



1. 서 론
최근 로봇 및 드론 제어 기술의 발달을 바탕으로 무인 수색 차량, 드론, 4족 보행 로봇과 같이 첨단 기술이 적용된 군용 장비들이 도입되고 있다. 특히, 4족 보행 로봇이나 드론의 경우 기존 인적 자원의 활용이 제한된 전장 지형 및 환경에서도 사용 가능하다는 점에서 많은 주목을 받고 있다[1–4]. 이러한 장비들은 무인 작전 수행 및 지휘를 위해 내장된 센서를 이용하여 표적 및 장애물에 대한 상태(위치/속도)를 측정하고, 이들에 대한 동적 움직임을 예측 및 추정할 필요가 있다. 하지만, 아무리 정밀한 센서를 사용하더라도 관측 환경 및 시스템으로부터 기인한 잡음으로 인해 센서 데이터가 왜곡될 수 있다. 따라서 측정된 센서 신호에 대하여 잡음을 제거하고 이를 바탕으로 표적 및 장애물에 대한 상태를 정확히 예측 및 추정하는 기술은 매우 중요하다.
Rudolf Kalman이 최초로 제안한 칼만 필터(Kalman Filter)는 잡음이 포함되어있는 동적 시스템의 측정값을 이용하여 그것의 상태(위치 및 속도)를 추정하는 재귀 필터다. 칼만 필터의 경우 측정하고자 하는 상태 공간의 동적 시스템이 선형이고 잡음이 가우시안(Gaussian) 분포를 따른다는 가정을 만족하면 칼만 필터는 측정 오차의 제곱을 최소화하는 최적의 상태 추정 및 예측 결과를 제공한다. 하지만 앞선 두 가지 가정을 만족하지 않는 경우 칼만 필터의 사용은 제한적이라는 단점이 존재한다. 이러한 문제를 해결하기 위해 확장 칼만 필터(EKF, Extended Kalman Filter)와 무향 칼만 필터(UKF, Unscented Kalman Filter), 파티클 필터(Particle Filter) 등의 다양한 방법들이 제시되고 있다[4–7].
앞에서 언급한 칼만 필터, 확장 칼만 필터, 무향 칼만 필터, 파티클 필터 방법들은 모두 상태 공간에 정의된 동적 시스템에 대한 정확한 정보 또는 가정이 필요하다. 따라서 부정확한 동적 시스템 모델에 대해서는 최적의 상태 예측 및 추정 정보를 제공할 수 없다. 또한 동적 시스템의 잡음이 가우시안 분포를 따르지 않는 경우도 최적의 상태 예측 및 추정 결과를 기대할 수 없다. 즉, 기존의 (선형, 확장, 무향 등의) 칼만 필터는 동적 시스템 모델과 잡음 모델에 대한 의존성이 크기 때문에 이들의 정보가 불확실한 경우 정확한 예측 및 추정 성능을 기대할 수 없다.
본 논문에서는 불확실한 동적 시스템 모델 및 잡음 정보에 대해서도 강인하고 최적의 상태 예측 및 추정 성능을 제공할 수 있는 순환 신경망(RNN, Recurrent Neural-Network) 기반 칼만 필터 설계 방법을 제안한다.
최근 딥러닝 및 인공지능 분야의 발달로 인해 데이터 분류 및 예측 등의 다양한 활용 기술들이 개발되고 있다[8,9]. 특히, 주식이나 기상 예측 등의 분야에서, 과거의 데이터를 기반한 예측 모델 설계 연구가 활발히 이루어지고 있다. 이들 분야의 경우 일반적으로 정확한 시스템 모델을 설계하기 어렵기 때문에 수식을 통한 정확한 상태 예측 및 추정 결과를 얻기는 어렵다. 최근 신경망 기술의 도입으로 과거의 데이터를 바탕으로 예측을 수행하는 다양한 방법들이 연구되고 있다. 특히, 순환 신경망은 앞서 제시된 데이터와 같은 시계열 데이터를 다루는 문제에 유용하게 적용할 수 있는 기술이다. 순환 신경망의 경우 기존의 신경망 구조와 달리, 이전의 학습된 은닉층의 가중치 정보를 다음 데이터의 학습에 참고하여 모델의 특성을 정확히 학습할 수 있다는 장점이 있다[10–12].
순환 신경망의 특성을 이용하여 앞에서 언급된 칼만 필터의 한계점을 보완하기 위한 다양한 연구가 진행되고 있다[13–16]. 가우시안 잡음을 따르지 않는 모델에 대해 순환 신경망을 적용한 뒤 칼만 필터를 적용하는 연구[13], 순환 신경망을 이용하여 가공된 데이터에 대해 칼만 필터를 적용하는 연구[14], 그리고 무향 칼만 필터(UKF)와 순환 신경망을 결합하여 비선형 모델의 추정 성능을 높이는 연구[15] 등 다양한 방법들이 제안되었다. 선행연구[16]에서는 GRU(Gated Recurrent Unit)[17] 기반의 순환 신경망 기반 칼만 필터 설계를 제안하였고, 동적 시스템 모델 및 잡음 정보가 부정확한 경우에도 높은 상태 추정 성능을 보여주었다. 선행연구[16]는 앞서 언급된 선행연구들[13–15]과 비교하였을 때, 시스템 및 잡음 정보가 부정확한 상황에서도 최적의 칼만 필터 설계를 고려하고 있다.
