĒĢśļ®░ ĒŖĖļ×Ö ņ¦æĒĢ® TkļŖö ņĖĪņĀĢņ╣ś ņ¦æĒĢ® zkļź╝ Ļ│Ąņ£ĀĒĢ£ļŗż.
iJIPDAļŖö Ēü┤ļ¤¼ņŖżĒä░ņØś ņĖĪņĀĢņ╣śļōżņØä ĒŖĖļ×ÖņŚÉ ĒĢĀļŗ╣ņŗ£ņ╝£ņŻ╝ļŖö ņĖĪņĀĢņ╣ś ĒĢĀļŗ╣ ĻĖ░ļ▓Ģņ£╝ļĪ£ ļŗżņżæĒæ£ņĀü ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢ£ļŗż. ņØ┤ļĢī ĒŖĖļ×ÖĻ│╝ ņĖĪņĀĢņ╣śļź╝ ņ×ÉļŻīĻ▓░ĒĢ® ĒŖĖļ”¼(Tree) ĒśĢĒā£ļĪ£ ĒĢĀļŗ╣ĒĢśļ®░ ĒŖĖļ×ÖļōżņØĆ ļģĖļō£, ņĖĪņĀĢņ╣śļōżņØĆ Ļ░Ćņ¦ĆņØś ņŚŁĒĢĀņØä ĒĢśĻ│Ā ņĖĪņĀĢņ╣śļōżņŚÉ ļīĆĒĢ£ MCDļź╝ ņ×¼ĻĘĆņĀü ĒśĢĒā£ļĪ£ Ļ│äņé░ĒĢ£ļŗż.
ņ┤łĻĖ░ ĻĖ░ņżĆ(Root) ĒŖĖļ×ÖņØä ŽäiļØ╝Ļ│Ā ĒĢĀ ļĢī, ņ×ÉļŻīĻ▓░ĒĢ® ĒŖĖļ”¼ņØś Ļ░Ćņ¦Ć ņ╣śļŖö(ņĖĪņĀĢņ╣ś ĒĢĀļŗ╣) ļ░®ņŗØņØä ņäżļ¬ģĒĢśĻĖ░ ņ£äĒĢ£ ļ│ĆņłśļōżņØä ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ņĀĢņØśĒĢ£ļŗż.
- Žäj: ņä£ļĖī ĒŖĖļ”¼ņØś ĻĖ░ņżĆ ĒŖĖļ×Ö
- ╬Ę: ŽäiļČĆĒä░ ŽäjĻ╣īņ¦Ć ņŚ░Ļ▓░ļÉ£ ļģĖļō£(ĒŖĖļ×Ö) ņ¦æĒĢ®(ŽäjņĀ£ņÖĖ)
- ╬Ą: ŽäiļČĆĒä░ ŽäjĻ╣īņ¦Ć ņŚ░Ļ▓░ļÉ£ Ļ░Ćņ¦Ć(ņĖĪņĀĢņ╣ś) ņ¦æĒĢ®.
ņ£äņÖĆ Ļ░ÖņØĆ ņĀĢņØśļź╝ ĒåĄĒĢ┤ ņ┤łĻĖ░ ĻĖ░ņżĆ ĒŖĖļ×ÖņŚÉņä£ļŖö ╬Ę = Ōłģ, ╬Ą = ŌłģņØ┤ ļÉśļ®░, ļŗżņØīĻ│╝ Ļ░ÖņØ┤ ĒĢ©ņłśļōżļÅä ņĀĢņØśĒĢ£ļŗż.
- ╬” ╬Ą Žä j ┬Ā = ┬Ā { z : ( z Ōłł z k Žä j ) ┬Ā Ōł¦ ┬Ā ( z Ōłē ╬Ą ) }
- ╬Ė ╬Ę ( z ) ┬Ā = ┬Ā { t : ( z Ōłł z k t ) ┬Ā Ōł¦ ┬Ā ( t Ōłē ╬Ę ) }
ņä£ļĖī ĒŖĖļ”¼ Žäjļź╝ ņżæņŗ¼ņ£╝ļĪ£ ņāłļĪ£ņÜ┤ Ļ░Ćņ¦Ćļź╝ ņ╣Ā ļĢī ĒĢäņÜöĒĢ£ ņĖĪņĀĢņ╣śņÖĆ ĒŖĖļ×Ö ņīŹņØĆ { t , z } ┬Ā : ┬Ā ( t Ōłł ╬Ė ╬Ę ( z ) ) ┬Ā Ōł¦ ┬Ā ( z Ōłł ╬” ╬Ą Žä j ┬Ā ) ╬” ╬Ą Žä j ┬Ā = ┬Ā Ōłģ ╬Ė ╬Ę ( z ) ┬Ā = ┬Ā Ōłģ
ņÖĆ Ļ░Öļŗż. ņ£ä ņŗØņŚÉņä£ zņĖĪņĀĢņ╣śĻ░Ć zk,nņØĖ Ļ▓ĮņÜ░, p k t ( z k , n ) = p k , n t , Žü k ( z k , n ) = Žü k , n R ╬Ą Ōł¬ { z } ╬Ę Ōł¬ Žä j | t
iJIPDAņĢīĻ│Āļ”¼ļō¼ņØĆ |╬Ę| = LņØĖ ĻĄ¼Ļ░äņŚÉņä£ MCDļź╝ ņŗØ (10)ņÖĆ Ļ░ÖņØ┤ Ļ│äņé░ĒĢ©ņ£╝ļĪ£ņŹ©, LevelņØä ņĀ£ĒĢ£ĒĢśņŚ¼ (ņČöĻ░ĆņĀüņØĖ ņĖĪņĀĢņ╣ś ĒĢĀļŗ╣ņØä ĒĢśņ¦Ć ņĢŖĻ│Ā) Ļ│äņé░ņØ┤ Ļ░ĆļŖźĒĢśļŗż. Level ņØä ņĀ£ĒĢ£ĒĢśņ¦Ć ņĢŖĻ│Ā ņ×ÉļŻīĻ▓░ĒĢ® ĒŖĖļ”¼ļź╝ ļ¬©ļæÉ LeafĻ╣īņ¦Ć Ļ│äņé░ĒĢĀ Ļ▓ĮņÜ░, ņØ┤ļź╝ Full LevelņØ┤ļØ╝ ĒĢ£ļŗż.
