



ýäť Űíá
ÔĹá ŰőĄýľĹÝĽť ÝüČŕŞ░ýŁś ÝĹťýáü : ÝĹťýáü ÝâÉýžÇ ýłśÝľë ýőťýŚÉ ýäťŰíť ŰőĄŰąŞ ÝüČŕŞ░Űą╝ ŕ░Çýžä ÝĹťýáüýŁ┤ SAR ýśüýâü Űé┤ýŚÉ ýí┤ý×ČÝĽśŰŐö ŕ▓ŻýÜ░Űą╝ ýŁśŰ»ŞÝĽťŰőĄ. MSTAR Public SAR ÝĹťýáü ŰîÇŰ╣ä 0.6Ű░░ýŚÉýäť 1.5Ű░░ýŁś ŰőĄýľĹÝĽť ÝüČŕŞ░Űíť ÝĹťýáüýŁś ÝüČŕŞ░Űą╝ Ű│Çŕ▓ŻÝĽśýŚČ ŰŹ░ýŁ┤Ýä░ ýůőýŁä ŕÁČýä▒ÝĽťŰőĄ. ýŁ┤ŰŐö ÝĹťýáüýŁä ýäťŰíť ŰőĄŰąŞ GSD(Ground Sample Distance)ýŚÉýäť ÝÜŹŰôŁÝĽť ýśüýâüýŁś ŕ▓ŻýÜ░Űíť Ű│╝ ýłś ý׳ýť╝Űę░, ýŁ┤ŰčČÝĽť ýí░ŕ▒┤ýŚÉýäťŰĆä ÝĹťýáü ÝâÉýžÇŰą╝ ýłśÝľëÝĽá ýłś ý׳ŰŐöýžÇ ŕ▓ÇýŽŁÝĽťŰőĄ.
ÔĹí ŰőĄýľĹÝĽť ÝĹťýáü Ű░ÇýžĹ ýâüÝÖę : ýŚČŰčČ ýóůŰąśýŁś SAR ÝĹťýáüŰôĄýŁ┤ ýóüýŁÇ ŕ░äŕ▓ęýť╝Űíť Ű░ÇýžĹÝĽ┤ ý׳ŰŐö ŕ▓ŻýÜ░Űą╝ ýŁśŰ»ŞÝĽťŰőĄ. ŕ░ü ÝĹťýáüýŁś ŕ░äŕ▓ęýŁÇ ÝĆëŕĚáýáüýť╝Űíť ÝĹťýáüýŁś ÝüČŕŞ░Ű│┤ŰőĄ ý×Ĺýť╝Űę░ ýäťŰíť ŰőĄŰąŞ ÝĹťýáüýŁś ýśüýŚşýŁ┤ ŕ▓╣ý╣śýžÇ ýĽŐýť╝Űę┤ýäť ýÁťŰîÇÝĽť ŕ░Çŕ╣îýŁ┤ ýí┤ý×ČÝĽśŰŐö Ű░ÇýžĹ ýâüÝÖęŰĆä ýí┤ý×ČÝĽťŰőĄ.
ÔĹó ŕ│á(Úźś)Ýü┤ŰčČÝä░ ÝÖśŕ▓Ż : Ű│Ş Űů╝ŰČŞýŚÉýäť ýéČýÜęÝĽť ÝĹťýáü ÝâÉýžÇ ŰŹ░ýŁ┤Ýä░ ýůőýŁÇ ŕŞ░ýí┤ SAR ÝĹťýáü ÝâÉýžÇ ýĽîŕ│áŰŽČýŽśýŚÉýäť ýéČýÜęÝĽśŰŐö ÝĽ┤ýâü, ÝĆëýĽ╝ Űô▒ýŁś ŕ│áŰąŞ Ýü┤ŰčČÝä░ ÝÖśŕ▓Żŕ│╝ŰŐö ŰőČŰŽČ ŰĆäýőČýžÇ ŕ│áýŞÁ Ű╣îŰöę, ýł▓ Űô▒ýŁ┤ ýí┤ý×ČÝĽśŰŐö ŕ│á(Úźś)Ýü┤ŰčČÝä░ ÝÖśŕ▓ŻýŚÉýäť ÝÜŹŰôŁŰÉť SAR ýśüýâüýŁä ŕŞ░Ű│Şýť╝Űíť ÝĽťŰőĄ.