본 논문에서는 선행연구[16]에서 제안된 GRU 기반 칼만 필터 설계 방법보다 더 향상된 동적 시스템 상태 추정 성능을 얻을 수 있는 GRU-LSTM(Long Short- Term Memory) 기반 칼만 필터 설계 방법을 제안한다. 일반적으로 LSTM[18]은 GRU[17]에 비해 많은 파라미터를 가지고 있어 복잡한 비선형 시스템에 대한 정확한 학습이 가능하지만, 학습 시간이 길어지거나 과적합 문제에 취약하다는 단점이 있다[19,20]. 반면 GRU의 경우 LSTM보다 간단한 내부 구조를 갖고 있기 때문에 더 빠르게 학습이 가능하다는 장점이 있다[21]. 본 논문에서 제안하는 GRU-LSTM 신경망 기반 칼만 필터 설계 방법의 경우 앞에서 언급한 GRU와 LSTM 장점들을 반영할 수 있기 때문에 선행연구[16]보다 향상된 동적 시스템 상태 추정 성능을 얻을 수 있다. 또한 본 논문에서 제안하는 방법의 경우 GRU[16]/LSTM 단일 신경망 기반 칼만 필터, 그리고 GRU-GRU, LSTM- LSTM, LSTM-GRU 신경망 기반 칼만 필터보다 높은 학습 정확도를 보여주고 있고, 부정확한 동적 시스템 모델 및 잡음 정보에 대해서도 향상된 상태 추정 결과를 얻을 수 있다(4장 모의실험 결과 참조).
제안된 GRU-LSTM 기반 칼만 필터의 신경망은 칼만 필터의 업데이트 오차와 잔차를 입력으로 하여, 입력층(Input Layer)인 Feature Input Layer를 지나 GRU 은닉층(Hidden Layer)과 LSTM 은닉층을 지나게 된다. 은닉층을 통과한 데이터는 완전 연결층(Fully Connected Layer)를 거쳐, 입력 값에 해당하는 칼만 이득을 반환하는 구조이다. 본 논문에서 제안하는 순환 신경만 기반 칼만 필터 알고리즘은 칼만 이득을 이용하여 업데이트한 예측값과 데이터의 측정값의 2-norm을 손실 함수로 지정하여, 이 값을 최소화할 수 있도록 신경망 파라미터들을 업데이트한다. 즉, 측정된 값과 신경망 알고리즘을 통해 업데이트한 값과의 오차를 줄여나갈 수 있도록 학습함으로써 학습 기반의 최적 칼만 이득을 얻을 수 있고, 이를 통해 칼만 필터의 상태 예측 및 추정 성능을 향상시킨다. 따라서 본 논문에서 제안하는 순환 신경망 기반 칼만 필터는 기존의 칼만 필터와는 달리 설계된 GRU-LSTM 신경망으로부터 학습된 칼만 이득을 이용하여 부정확한 동적 시스템 모델 및 잡음 정보에 대해서도 강인하고 최적화된 표적 상태 예측 및 추정 성능을 얻을 수 있다.
본 논문에서는 제안하는 순환 신경망 기반 칼만 필터 알고리즘을 검증하기 위해, 레이더 표적 추적 시스템, 비선형 로렌츠 모델, 비선형 드론 시스템인 쿼드로터(Quadrotor)에 적용하여 상태 예측 및 추정 모의실험을 수행한다. 선형기반 레이더 추적 모델에 대한 모의실험 경우 선형 칼만 필터와 제안된 GRU-LSTM 신경망 기반 칼만 필터와 비교를 수행한다. 비선형 시스템에 대한 모의실험의 경우 확장 칼만 필터와 제안하는 GRU-LSTM 신경망 기반 칼만 필터와의 비교를 수행한다. 또한, 각 모의실험에는 GRU[16]/LSTM 단일 신경망 기반 칼만 필터, 그리고 GRU-GRU, LSTM-LSTM, LSTM-GRU 신경망 기반 칼만 필터와의 비교를 수행한다. 이들의 비교를 통해 본 논문에서 제안하는 GRU-LSTM 신경망 기반 칼만 필터가 비교하는 방법들 대비 가장 높은 학습 정확도를 보여주고 있고, 부정확한 동적 시스템 및 잡음 정보에 대해서도 상태 추정 오차가 가장 낮은 것을 확인할 수 있다.
본 논문의 구성은 다음과 같다. 2장에서는 기존의 선형 및 확장 칼만 필터 알고리즘을 설명한다. 3장에서는 본 논문에서 제안하는 순환 신경망 기반의 칼만 필터 구조와 학습에 사용된 데이터 셋, 학습 방법을 설명한다. 4장에서는 선형 모델과 비선형 모델에 대해 제안하는 칼만 필터의 성능 분석을 수행한다. 5장에서는 본 논문의 결론과 향후 연구 주제를 소개한다.
2. 칼만 필터
본 장에서는 칼만 필터에 대한 간단한 소개와 알고리즘을 설명하고, 비선형 모델에서의 적용 방법과 문제점 등을 설명한다[5].
칼만 필터를 설계하기 위해서는 아래와 같은 동적 시스템 모델이 필요하다:
여기서 wt ∼ N(0,Q)와 vt ∼ N(0,R)는 동적 시스템 (1)에 대한 잡음이고, 가우시안 분포를 따르며 각각 공분산 Q와 R을 갖고 있다. 식 (1)의 동적 시스템에서 xt ∈ℝ n 는 시간 t = 0, 1, … 에서의 상태 벡터를 의미하며, yt∈ℝp 는 xt를 통해서 관측되는 측정값을 의미한다. 식 (1)에서 f와 h는 각각 동적 시스템 (1)의 모델 정보를 표현하는 함수로서 칼만 필터를 적용하는 상태 추정 및 예측 문제마다 다를 수 있다.