iJIPDAņØś ĒŖĖļ×Ö ŽäiņŚÉ ļīĆĒĢ£ ņ×ÉļŻīĻ▓░ĒĢ®ĒÖĢļźĀ(╬▓ k , j Žä j
ņÖĆ Ļ░Öļŗż. ņŚ¼ĻĖ░ņä£ P G Žä i p k , j Žä i Žü ~ Ōłģ { Žä i } ( z k , j )
ņŚ¼ĻĖ░ņä£ A Ōłģ { Žä i } { T k Ōł¢ Žä i , ┬Ā z k } A { z k , j } { Žä i } { T k Ōł¢ Žä i , ┬Ā z k Ōł¢ z k , j } ┬Ā z k Ōł¢ z k , j A Ōłģ { Žä i } A { z k , j } { Žä i } A Ōłģ { Žä i }
ņÖĆ Ļ░Öņ£╝ļ®░, ņŚ¼ĻĖ░ņä£ A { z k , j } { Žä i } ļŖö A Ōłģ { T i } ņŚÉņä£ A { z k , j } { T i }
ņŚ¼ĻĖ░ņä£ ╬Ę ┬Ā = ┬Ā { Žä i , ┬Ā Žä r } A { z k , j } ╬Ę { T k Ōł¢ ╬Ę , ┬Ā z k Ōł¢ z k , j }
ņŗĀĒśĖņäĖĻĖ░ ņĀĢļ│┤ļź╝ ņØ┤ņÜ®ĒĢ£ ņ×ÉļŻīĻ▓░ĒĢ®ĻĖ░ļ▓Ģ[10]
ņØ╝ļ░śņĀüņØĖ PDA Ļ│äņŚ┤ņØś ņĢīĻ│Āļ”¼ņ”śņØĆ ņ£ĀĒÜ©ņĖĪņĀĢņśüņŚŁ ļé┤ņŚÉ ņ£äņ╣śĒĢśļŖö ļ¬©ļōĀ ņĖĪņĀĢņ╣śļōżņØä ņČöņĀü ņżæņØĖ Ēæ£ņĀüņ£╝ļĪ£ Ļ░ĆņĀĢĒĢśļ®░ Ļ░üĻ░üņØś ņĖĪņĀĢņ╣śļōżņØ┤ Ļ░¢ļŖö Ļ▒░ļ”¼ņĀĢļ│┤ļź╝ ĒåĄĒĢ┤ Ēæ£ņĀüņØ╝ ĒÖĢļźĀņØä ĻĄ¼ĒĢ£ļŗż. ņŚ¼ĻĖ░ņä£ Ļ▒░ļ”¼ņĀĢļ│┤ļ┐Éļ¦ī ņĢäļŗłļØ╝ ņŗĀĒśĖ ņäĖĻĖ░ ņĀĢļ│┤ļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ Ēæ£ņĀüņØ╝ ĒÖĢļźĀņĀü Ļ░Ćņżæņ╣śļź╝ Ļ│äņé░ĒĢśļ®┤ Ēæ£ņĀü ņŻ╝ļ│ĆņØś Ēü┤ļ¤¼Ēä░ņŚÉ ļīĆĒĢ£ ļČäļ│äļĀźņØä ĒéżņÜĖ ņłś ņ׳ļŗż.
ņ£ä ņŗØņØĆ ņ£äņ╣ś ņĀĢļ│┤ļ¦īņØä ņØ┤ņÜ®ĒĢ£ ņ×ÉļŻīĻ▓░ĒĢ®ĒÖĢļźĀņØä Ļ│äņé░ĒĢśļŖö ņŗØ (11)ņŚÉņä£ ņ£ĀĒÜ©ņĖĪņĀĢņśüņŚŁ ļé┤ņØś ņĖĪņĀĢņ╣śĻ░Ć Ļ░¢ļŖö ņŗĀĒśĖņäĖĻĖ░ ņĀĢļ│┤ņØĖ Ōł¦jļź╝ ņČöĻ░ĆĒĢ£ Ļ▓āņØ┤ļŗż. f 1 Žä f 0 Žä
ņŗ£ļ«¼ļĀłņØ┤ņģś ļ░Å Ļ▓░Ļ│╝ ļČäņäØ
ņĀ£ņĢłĒĢśļŖö ņĢīĻ│Āļ”¼ņ”śņØś ņä▒ļŖźņØä Ļ▓Ćņ”ØĒĢśĻĖ░ ņ£äĒĢ┤ 2ņ░©ņøÉ ĒÖśĻ▓ĮņŚÉņä£ņØś ļŗżņłśĒæ£ņĀüņŚÉ ļīĆĒĢ£ ņČöņĀü ņŗ£ļ«¼ļĀłņØ┤ņģśņØä ņłśĒ¢ēĒĢśņśĆļŗż. ņŗ£ļ«¼ļĀłņØ┤ņģśņŚÉ ņĀüņÜ®ĒĢ£ ņĢīĻ│Āļ”¼ņ”śņØĆ iJIPDA-AI level 0ļČĆĒä░ 4Ļ│╝ LM(Linear Multi-target)-IPDA[11]ņØ┤ļ®░ levelņŚÉ ļö░ļźĖ ņä▒ļŖźĻ│╝ ņŚ░ņé░ļ¤ēņØä ļČäņäØĒĢśņśĆļŗż. ņČöņĀü ĻĖ░ļ▓ĢņØś ņä▒ļŖźņØĆ ņČöņĀü ņä▒Ļ│ĄļźĀņØä ļéśĒāĆļé┤ļŖö CTT(Confirmed True Tracks)Ļ│╝ ņČöņĀü ņĀĢļ░ĆļÅäļź╝ ļéśĒāĆļé┤ļŖö RMSE(Root Mean Square Error)ļź╝ ĒåĄĒĢ┤ ļ╣äĻĄÉ ļ░Å ļČäņäØĒĢśņśĆļŗż. CTT ļŖö ĒŖĖļ×ÖņØś ņĪ┤ņ×¼ĒÖĢļźĀņØ┤ ĒŖĖļ×ÖĻ┤Ćļ”¼ĻĖ░ļ▓Ģ[5]ņØś ĒÖĢņĀĢ ļ¼ĖĒä▒ņ╣śļ│┤ļŗż ļåÆĻ│Ā ĒŖĖļ×ÖņØś ņČöņĀĢ Ļ░ÆņØ┤ ņŗżņĀ£ Ēæ£ņĀüĻ│╝ ņ£äņ╣ś, ņåŹļÅäĻ░Ć ņØ╝ņĀĢ ļ▓öņ£ä ļé┤ļĪ£ ļōżņ¢┤ņśżļŖö ĒŖĖļ×ÖņØä ņØśļ»ĖĒĢ£ļŗż.