ÔĹú ŕ▒┤ŰČ╝ŕ│╝ ÝĹťýáü Ű░Çý░ę ýâüÝÖę : ŰĆäýőČýžÇ ŕ│á(Úźś)Ýü┤ŰčČÝä░ ÝÖśŕ▓ŻýŚÉ ÝĽ┤Űő╣ÝĽśŰŐö SAR ýśüýâüýŁś ŕ▓ŻýÜ░ ÝĹťýáüŕ│╝ ÝĹťýáü ýéČýŁ┤ýŁś ŕ░äŕ▓ęŰ┐ÉŰžî ýĽäŰőłŰŁ╝ ÝĹťýáüŕ│╝ ŕ│á(Úźś)Ýü┤ŰčČÝä░ ýśüýŚşýŚÉ ÝĽ┤Űő╣ÝĽśŰŐö ŕ▒┤ŰČ╝ŕ│╝ýŁś ŕ░äŕ▓ęŰĆä ý×Ĺŕ▓î ýäĄýáĽÝĽťŰőĄ. ýŁ┤ ŕ▓ŻýÜ░ ŕ▒┤ŰČ╝ýŚÉ ÝĽ┤Űő╣ÝĽśŰŐö ýśüýŚşýŚÉ ŰîÇÝĽ┤ýäť ýëŻŕ▓î ýśĄÝâÉýžÇ(False Positive)ŕ░Ç Ű░ťýâŁÝĽá ýłś ý׳ŰőĄ.
ŕ┤ÇŰáĘ ýŚ░ŕÁČ
2.1 ŰöąŰčČŰőŁ ŕŞ░Ű░ś ÝĹťýáü ÝâÉýžÇ ýĽîŕ│áŰŽČýŽś
2.2 ýľ┤ÝůÉýůś ýĽîŕ│áŰŽČýŽś