만일 식 (1)이 선형 시스템으로 표현된다면 아래의 모델로 간략화될 수 있다:
이때 F는 n × n 정방 행렬이고 H 는 p × n 행렬이다. 선형 시스템 식 (2)에 대한 칼만 필터의 예측 단계는 다음과 같이 표현된다:
Prediction (예측):
식 (3)에서 x ^ t | t − 1
칼만 필터의 업데이트 단계에서는 앞서 예측 단계를 통해 계산한 추정값과 실제 측정값 간의 오차를 이용하여, 칼만 이득을 계산하고 이전에 얻은 값들을 귀납적으로 보정 한다. 아래의 식들은 칼만 필터 업데이트 과정을 수식으로 나타낸 것이다:
식 (4)에서 Δyt 는 실제 측정값과 추정값 간의 잔차를 의미하고, St 는 잔차의 공분산을 의미한다. Kt는 칼만 이득으로 측정값과 상태 공분산의 보정을 위해 사용되는 상숫값이다. 보정을 하기 위한 식은 다음과 같다:
Update (업데이트):
식 (3)-(5)은 선형 시스템 (2)에 대한 칼만 필터 알고리즘이다. 하지만 모든 예측 및 추정 문제들이 선형 시스템으로 표현되는 것은 아니다[1–5]. 따라서 식 (1)과 같이 비선형 동적 시스템에 대한 예측 및 추정을 수행해야 한다. 이 경우 확장 칼만 필터(EKF)가 사용된다. 확장 칼만 필터는 비선형성을 띤 함수에 대해 테일러 전개에 의한 미분을 적용하여 아래의 자코비안(Jacobian) 행렬을 구함으로써, 식 (1)을 선형화한다:
식 (6)에서 F는 n × n 자코비안 정방 행렬이고 H는 p × n 자코비안 행렬이다. 식 (6)과 같이 테일러 전개를 통한 함수를 미분하여 비선형 모델에서도 선형 모델처럼 칼만 필터를 적용할 수 있다는 장점이 있으나, 정확한 동적 시스템 모델 정보를 사용하는 것이 아니므로 정확한 칼만 필터의 예측 및 추정 성능을 기대하기 어렵다. 또한, 식 (1)의 비선형성이 높을수록 식 (6)의 테일러 전개 선형 근사화의 정확성이 줄어들기 때문에 확장 칼만 필터를 적용하여도 상태 예측 및 추정이 어려운 경우도 존재한다. 마지막으로 식 (1)에서 확률 잡음에 대한 정확한 공분산 값을 얻는 것은 현실적으로 불가능하다. 본 논문에서는 이와 같은 칼만 필터 설계 시 불완전한 정보가 주어진 상황에서도 강인하고 최적의 상태 예측 및 추정 성능을 얻을 수 있는 순환 신경만 기반 칼만 필터를 제안한다.
3. 신경망 기반 칼만 필터 설계
시스템 분야에서의 인공지능 및 머신 러닝 기술은 시스템에 대한 수식적 모델을 구체화하기 어려운 경우 학습 데이터를 통해 시스템 모델을 예측 및 추정하는 방법으로 연구가 진행되고 있다. 순환 신경망은 이러한 머신 러닝 알고리즘의 구현을 위한 방법 중 한 종류로서, 대표적으로 LSTM과 GRU의 구조가 사용되고 있다. 1장 서론에서 언급했듯이 GRU는 LSTM 보다 간단한 구조로 구성되어있고 따라서 빠른 학습이 가능하다는 장점이 있다[21]. 반면 LSTM의 경우 다수의 내부 파라미터에 의해 복잡한 모델에 대해서도 정확한 학습이 가능하다는 장점이 있지만, 동시에 학습의 과적합이 발생할 수 있는 위험이 있다[19,20]. 본 논문에서는 GRU의 단순한 구조로 인한 빠른 연산 속도와 LSTM의 정확성을 이용하여 두 모델을 결합한 GRU-LSTM 신경망 기만 칼만 필터를 제안한다. 제안하는 방법에서 데이터는 GRU를 먼저 통과함으로써 학습 속도를 높이고 LSTM을 통해 정확한 학습이 되도록 설계하였다. 제안된 GRU-LSTM의 정량적인 성능에 관한 내용은 4장의 모의실험 결과를 통해 확인할 수 있다. 본 논문의 GRU-LSTM 기반의 칼만 필터는 기존의 칼만 필터와는 달리 부정확한 동적 시스템 모델 및 잡음 정보에 대해서도 강인하고 최적화된 표적 상태 예측 및 추정 성능을 얻을 수 있다.