LM-IPDAļŖö IPDAņŚÉ LM ņĢīĻ│Āļ”¼ņ”śņØä Ļ▓░ĒĢ®ĒĢ£ ĻĖ░ļ▓ĢņØ┤ļŗż. ĒŖĖļ×ÖĻ░äņØś ņĖĪņĀĢņ╣ś ĒĢĀļŗ╣ ļČĆļČäņØ┤ ĒĢäņÜö ņŚåņ¢┤ ļŗżņłś Ēæ£ņĀü ņČöņĀü ĒÖśĻ▓ĮņŚÉņä£ ņŚ░ņé░ ĒÜ©ņ£©ņØ┤ ļø░ņ¢┤ļé£ ņĢīĻ│Āļ”¼ņ”śņ£╝ļĪ£ ņĢīļĀżņĀĖņ׳ņ¢┤ ņŗ£ļ«¼ļĀłņØ┤ņģś ļ╣äĻĄÉ ļīĆņāüņ£╝ļĪ£ ņäĀņĀĢĒĢśņśĆļŗż. LM ņĢīĻ│Āļ”¼ņ”śņØĆ ņ£ĀĒÜ©ņĖĪņĀĢņśüņŚŁ ļé┤ņŚÉ ņĪ┤ņ×¼ĒĢśļŖö Ēü┤ļ¤¼Ēä░ļ┐É ņĢäļŗłļØ╝ ļŗżļźĖ Ēæ£ņĀüņ£╝ļĪ£ļČĆĒä░ ļ░£ņāØĒĢ£ ņĖĪņĀĢņ╣śļÅä Ēü┤ļ¤¼Ēä░ļĪ£ ļ│┤ļŖö Ļ▓āņØ┤ ĒŖ╣ņ¦ĢņØ┤ļŗż. LM-IPDAņØś ĒĢäĒä░ ņćäņŗĀĻ│╝ņĀĢņØĆ IPDAņÖĆ ņ£Āņé¼ĒĢśļ®░ ļŗ©ņ¦Ć Ēü┤ļ¤¼Ēä░ ļ░ĆļÅäļź╝ Ļ│äņé░ĒĢĀ ļĢī ļŗżļźĖ ĒŖĖļ×Öņ£╝ļĪ£ļČĆĒä░ ļ░£ņāØĒĢĀ ĒÖĢļźĀņØ┤ ņČöĻ░ĆļÉ£ļŗż. LM-IPDA ņØś ņāłļĪ£ņÜ┤ Ēü┤ļ¤¼Ēä░ ļ░ĆļÅäļŖö ņŗØ (23)ņÖĆ Ļ░Öļŗż.
ņŚ¼ĻĖ░ņä£ nņØĆ ĒŖĖļ×ÖņØś Ļ░£ņłś, ŽüļŖö Ļ│ĀņĀĢ Ēü┤ļ¤¼Ēä░ ļ░ĆļÅä, p k , j Žā p k , j Žā
ņØ┤ ļģ╝ļ¼ĖņŚÉņä£ Ļ│ĀļĀżĒĢ£ ņŗ£ļ«¼ļĀłņØ┤ņģś ĒÖśĻ▓ĮņØĆ ņāüĻ│ĄņŚÉņä£ ņĢäļ×½ļ░®Ē¢źņØä ĒāÉņāēĒĢśļŖö 2ņ░©ņøÉ Airborne ļĀłņØ┤ļŹö ĒÖśĻ▓Į(Look-down Capability Test)ņØä ļ¬©ņé¼ĒĢśņśĆļŗż. ļĀłņØ┤ļŹöļŖö Ļ▒░ļ”¼ 20 m, ļ░®ņ£äĻ░ü 0.05ļÅäņØś ļČäĒĢ┤ļŖźņØä Ļ░¢ņ£╝ļ®░ 50├Ś50 ņśüņŚŁ (Ļ▒░ļ”¼ 20000~21000 m, ļ░®ņ£äĻ░ü 43~45.5┬░ ņśüņŚŁ)ņŚÉņä£ 5Ļ░£ņØś ļō▒ņåŹņÜ┤ļÅÖ Ēæ£ņĀüņŚÉ ļīĆĒĢ£ ņČöņĀüņØä ņłśĒ¢ēĒĢśņśĆļŗż. Ēæ£ņĀüņØĆ ļ¦łĒĢś 1.5ļČĆĒä░ 2.2ņé¼ņØ┤ņØś ņåŹļÅäļź╝ Ļ░¢ļŖö ņĀäĒł¼ĻĖ░ļĪ£ Ļ░ĆņĀĢĒĢśņśĆļŗż. 5Ļ░£ Ēæ£ņĀüņØś ņ┤łĻĖ░ ņ£äņ╣ś ļ░Å ņåŹļÅäļŖö ņĢäļלņÖĆ Ļ░Öņ£╝ļ®░ xņČĢ ņ£äņ╣ś, yņČĢ ņ£äņ╣ś, xņČĢ ņåŹļÅä, yņČĢ ņåŹļÅä ņł£ņ£╝ļĪ£ Ēæ£ĻĖ░ĒĢśņśĆļŗż.