Attention YOLOv4 ŕŞ░Ű░ś ÝĹťýáü ÝâÉýžÇ ýĽîŕ│áŰŽČýŽś
3.1 ŕŞ░ýí┤ YOLOv4[14] ŰäĄÝŐŞýŤîÝüČ ŕÁČýí░
3.1.1 Ű░▒Ű│Ş ŰäĄÝŐŞýŤîÝüČ
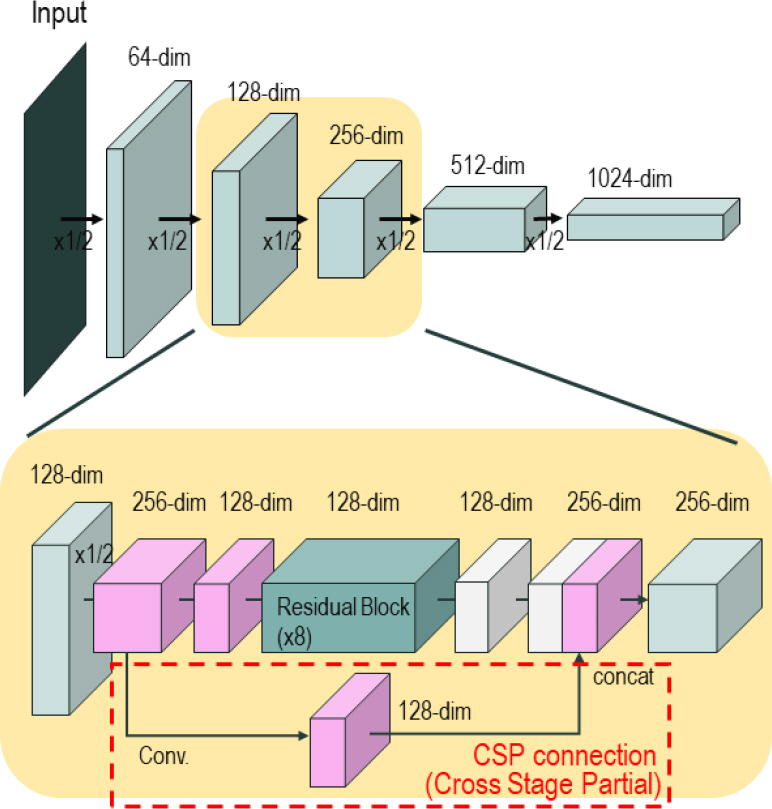
3.1.2 Űäą ŰäĄÝŐŞýŤîÝüČ
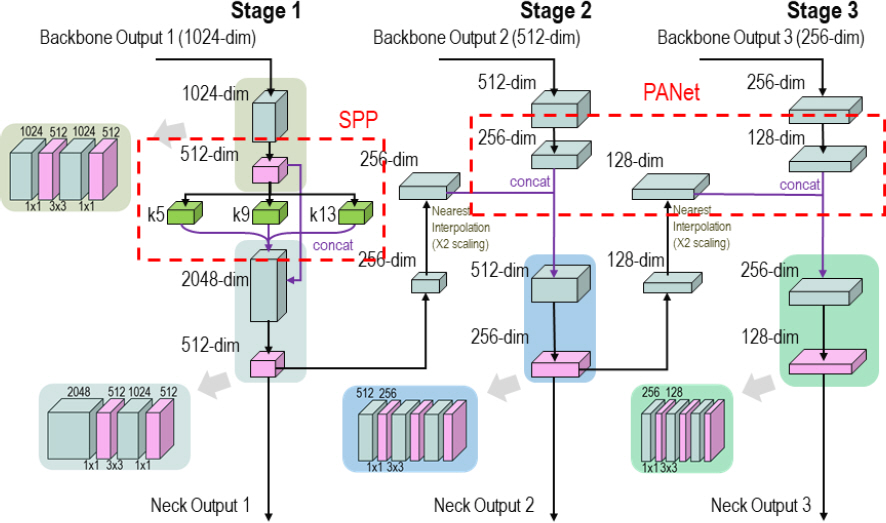
3.1.3 ÝŚĄŰôť ŰäĄÝŐŞýŤîÝüČ

3.2 ýľ┤ÝůÉýůś ۬ĘŰôłýŁä ýáüýÜęÝĽť YOLOv4[14] Ű░▒Ű│Ş ŰäĄÝŐŞýŤîÝüČ ŕÁČýí░ýŁś ÝÖĽý׹
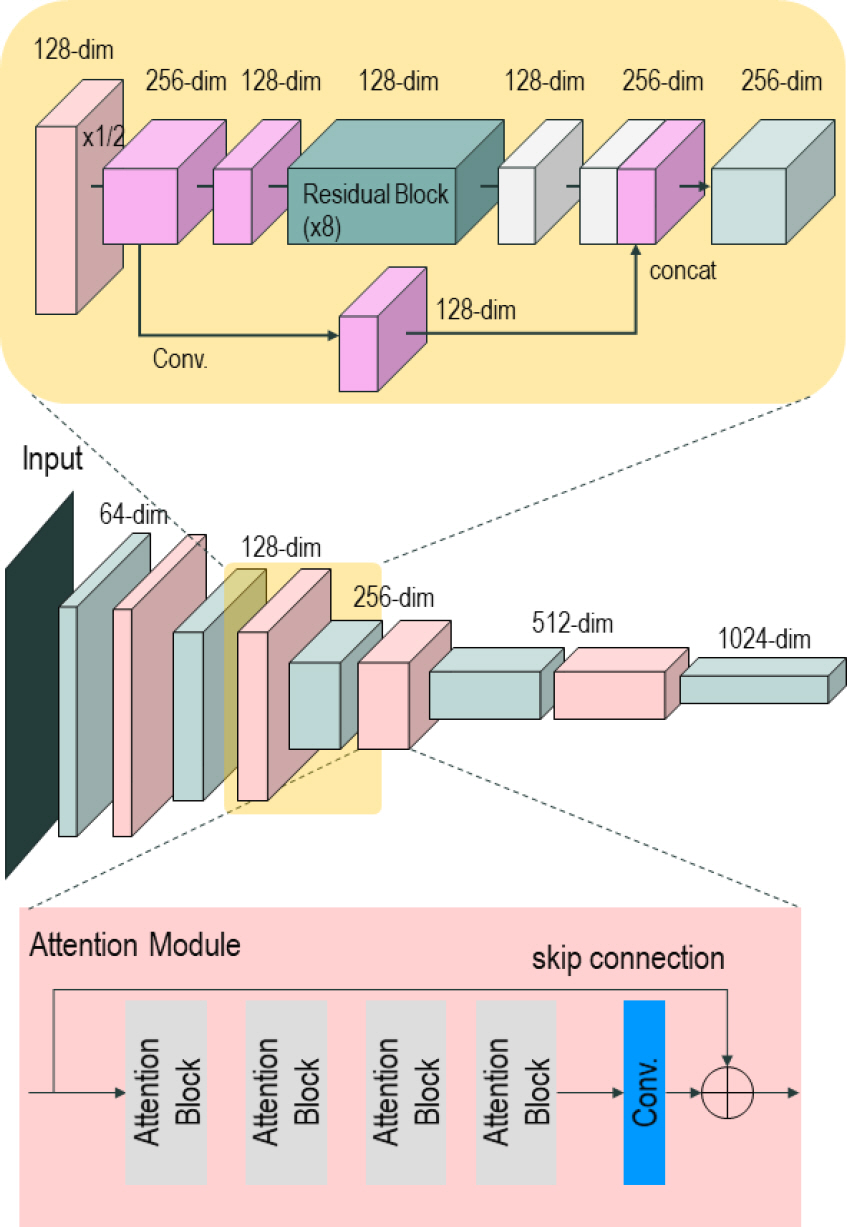
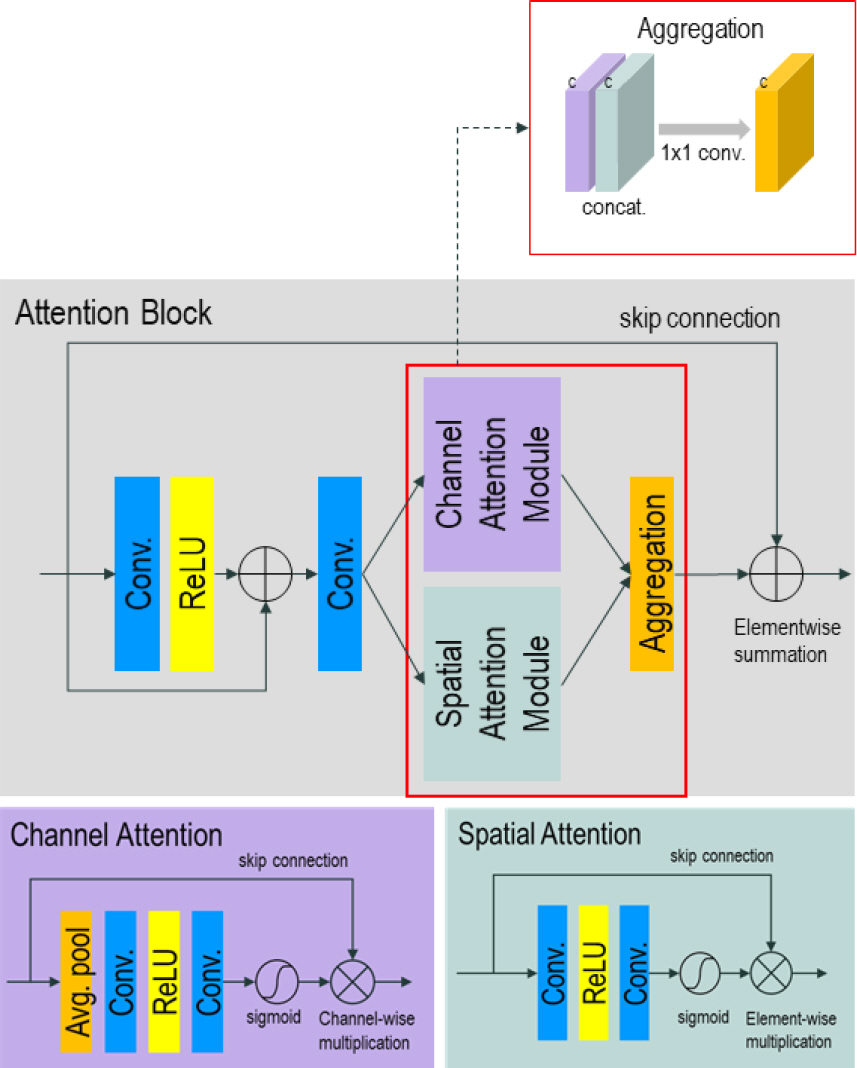
3.2.1 Cascade Channel-Spatial Connection

3.2.2 Parallel Channel-Spatial Connection
3.2.3 Coordinate Attention[10]

MSTARŃÇÇSAR embedding datasets
4.1 MSTAR Public Datasets[15]


Table 1.
| Parameters | Value |
|---|---|
| Depression angle (┬░) | 15 |
| Height of image (pixels) | 1784 |
| Width of image (pixels) | 1472 ~ 1478 |
| Mode | Strip map |
| The number of scenes | 87 |
| Range resolution (m) | 0.3 |
| Range Pixel Spacing (m) | 0.2 |
4.2 Target Embedding
4.2.1 Ýü┤ŰčČÝä░ ýőáÝśŞ Ű╣äýťĘ ýí░ýáĽ
4.2.2 ÝĹťýáü ÝĽęýä▒ýŁä ýťäÝĽť ŰžłýŐĄÝüČ ýâŁýä▒
Fig. 10.