3.1 GRU-LSTM 신경망 기반 칼만 필터 구조
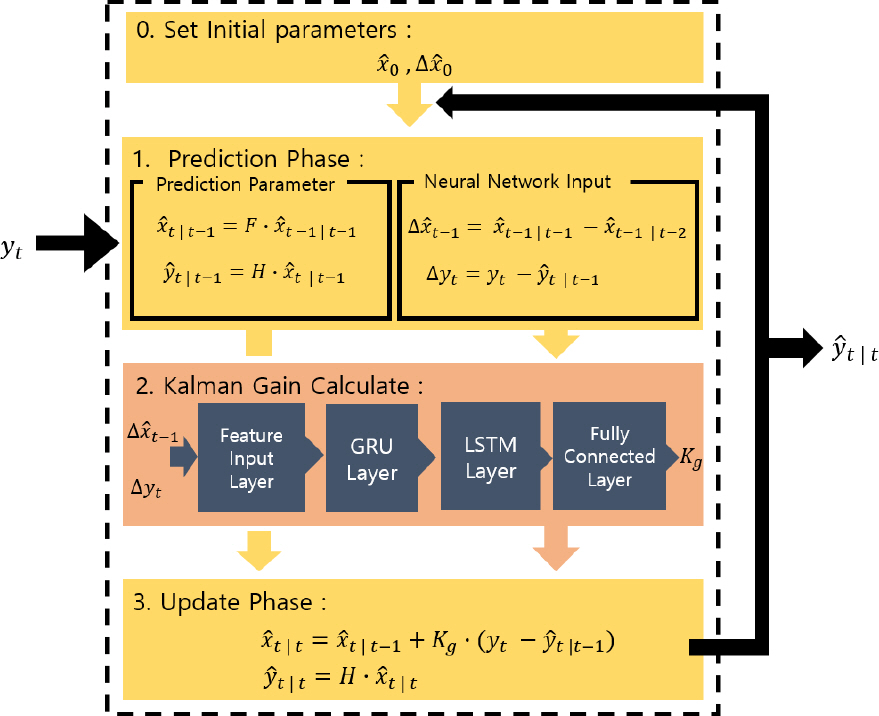
3.2 GRU – LSTM 신경망 구조
Fig. 2는 본 논문에서 제안하는 GRU-LSTM 기반 신경망 구조이다. Fig. 2는 Fig. 1에서 2번 Kalman Gain Calculate를 나타낸다. Fig. 2에서 입력값은 업데이트 오차와 측정값에 대한 잔차이고, 이들의 입력이 첫 번째 은닉층인 GRU로 입력되며, 다음으로 LSTM을 지나는 구조로 구성되어있다. 은닉층을 모두 지난 데이터는 완전 연결층으로 구성된 출력층에서 칼만 이득의 형태로 반환되게 된다. Fig. 3은 Fig. 2에서 GRU 내부 구성을 나타낸다. GRU는 xt로 정의된 입력 데이터와 ht - 1 로 정의된 직전의 가중치 정보를 이용하여 현재 가중치를 업데이트한다. Fig. 3의 초기화 구역에서는 설정된 메모리 길이에 따라 저장된 데이터들을 삭제하는 기능을 제공하며, 업데이트 영역에서는 현재 데이터들을 메모리에 저장하는 기능을 제공한다.
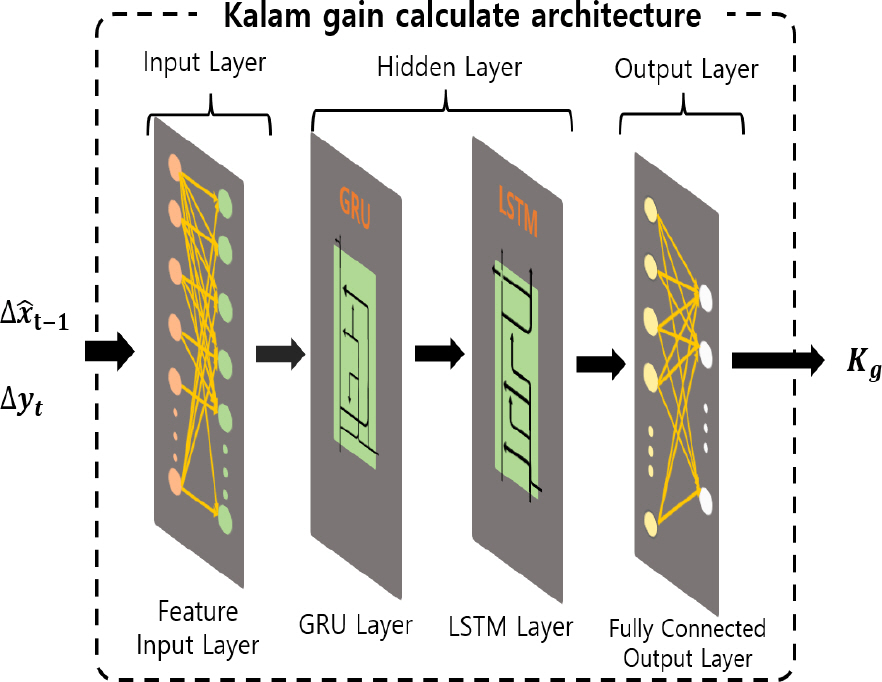

GRU의 은닉 크기(Hidden Size), 입력 크기(Input Size), 층(Layer)의 개수는 과적합이 일어나지 않고 빠르게 학습할 수 있는 적절한 범위의 값을 선정해야 한다. 본 논문에서는 다수의 실험을 통해 상태 변수 x ^ t y ^ t
Fig. 2에서 LSTM 역시, GRU와 마찬가지로 순환 신경망이 가지고 있던 기울기 소실과 같은 문제를 해결하기 위해 고안된 구조이다. Fig. 4는 Fig. 2의 LSTM 내부 구성을 나타낸다.