ŌĆō Ēæ£ņĀü 1: (14166 m, 14117 m, 600 m/s, 100 m/s)
ŌĆō Ēæ£ņĀü 2: (14362 m, 13918 m, 440 m/s, 440 m/s)
ŌĆō Ēæ£ņĀü 3: (14507 m, 13767 m, 260 m/s, 700 m/s)
ŌĆō Ēæ£ņĀü 4: (14404 m, 14304 m, 500 m/s, ŌłÆ100 m/s)
ŌĆō Ēæ£ņĀü 5: (14846 m, 13844 m, ŌłÆ100 m/s, 500 m/s)
Ēæ£ņĀüņØś ņŗĀĒśĖĻ░Ć ļ░£ņāØĒĢśļŖö ĒöĮņģĆņØĆ ņŗØ (3), Ēü┤ļ¤¼Ēä░ņØś ņŗĀĒśĖļŖö ņŗØ (4)ņŚÉ ļö░ļØ╝ ņŗĀĒśĖņäĖĻĖ░Ļ░Ć Ļ▓░ņĀĢļÉśļ®░ SNRņØ┤ 13, 20 dBņØĖ ĒÖśĻ▓ĮļōżņŚÉ ļīĆĒĢśņŚ¼ 500ĒÜīņö® ļ¬¼Ēģīņ╣╝ļĪ£ ņŗ£ļ«¼ļĀłņØ┤ņģśņØä ņłśĒ¢ēĒĢśņśĆļŗż. Ēæ£ņĀüņØś ĻČżņĀüņØĆ x, yņČĢ ļ│äļĪ£ 20 mņØś Ēæ£ņżĆĒÄĖņ░©ļź╝ Ļ░¢ļŖö Ļ░ĆņÜ░ņŗ£ņĢł ņ×ĪņØīņØä ņČöĻ░ĆĒĢśņśĆļŗż. Fig. 1ņØĆ Ēæ£ņĀüņØś SNRņØ┤ 13 dBņØĖ ņŗ£ļ«¼ļĀłņØ┤ņģś ĒÖśĻ▓ĮņØ┤ļŗż. 5Ļ░£ Ēæ£ņĀüņØś ņ░Ė Ļ░ÆņØĆ xļĪ£ Ēæ£ņŗ£ĒĢśņśĆņ£╝ļ®░ ņśżĻ▓Įļ│┤ ĒÖĢļźĀ Pfa = 0.01 ņØ╝ ļĢī ļ░£ņāØĒĢśļŖö Ēü┤ļ¤¼Ēä░ņÖĆ Ēæ£ņĀüņŚÉ ļīĆĒĢ£ ņĖĪņĀĢņ╣śļŖö ļģĖļ×Ćņāē ņøÉņ£╝ļĪ£ Ēæ£ņŗ£ĒĢśņśĆļŗż. Ēü┤ļ¤¼Ēä░ļŖö ĒöäļĀłņ×äļ¦łļŗż ĒÅēĻĘĀ 25Ļ░£ ņāØņä▒ļÉśņŚłļŗż. ĒöäļĀłņ×ä Ļ░äņØś ņĖĪņĀĢņŻ╝ĻĖ░ļŖö T = 50 ms ņØ┤ļ®░, ņČöņĀü ĒĢäĒä░ņØś Ļ│ĄņĀĢņ×ĪņØī wkņØś Ēæ£ņżĆĒÄĖņ░© 0.3 m/s2ņØ┤Ļ│Ā ņĖĪņĀĢņ×ĪņØī vkņØś Ēæ£ņżĆĒÄĖņ░©ļŖö 20 mļĪ£ ļ¬©ļŹĖļ¦üĒĢśņśĆļŗż.
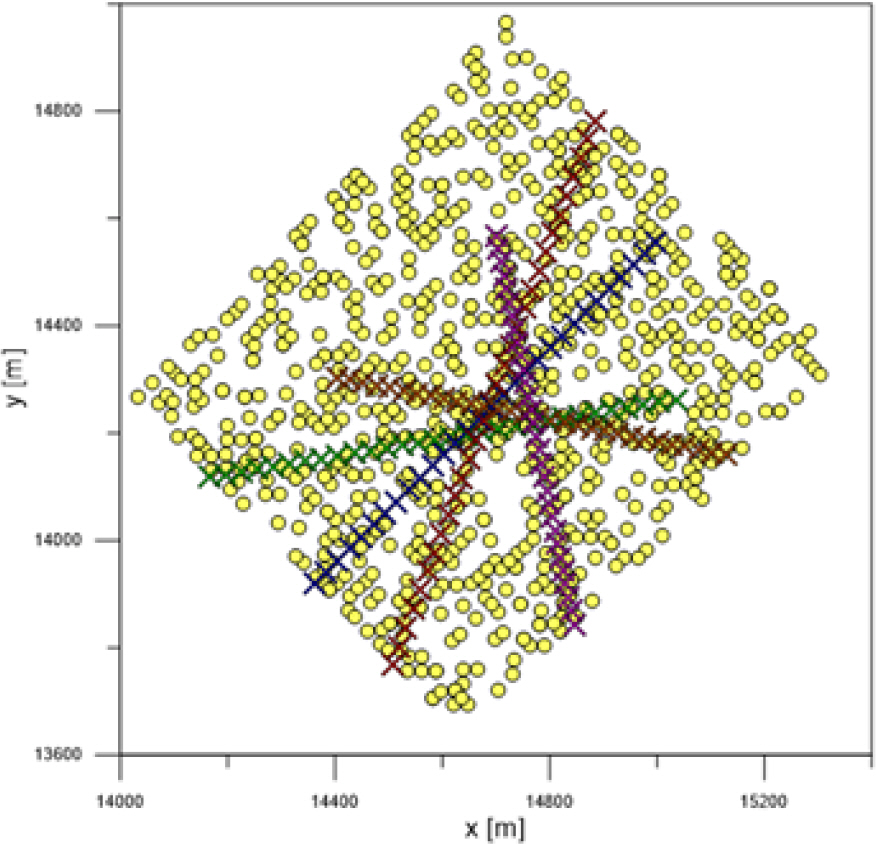
Fig. 2ņÖĆ 3ņØĆ Ēæ£ņĀü SNRņØ┤ 13 dBņØĖ ĒÖśĻ▓ĮņŚÉņä£ņØś Ēæ£ņĀüņČöņĀü Ļ▓░Ļ│╝ņØ┤ļŗż. ņŗØ (5), (6)ņØä ĒåĄĒĢ┤ ņŻ╝ņ¢┤ņ¦ä SNRĻ│╝ PfaņŚÉ ļö░ļØ╝ ĒāÉņ¦ĆĒÖĢļźĀņØĆ 0.8296ņØ┤ļ®░, Ļ│ĄņĀĢĒĢ£ ņČöņĀü ņä▒Ļ│ĄļźĀ ļ╣äĻĄÉļź╝ ņ£äĒĢ┤ ļ¬©ļōĀ ņĢīĻ│Āļ”¼ņ”śņØś ņ┤łĻĖ░ ĒŖĖļ×ÖņĪ┤ņ×¼ĒÖĢļźĀņØĆ 0.001, CFT(Confirmed False Tracks)ļź╝ 1500Ļ░£(ņŗ£ļ«¼ļĀłņØ┤ņģś 1ĒÜī ļŗ╣ ĒÅēĻĘĀ 3Ļ░£)ļĪ£ ņĪ░ņĀĢĒĢśņśĆļŗż. CFTļ×Ć ĒÖĢņĀĢļÉśņŚłļŹś ĒŖĖļ×ÖņØ┤ Ēæ£ņĀüņØä ļåōņ╣śĻ▓ī ļÉśņ¢┤ ĒŖĖļ×ÖņĪ┤ņ×¼ĒÖĢļźĀņØ┤ ļ¢©ņ¢┤ņĀĖņä£ ņĀ£Ļ▒░ļÉśĻ▒░ļéś ĒŖĖļ×ÖņØ┤ ņŗżņĀ£ ĻČżņĀüņ£╝ļĪ£ļČĆĒä░ ļ®Ćņ¢┤ņ¦ĆļŖö Ļ▓ĮņÜ░ņŚÉ ļ░£ņāØĒĢ£ļŗż. ņĢīĻ│Āļ”¼ņ”ś ļ│ä CFT ņłśļŖö ĒŖĖļ×ÖĻ┤Ćļ”¼ĻĖ░ļ▓ĢņØś ĒŖĖļ×Ö ĒÖĢņĀĢ ļ¼ĖĒä▒ņ╣śļź╝ ņĪ░ņĀłĒĢśņŚ¼ ļ¦×ņĘäņ£╝ļ®░ iJIPDA-AI Level 0ļČĆĒä░ 4ļŖö Ļ░üĻ░ü 0.999, 0.9935, 0.991, 0.99, 0.99 ĻĘĖļ”¼Ļ│Ā LM-IPDA-AIļŖö 0.995ļĪ£ ņäżņĀĢĒĢśņśĆļŗż. ļŗ©ņØ╝Ēæ£ņĀüņČöņĀü ĻĖ░ļ▓ĢņØĖ IPDAņÖĆ ļÅÖņØ╝ĒĢ£ ņä▒ļŖźņØä Ļ░¢ļŖö Level 0ņØś ņČöņĀü ņä▒Ļ│ĄļźĀ ļ░Å ņĀĢĒÖĢļÅäĻ░Ć Ļ░Ćņן ļ¢©ņ¢┤ņ¦Ćļ®░ LevelņØ┤ ļåÆņĢäņ¦łņłśļĪØ ņČöņĀü ņä▒ļŖźņØ┤ ņóŗĻ▓ī ļéśņśżļŖö Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆļŗż. ļśÉĒĢ£ LM-IPDA-AIņØś Ļ▓ĮņÜ░ iJIPDA-AIņØś Level 0Ļ│╝ 1 ņé¼ņØ┤ņØś ņä▒ļŖźņØä ļ│┤ņśĆļŗż.
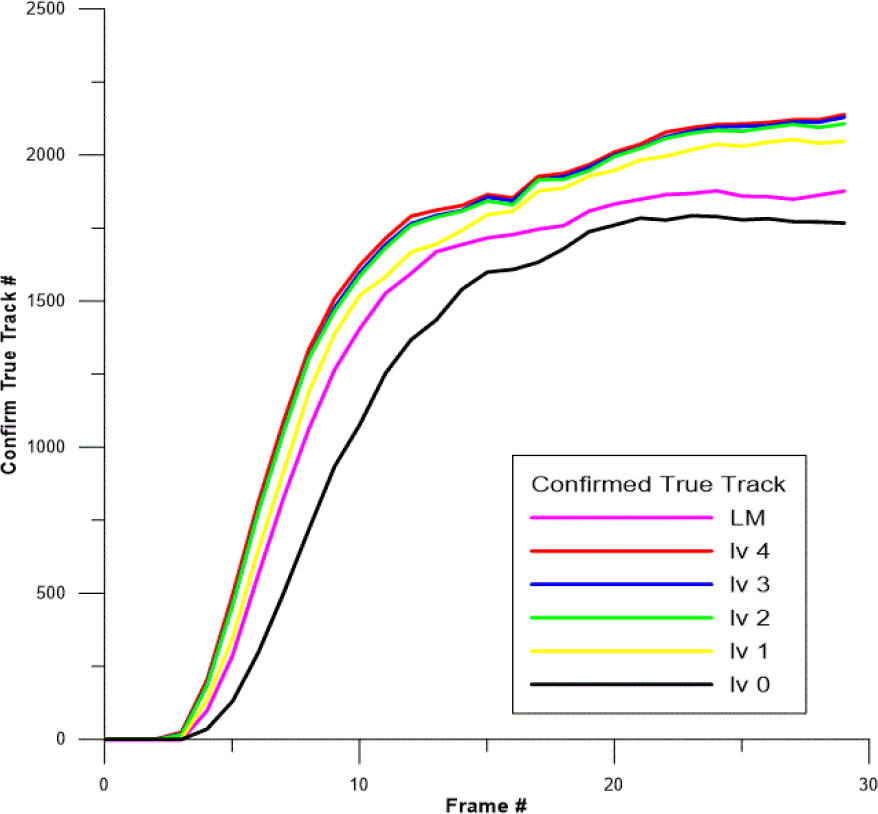

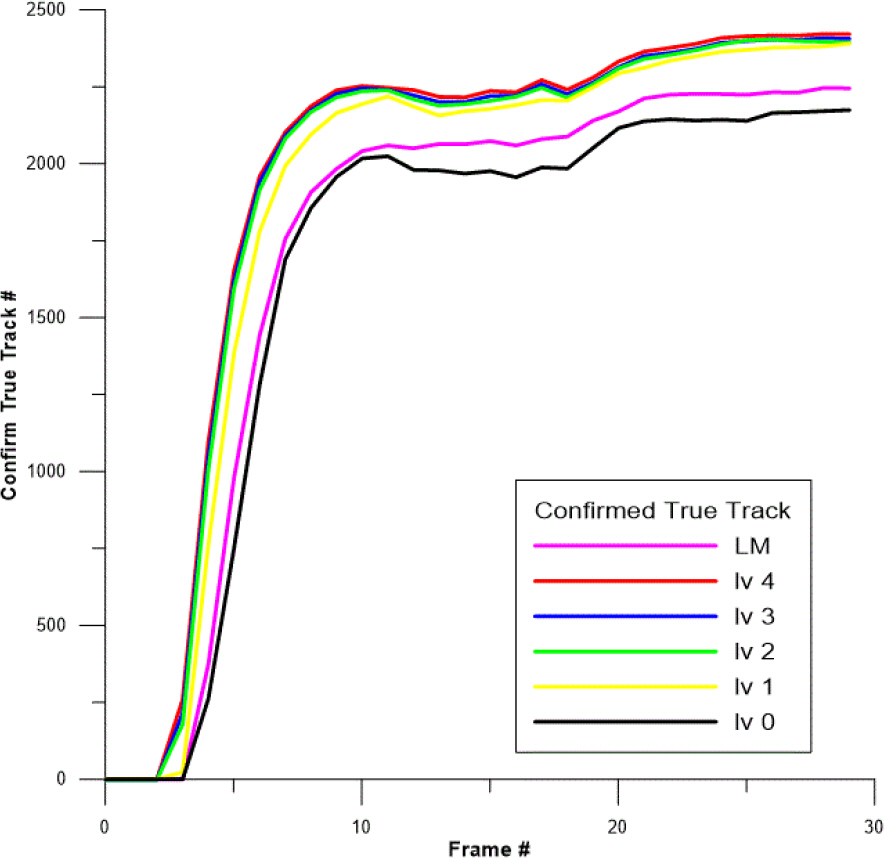