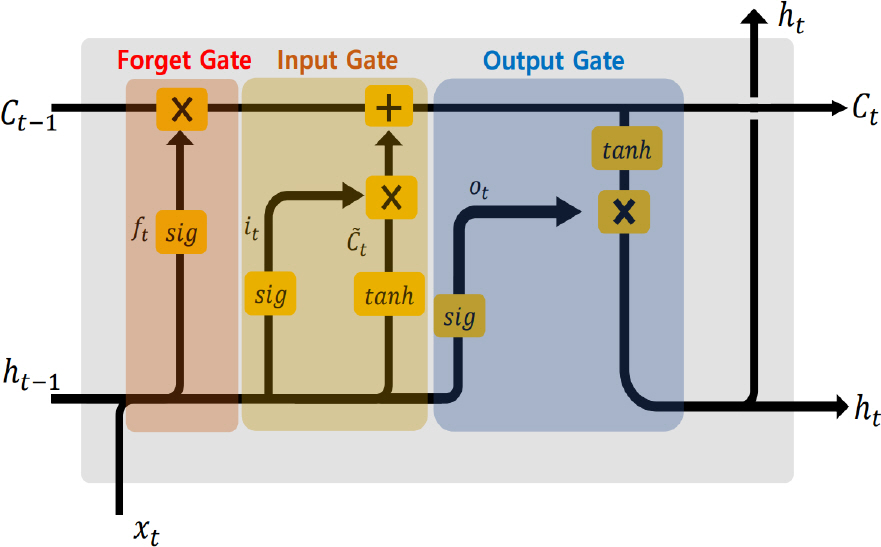
Ct는 셀 정보로 이전의 입력된 데이터를 저장하여 전달하는 역할을 하며, 망각 영역(Forget Gate)에서는 저장된 정보 중 삭제할 데이터를 결정하는 역할을 한다. 입력 영역(Input Gate)에서는 새롭게 저장할 데이터와 망각 영역에서 전달한 삭제 데이터 정보를 바탕으로 셀 정보를 업데이트한다. 마지막으로, 출력 영역(Output Gate)에서는 업데이트된 셀 정보 Ct 와 출력값 ht 를 반환하는 구조다. GRU와 마찬가지로, 본 논문에서는 LSTM의 은닉 크기를 6(p2 + n2)으로 선정하였다. LSTM의 입력 크기(Input Size)는 GRU의 은닉 크기를 고려하여 6(p2 + n2)으로 설정하였다. 또한, LSTM 층의 개수도 GRU와 동일하게 1로 설정하였다.
3.3 학습 데이터 셋
Fig. 1에서의 칼만 이득은 Fig. 2의 GRU-LSTM 신경망을 통해 얻을 수 있다. 이때 3.2장에서의 GRU-LSTM 신경망 구성과 함께 중요한 사항은 학습에 필요한 입력 데이터 셋에 대한 구성이다. 본 논문에서는 2장의 칼만 이득과의 연관성을 고려하여 상태 추정값인 x ^ t
1) 업데이트 오차 Δ x ^ t = x ^ t | t − x ^ t | t − 1
현재 업데이트 상태 추정값과 예측 상태 추정값 간의 오차를 나타낸 값. 알고리즘에서는 Δ x ^ t − 1
2) 잔차 Δ y t = y t − y ^ t | t − 1
현재 추정값과 실제 측정값 간의 오차값을 사용.
데이터 셋 1)과 2)는 업데이트 오차와 측정값만으로 얻을 수 있고, 2장에 일반적인 칼만 필터 설계에 필요한 칼만 이득 및 공분산 정보는 필요 없다.
3.4 학습 알고리즘
본 연구에서 제안하는 학습 알고리즘은 선행연구[16]에서 제안 방법과 유사하게 칼만 이득과 관측치에 대한 데이터를 기반으로 학습하는 지도 학습 영역에서의 알고리즘이다. 학습에 필요한 데이터들은 칼만 필터 알고리즘의 적용을 통해 얻을 수 있는 입력 변수들을 사용하였으며, 손실 함수의 계산은 아래의 식과 같다:
식 (7)에서 사용된 Xt는 학습 데이터에 필요한 데이터 셋으로 제안하는 신경망 기반 칼만 필터를 실제 표적 예측 및 추정 문제에 적용하기 전에 식 (1)을 이용하여 임의로 생성하는 데이터이다.
식 (7)에서 정의된 손실 함수를 칼만 이득 Kg 에 대해 미분하면 다음과 같은 식을 얻을 수 있다.
4. 모의실험
본 장에서는 3장에서 제안하는 GRU-LSTM 신경망 기반 칼만 필터에 대한 성능 검증을 수행한다. 또한 측정 데이터의 샘플링 주기 Ts 는 0.01 sec이다.
모의 실험은 아래의 4가지 조건에 대하여 수행한다:
1) 실험 I (Experiment I) : 선형 시스템 식 (2)의 정확한 데이터가 주어진 경우. 실험 I에서는 레이더 시스템에 대한 표적 위치 추적에 대한 모의실험을 수행.
2) 실험 II (Experiment II) : 선형 시스템 식 (2)에서 부정확한 F - Δ 가 주어진 경우(Table 1 참조). 실험 II는 실험 I와 동일하게 레이더 시스템에 대한 표적 위치 상태 추적에 대한 모의실험을 수행.
3) 실험 III (Experiment III) : 식 (1)의 비선형 로렌츠(Lorentz) 동적 시스템에 부정확한 f - Δ 가 주어진 경우에 대한 모의실험을 수행(Table 1 참조).
Table 1.
Parameters of KALMAN filter/EKF for experiments I-IV
실험 I-IV에 대한 자세한 변수 설정은 Table 1에 있다. 또한 3장에서 제안하는 GRU-LSTM 신경망 구성에 대한 변수 설정은 Table 2에 있다. 실험 I와 II는 선형 모델로서, 식 (2)와 같이 F와 H에 대한 모델로 표현될 수 있다. 두 실험에서 상태 변수는 [rt, vt, at]T로 각각 시간 t에서의 거리, 속도, 가속도 값을 의미한다. 실험 III과 IV는 비선형 동적 모델(식 (1) 참조)을 사용한 실험으로서, Table 1에 주어진 동적 모델 함수 f에 대하여 식 (6)과 같은 자코비안 행렬을 구하여, 확장 칼만 필터를 설계한다. 실험 III의 상태 변수는 로렌츠 함수의 상태 변수로, [x1,t, x2,t, x3,t]T 이다. 실험 IV의 상태 변수는 [ϕt, θt, ψt, ϕt, θt, ψt]T로 각각 시간 t에서의 roll, pitch, yaw의 각도 값과 각속도 값을 나타낸다. Table 1 실험 IV에서 [u1,t, u2,t, u3,t, u4,t]는 시간 t에서의 쿼드로터에 입력값으로서 Fig. 5의 Quanser Quadrotor 시뮬레이션에서 제공되는 제어 입력을 사용했다. Table 1 실험 II-IV에 있는 ∆는 부정확한 동적 시스템 모델 정보를 나타낸다. 따라서 모의실험에 적용되는 칼만 필터 설계에는 사용되지 않는다.

Table 2.
Hyperparameters of neural networks
Table 1에서 공분산 행렬값들은 칼만 필터와 확장 칼만 필터를 설계하기 위한 값이다. 3장에서 서술했듯이, 제안하는 GRU-LSTM 신경망 기반 칼만 필터의 경우 신경망을 기반으로 칼만 이득을 얻기 때문에 이러한 공분산 행렬값들은 필요 없다. 따라서 본 논문에서 제안하는 GRU-LSTM 신경망 기반 칼만 필터는 잡음에 대한 공분산 행렬 정보가 필요 없다.
본 논문에서 모의실험은 Python 및 PyTorch를 이용하여 Table 2의 변수를 이용하여 GRU-LSTM 신경망을 구현하였다. 실험 I-III은 Table 1에서 정의된 모델 및 변수들을 이용하여 식 (8)의 학습을 위한 임의의 데이터를 생성했다. 실험 IV의 경우 Fig. 5의 Quanser Quadrotor 장비를 통해 쿼드로터가 정지된 상태에서 자세의 변화에 대한 식 (8)의 데이터를 생성하였다. 실험 I-II는 칼만 필터(KF)와 단일 GRU[16]/LSTM 모델과 GRU-GRU, LSTM-LSTM, LSTM-GRU와 같은 혼합 모델 그리고 본 논문에서 제안하는 GRU-LSTM 모델을 사용했을 때의 성능을 검증하였고, 실험 III-IV의 경우 비선형 모델임을 고려하여 확장 칼만 필터를 적용하였고 실험 I-II와 동일하게 비교 모의실험을 진행했다. 단일 GRU 기반 칼만 필터의 경우 선행연구[16]를 참고했고, 단일 LSTM 기반 칼만 필터의 경우 선행연구가 없어서 직접 구현하였다. 성능 비교는 정량적인 비교를 위해 평균절대오차(MAE)와 평균제곱오차(MSE)를 기준으로 분석하였다.
Table 2는 모의실험에서 사용된 알고리즘들의 hyperparameter를 정리한 표이다. 각 모델의 은닉 크기와 입력 크기는 본 논문의 3.2장에서 제안한 구조와 동일하게 구성되었다. 제안하는 GRU-LSTM 신경망 구조는 GRU와 LSTM의 결합 구조이므로, 단일 구조보다 1개의 은닉층이 추가로 존재한다.
실험 I-IV의 결과는 Table 3에 요약되어 있다. Table 3을 통해서 알 수 있듯이, 제안하는 GRU-LSTM 신경망 기반 칼만 필터의 예측 및 추정 성능은 평균절대 오차(MAE)와 평균제곱오차(MSE) 기준으로 가장 우수한 성능을 보이고 있다. 실험 I의 경우 칼만 필터와 제안하는 GRU-LSTM 모델은 서로 비슷한 성능을 보이고 있는데, 이것은 실험 I의 경우 KF가 최적이므로, 이것의 추정 결과보다 더 좋을 수는 없기 때문이다. 따라서 제안하는 GRU-LSTM 모델이 KF와 비슷한 최적의 상태 추정 성능을 보이고 있다. Table 3의 결과를 통해서 제안하는 GRU-LSTM 기반의 칼만 필터를 이용하였을 때, 가장 정확한 표적 상태 추정 및 예측이 이루어졌음을 확인할 수 있다.
Table 3.