Fig. 4ņÖĆ 5ļŖö Ēæ£ņĀüņØś SNRņØ┤ 20 dBņØĖ ĒÖśĻ▓ĮņŚÉņä£ņØś Ēæ£ņĀüņČöņĀü Ļ▓░Ļ│╝ņØ┤ļŗż. ĒĢ┤ļŗ╣ ĒÖśĻ▓ĮņŚÉņä£ņØś ĒāÉņ¦ĆĒÖĢļźĀņØĆ 0.95 54ņØ┤ļ®░, Ļ│ĄņĀĢĒĢ£ ņČöņĀü ņä▒Ļ│ĄļźĀ ļ╣äĻĄÉļź╝ ņ£äĒĢ┤ ļ¬©ļōĀ ņĢīĻ│Āļ”¼ņ”śņØś ņ┤łĻĖ░ ĒŖĖļ×ÖņĪ┤ņ×¼ĒÖĢļźĀņØĆ 0.001, CFTļź╝ 1000Ļ░£(ņŗ£ļ«¼ļĀłņØ┤ņģś ļŗ╣ ĒÅēĻĘĀ 2Ļ░£)ļĪ£ ņĪ░ņĀĢĒĢśņśĆĻ│Ā ĒŖĖļ×Ö ĒÖĢņĀĢ ļ¼ĖĒä▒ņ╣śļŖö iJIPDA-AI Level 0ļČĆĒä░ 4ļŖö Ļ░üĻ░ü 0.99, 0.97, 0.955, 0.953, 0.952 ĻĘĖļ”¼Ļ│Ā LM-IPDA-AIļŖö 0.975ļĪ£ ņäżņĀĢĒĢśņśĆļŗż. SNR 13 dB ĒÖśĻ▓ĮņŚÉ ļ╣äĒĢ┤ ļåÆņØĆ ĒāÉņ¦ĆĒÖĢļźĀļĪ£ CTTļŖö ļŹö ļåÆĻ│Ā RMSEļŖö ļŹö ļé«Ļ▓ī ļéśĒāĆļéśļ®░ SNRņØ┤ ļåÆņØäņłśļĪØ ņĀäņ▓┤ņĀüņØĖ ņČöņĀü ņä▒ļŖźņØ┤ ņÜ░ņłśĒĢ©ņØä ĒÖĢņØĖĒĢśņśĆņ£╝ļ®░, iJIPDA -AIņØś Level ļ│ä Ēæ£ņĀüņČöņĀü Ļ▓░Ļ│╝ļŖö SNR 13 dB Ļ▓ĮņÜ░ņÖĆ ņ£Āņé¼ĒĢ£ Ļ▓ĮĒ¢źņØä ļ│┤ņśĆļŗż.

ņŗ£ļ«¼ļĀłņØ┤ņģś ņŚ░ĻĄ¼ņŚÉ ņé¼ņÜ®ļÉ£ ņ╗┤Ēō©Ēä░ ņé¼ņ¢æņØĆ CPU i7-6700 3.40 GHz, RAM 16 GBņØ┤ļ®░, Table 1ņØĆ ņĢīĻ│Āļ”¼ņ”ś ļ│ä ņŚ░ņé░ņåŹļÅäļź╝ ļéśĒāĆļéĖļŗż. ļ¬©ļōĀ ņČöņĀüĒĢäĒä░ņØś ĒĢ£ Cycle (ĒĢäĒä░ ņśłņĖĪ, ņ£ĀĒÜ©ņĖĪņĀĢņ╣ś ņäĀĒāØ, MCD Ļ│äņé░, ĒĢäĒä░ ņćäņŗĀ ĻĘĖļ”¼Ļ│Ā ĒŖĖļ×ÖĻ┤Ćļ”¼ĻĖ░ļ▓Ģ)ņŚÉ Ļ▒Ėļ”¼ļŖö ņŗ£Ļ░äņØä ļłäņĀüĒĢśņŚ¼ ņ┤Ø ĒöäļĀłņ×ä ņłś(30), ļ░śļ│Ą ņŗ£ļ«¼ļĀłņØ┤ņģś Ēܤņłś(500), ĻĘĖļ”¼Ļ│Ā ņČöņĀüĒĢäĒä░ ņłśļĪ£ ļéśļłäņ¢┤ ņĖĪņĀĢņŻ╝ĻĖ░(50 ms)ņŚÉ ļīĆĒĢ£ ĒÅēĻĘĀ ņŚ░ņé░ņåŹļÅäļź╝ ņé░ņČ£ĒĢśņśĆļŗż.
Table┬Ā1.
Average calculation speed per frame for each algorithm[ms]
| SNR | lv 0 | lv 1 | lv 2 | lv 3 | lv 4 | LM-IPDA |
|---|---|---|---|---|---|---|
| 13 dB | 0.016 | 0.018 | 0.064 | 0.353 | 2.053 | 0.018 |
| 20 dB | 0.015 | 0.016 | 0.034 | 0.116 | 1.212 | 0.016 |
LM-IPDA-AIņÖĆ iJIPDA-AI level 0ļČĆĒä░ 3Ļ╣īņ¦ĆļŖö Table 1Ļ│╝ Ļ░ÖņØ┤ ņĢłņĀĢņĀüņ£╝ļĪ£ ņŗżņŗ£Ļ░ä ņŚ░ņé░ņØ┤ Ļ░ĆļŖźĒĢśņśĆņ¦Ćļ¦ī, ĒŖ╣ņĀĢ ļ¬¼Ēģīņ╣╝ļĪ£ ņŗ£ļ«¼ļĀłņØ┤ņģśņŚÉ Full LevelņØĆ ļÅÖņ×æņØ┤ ļ®łņČöļŖö ĒśäņāüņØ┤ ļ░£ņāØĒĢśņśĆĻ│Ā, ĒĢ┤ļŗ╣ ļ¬¼Ēģīņ╣╝ļĪ£ ņŗ£ļ«¼ļĀłņØ┤ņģśņØä ņĀ£ņÖĖĒĢ£ ĒÅēĻĘĀ ņŚ░ņé░ņåŹļÅäļŖö 52.821 msņØ┤ļ®░ ņĖĪņĀĢņŻ╝ĻĖ░ T = 50 msņØĖ ĒÖśĻ▓ĮņŚÉņä£ ņŗżņŗ£Ļ░ä ņŚ░ņé░ņØ┤ ļČłĻ░ĆļŖźĒĢ©ņØä ĒÖĢņØĖĒĢśņśĆļŗż. Ēæ£ņĀüņØ┤ 5Ļ░£ņØĖ ĒÖśĻ▓ĮņŚÉņä£ ņØ┤ļĪĀņāü iJIPDA-AI Level 4ņÖĆ Full LevelņØĆ ļÅÖņØ╝ĒĢ£ ņä▒ļŖźĻ│╝ ņŚ░ņé░ņŗ£Ļ░äņØä Ļ░¢ņ¦Ćļ¦ī Ēü┤ļ¤¼Ēä░ņŚÉ ņØśĒĢ┤ ņāØņä▒ļÉ£ ĒŖĖļ×ÖļōżņØ┤ ņĪ┤ņ×¼ĒĢĀ Ļ▓ĮņÜ░ Ēü┤ļ¤¼ņŖżĒä░ ļé┤ņŚÉ ĒŖĖļ×ÖņØś ņłśĻ░Ć 5Ļ░£ļ│┤ļŗż ļ¦ÄņĢäņ¦Ćļ®┤ Full LevelņØś ņŚ░ņé░ņŗ£Ļ░äņØ┤ ļ¦ÄņĢäņ¦ĆĻ▓ī ļÉ£ļŗż. Ēæ£ņĀüņØ┤ ĻĘ╝ņĀæ ĻĄÉņ░©Ļ░Ć ņØ┤ļŻ©ņ¢┤ņ¦ĆļŖö 9 ļ▓łņ¦Ė ĒöäļĀłņ×äņŚÉņä£ļŖö ĒĢ£ Ēü┤ļ¤¼ņŖżĒä░ ļé┤ņØś ĒŖĖļ×ÖņØ┤ 10Ļ░£, ņĖĪņĀĢņ╣śĻ░Ć 28Ļ░£Ļ╣īņ¦Ć ļ░£ņāØĒĢśļŖö Ļ▓ĮņÜ░Ļ░Ć ņāØĻ▓╝ņ£╝ļ®░, ĒĢ┤ļŗ╣ ņŗ£ņĀÉņŚÉņä£ ĒĢ£ Ļ░£ņØś ņĖĪņĀĢņŻ╝ĻĖ░ņŚÉ ņåīņÜöļÉśļŖö Ļ│äņé░ ņŗ£Ļ░äņØ┤ Level 4ļŖö 51.283 ms, Full LevelņØĆ 1429.32 msļź╝ Ļ░Ćņ¦Ćļ®░ ņŗżņŗ£Ļ░ä Ļ│äņé░ņØ┤ ļČłĻ░ĆļŖźĒĢ©ņØä ĒÖĢņØĖĒĢśņśĆļŗż.
Ļ▓░ ļĪĀ
ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ļŖö ļé«ņØĆ SNRņØä Ļ░¢ļŖö ļŗżņłśņØś Ēæ£ņĀüņŚÉ ļīĆĒĢ£ Ēæ£ņĀüņČöņĀü ĻĖ░ļ▓Ģņ£╝ļĪ£ iJIPDA-AI ĻĖ░ļ▓ĢņØä ņĀ£ņĢłĒĢśņśĆļŗż. Ēæ£ņĀüņØś SNRņØ┤ ļé«ņØĆ ĒÖśĻ▓ĮņŚÉņä£ Ēæ£ņĀüņØĆ ņŗĀĒśĖņĀüņ£╝ļĪ£ Ēü┤ļ¤¼Ēä░ņÖĆ ĻĄ¼ļ│äņØ┤ ņ¢┤ļĀĄĻ│Ā, ņØ╝ļ░śņĀüņØĖ Ēæ£ņĀü ĒāÉņ¦ĆĻ│╝ņĀĢņØä Ļ▒░ņ╣Ā Ļ▓ĮņÜ░ ņĖĪņĀĢņ╣ś ņČöņČ£ Ļ│╝ņĀĢņŚÉņä£ ņŗĀĒśĖņäĖĻĖ░ ļ¼ĖĒä▒Ļ░ÆņŚÉ ņØśĒĢ┤ Ēæ£ņĀüņØś ņĀĢļ│┤ļź╝ ņ×āņØä ņłś ņ׳ļŗż. ņØ┤ļ¤¼ĒĢ£ ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢśĻĖ░ ņ£äĒĢ£ TBD ņĢīĻ│Āļ”¼ņ”śņØĆ ņŗĀĒśĖņ▓śļ”¼ļź╝ Ļ▒░ņ╣śņ¦Ć ņĢŖņØĆ ņä╝ņä£ņØś ļŹ░ņØ┤Ēä░ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ļé«ņØĆ SNR Ēæ£ņĀü ĒÖśĻ▓ĮņŚÉņä£ļÅä ņÜ░ņłśĒĢ£ ĒāÉņ¦Ć ļ░Å ņČöņĀü ņä▒ļŖźņØä Ļ░¢ņ¦Ćļ¦ī ņŚ¼ļ¤¼ ņŚ░ņåŹ ĒöäļĀłņ×äļōżņØä ļÅÖņŗ£ņŚÉ ņ▓śļ”¼ĒĢśļŖö ļ░®ņŗØņØä ĻĖ░ļ░śņ£╝ļĪ£ ĒĢśņŚ¼ ļŹ░ņØ┤Ēä░ļź╝ ņłśņ¦æĒĢśļŖö ĻĄ¼Ļ░äļ¦īĒü╝ ĒāÉņ¦Ć ļ░Å ņČöņĀü ņŗ£ņĀÉņØ┤ ļŖ”ņ¢┤ņ¦äļŗż. ļö░ļØ╝ņä£ ņśżĻ▓Įļ│┤ ĒÖĢļźĀņØä ņĪ░ņĀłĒĢśņŚ¼ ļåÆņØĆ ļ░ĆļÅäļĪ£ Ēü┤ļ¤¼Ēä░Ļ░Ć ļ░£ņāØĒĢśņ¦Ćļ¦ī Ēæ£ņĀüņČöņĀüņØ┤ Ļ░ĆļŖźĒĢ£ ņłśņżĆņØś Ēæ£ņĀü ĒāÉņ¦ĆĒÖĢļźĀņØä Ļ░¢ļŖö ĒÖśĻ▓ĮņŚÉņä£ ņ×ÉļŻīĻ▓░ĒĢ®ĻĖ░ļ▓ĢņØä ņĀüņÜ®ĒĢśĻ│Āņ×É ĒĢśņśĆļŗż. ļīĆĒæ£ņĀüņØĖ ļŗżņżæĒæ£ņĀü ņČöņĀüĻĖ░ļ▓Ģ JIPDAļŖö ĒŖĖļ×ÖĻ│╝ ņĖĪņĀĢņ╣ś ņé¼ņØ┤ņØś ļ░£ņāØ Ļ░ĆļŖźĒĢ£ ļ¬©ļōĀ ņé¼Ļ▒┤ļōżņŚÉ ļīĆĒĢśņŚ¼ ņ×ÉļŻīņŚ░Ļ┤ĆņØä ņłśĒ¢ēĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ ĻĘ╝ņĀæĒĢ£ Ēæ£ņĀüĻ│╝ ņĖĪņĀĢņ╣śņØś Ļ░£ņłśņŚÉ ļö░ļØ╝ ņŚ░ņé░ļ¤ēņØ┤ ĻĖēĻ▓®ĒĢśĻ▓ī ņ”ØĻ░ĆĒĢśņŚ¼ ņŗżņĀ£ ĒÖśĻ▓ĮņŚÉ ņĀüņÜ®ņØ┤ ņ¢┤ļĀĄĻĖ░ ļĢīļ¼ĖņŚÉ ņ×¼ĻĘĆņŚ░ņé░ ĒܤņłśņŚÉ ļö░ļØ╝ ņä▒ļŖźĻ│╝ ņŚ░ņé░ļ¤ēņØä ņĪ░ņĀłĒĢĀ ņłś ņ׳ļŖö iJIPDA ĻĖ░ļ▓ĢņØä ņĀ£ņĢłĒĢśņśĆļŗż. ļśÉĒĢ£ ļåÆņØĆ ļ░ĆļÅäņØś Ēü┤ļ¤¼Ēä░Ļ░Ć ņĪ┤ņ×¼ĒĢśļŖö ĒÖśĻ▓ĮņŚÉņä£ Ēæ£ņĀüņØś ņŗĀĒśĖņÖĆ Ēü┤ļ¤¼Ēä░ņØś ņŗĀĒśĖņŚÉ ļīĆĒĢ£ ļČäļ│äļĀźņØä ļåÆņØ╝ ņłś ņ׳ļÅäļĪØ ņČöņĀü ĒĢäĒä░ņØś ņćäņŗĀ ļŗ©Ļ│äņŚÉņä£ Ļ▒░ļ”¼ņĀĢļ│┤ļ┐É ņĢäļŗłļØ╝ ņŗĀĒśĖņäĖĻĖ░ ņĀĢļ│┤ļÅä ĒÖ£ņÜ®ĒĢśņśĆļŗż. ņŗ£ļ«¼ļĀłņØ┤ņģś ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņĀ£ņĢłĒĢśļŖö ņĢīĻ│Āļ”¼ņ”śņØś ņä▒ļŖź ļČäņäØņØä ņ£äĒĢ┤ SNR 13, 20 dB ĒÖśĻ▓ĮņŚÉņä£ 5Ļ░£ņØś Ēæ£ņĀüņØ┤ ĻĘ╝ņĀæĒĢśņŚ¼ ĻĄÉņ░©ĒĢśļŖö ĒÖśĻ▓ĮņŚÉņä£ Ēæ£ņĀüņČöņĀüņØä ņłśĒ¢ēĒĢśņśĆļŗż. ņČöņĀü ņä▒Ļ│ĄļźĀĻ│╝ ņČöņĀü ņĀĢļ░ĆļÅäļź╝ ļéśĒāĆļé┤ļŖö ņ¦ĆĒæ£ņØĖ CTTņÖĆ RMSEņŚÉ ļīĆĒĢ£ Ļ▓░Ļ│╝ļź╝ ĒÖĢņØĖĒĢśņśĆņ£╝ļ®░, ļŗ©ņØ╝Ēæ£ņĀüņČöņĀü ĻĖ░ļ▓ĢņØĖ IPDAņÖĆ ļÅÖņØ╝ĒĢ£ ņä▒ļŖźņØä Ļ░¢ļŖö iJIPDA-AI Level 0ņØś ņä▒ļŖźņØ┤ Ļ░Ćņן ļ¢©ņ¢┤ņ¦ĆĻ│Ā LevelņØ┤ ņśżļź╝ņłśļĪØ ņČöņĀü ņä▒ļŖźņØ┤ ļø░ņ¢┤ļé©ņØä ĒÖĢņØĖĒĢśņśĆļŗż. ļśÉĒĢ£ iJIPDA-AIņØś Level ļ│ä ņŚ░ņé░ņåŹļÅäļź╝ ļČäņäØĒĢśņŚ¼ ĒĢ┤ļŗ╣ ņŗ£ļ«¼ļĀłņØ┤ņģś ĒÖśĻ▓ĮņŚÉņä£ Level 3ņØ┤ ņĢłņĀĢņĀüņ£╝ļĪ£ ņŗżņŗ£Ļ░ä ņŚ░ņé░ņØ┤ Ļ░ĆļŖźĒĢśļ®░ ņČöņĀü ņä▒ļŖźļÅä ņÜ░ņłśĒĢ©ņØä ĒÖĢņØĖĒĢśņśĆļŗż.