Results of experiments I-IV(실험 I-IV)
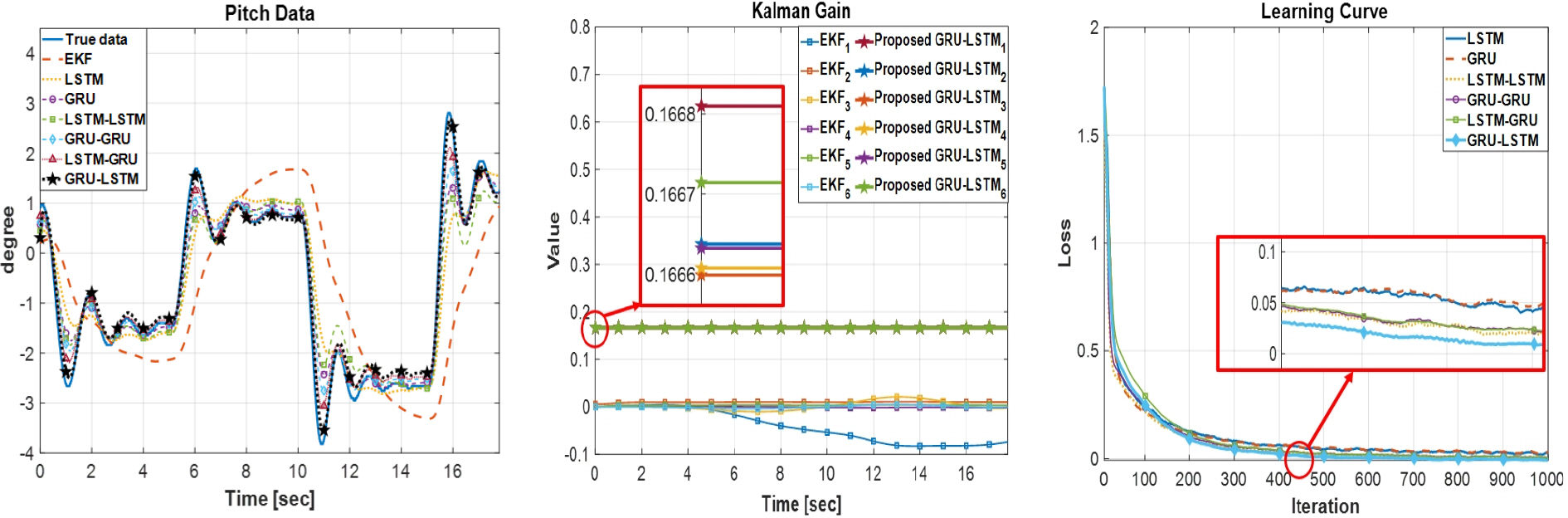
Fig. 6 - Fig. 9는 모의실험 I-IV에 대한 동적 시스템 상태 추정 결과, 칼만 이득, 그리고 학습 곡선을 나타낸 그림이다. Fig. 6 - Fig. 9 그리고 Table 3을 통해 알 수 있듯이 각각의 모의실험에서 본 논문에서 제안된 GRU-LSTM 신경망 기반의 칼만 필터가 평균절대오차/제곱오차 기준으로 가장 우수한 성능을 보여주고 있다.
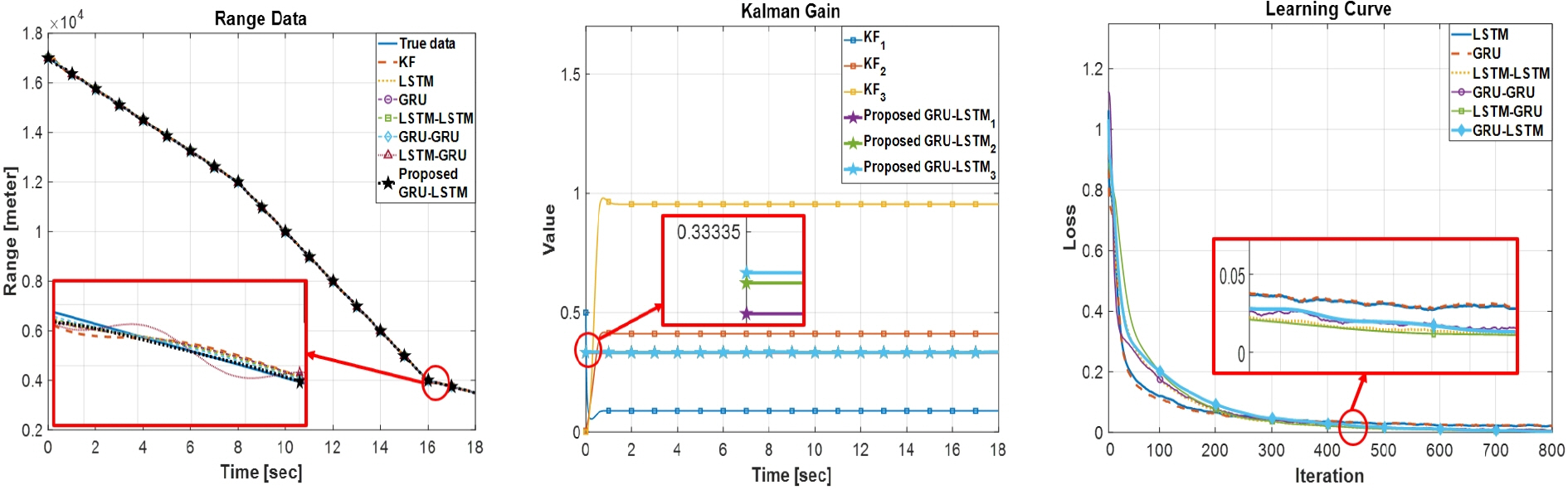
Fig. 6 - Fig. 7 그림에서 알 수 있듯이, LSTM-GRU 모델과 LSTM-LSTM 모델은 각각 실험 I과 II에서 다른 모델들보다 상태 추정 정확도가 낮은 구간이 존재한다. 따라서 LSTM-GRU 및 LSTM-LSTM 모델들은 GRU-GRU, GRU-LSTM 모델들보다 평균제곱오차가 더 큰 것을 확인할 수 있다. 또한 Fig. 6 - Fig. 7의 우측 학습 곡선에서 LSTM-LSTM 모델과 LSTM-GRU 모델은 본 논문에서 제안한 GRU-LSTM 모델보다 학습 정확성이 높은 것을 확인할 수 있다. 하지만, Table 3에서 알 수 있듯이, LSTM-LSTM과 LSTM-GRU 모델은 더 부정확한 상태 추정 성능을 보여주고 있다. 이러한 이유는 서론에서 언급하였듯이, 학습 과정 중 과적합이 발생한 것으로 판단된다. 반면, 본 논문에서 제안된 GRU-LSTM 모델은 단일 GRU/LSTM 모델들과 비교했을 때 다소 느리지만, 정확한 학습을 통해 우수한 상태 추정 성능을 보여주고 있다(Table 3 참조).
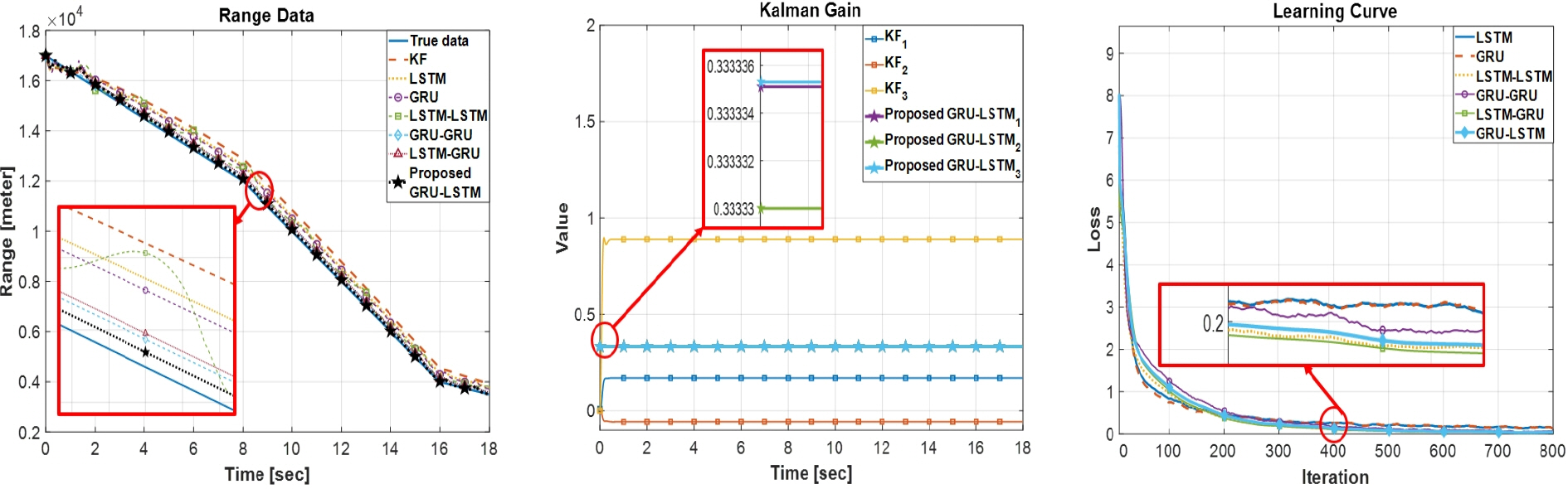
Fig. 8 - Fig. 9는 실험 III-IV에 대한 모의실험 결과로서 실험 I-II와 비슷한 경향을 보여주고 있다. 실험 IV(Fig. 9)의 경우, LSTM-LSTM 모델이 단일 LSTM 구조보다도 낮은 상태 추정 성능을 보여주고 있다. 이는 서론에서 언급한 LSTM-LSTM 모델의 복잡한 구조로 인한 과적합이 원인인 것으로 여겨진다.
Fig. 8.
Experiment III (left : state estimation of Lorenz model, middle : Kalman gain, right : learning curve)

5. 결 론
본 논문에서는 선행연구[16]에서 제안된 GRU 기반 의 칼만 필터 설계 방법을 개선하여 부정확한 정보가 주어진 상황에서도 동적 시스템 상태 추정 성능을 높일 수 있는 GRU-LSTM 신경망 기반 칼만 필터 설계를 제안했다. 본 논문에서는 제안하는 칼만 필터 알고리즘을 다양한 선형 및 비선형 동적 모델에 적용하여 성능의 우수성을 검증하였다. 특히 실험 IV와 같이 비선형성이 심한 쿼드로터에 대해서도 우수한 상태 예측 및 추정 성능을 보여주었다. 제안하는 GRU- LSTM 신경망 기반 칼만 필터의 가장 큰 장점은 정확한 동적 시스템 모델 및 잡음 정보가 필요 없다는 점이다. 따라서 동적 시스템 모델 및 잡음 정보를 얻기 어려운 다양한 표적 추적 문제에 적용될 수 있다. 향후 연구 계획으로는 실제 쿼드로터 실험에 제안하는 방법을 적용하여 쿼드로터 상태 추정에 활용할 계획이다.