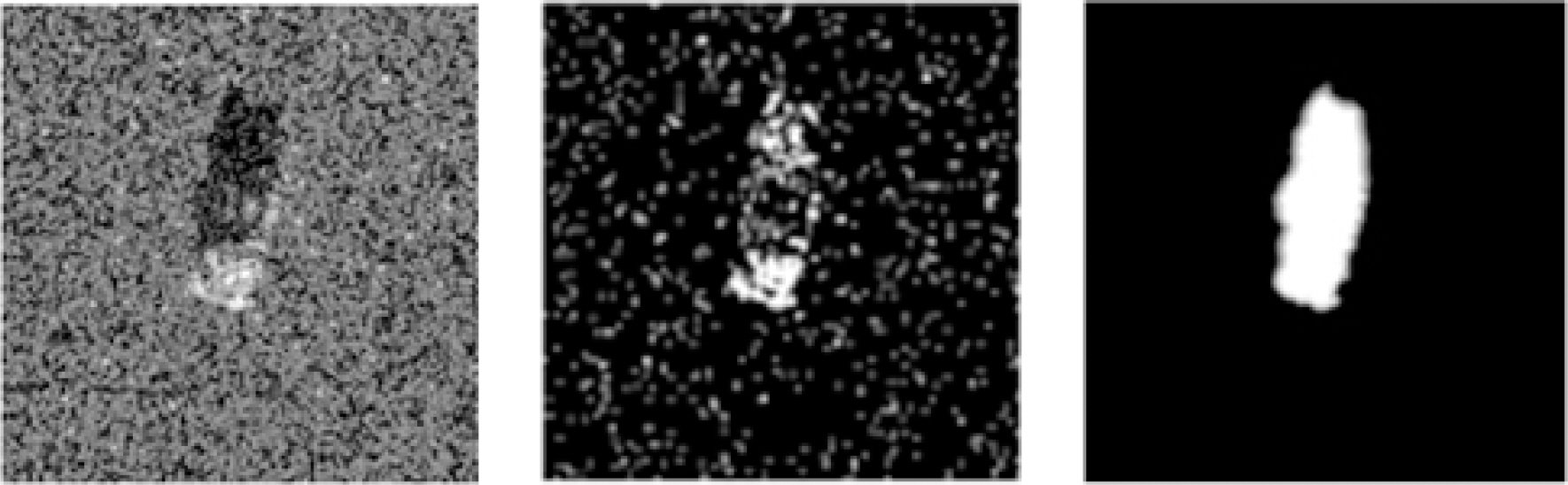
4.2.3 ÝĹťýáü ÝĽęýä▒ Ű░ęŰ▓Ľ
4.2.4 ÝĹťýáü ýőáÝśŞ Ű»ŞýĽŻ ýőťŰéśŰŽČýśĄ ÝůîýŐĄÝŐŞ ŰŹ░ýŁ┤Ýä░ ýůő


4.3 Training/Test datasets
4.3.1 Training datasets

4.3.2 Test datasets


ýőĄÝŚś ŕ▓░ŕ│╝
5.1 Training/Test Parameters
ÔÇó ÝĽÖýŐÁ Ű░śŰ│Á ÝÜčýłś(Training step) : 1,400,000
ÔÇó ÝĽÖýŐÁýŚÉ ýéČýÜęÝĽť Ű░░ý╣ś(ýäťŰŞî Ű░░ý╣ś) ÝüČŕŞ░ : 64(4)
ÔÇó Learning rate : 0.001(1,250,000 step ÝŤä 0.0002)
ÔÇó Adam optimizer(beta1 : 0.9, beta2 : 0.999)
ÔÇó ýőáŰó░ŰĆä ŰČŞÝä▒ŕ░ĺ(confidence threshold) : 0.6
ÔÇó NMS(Non Maximum Suppression) threshold : 0.6
ÔĹá Localization loss : ŕ░ü Ű░öýÜ┤Űöę Ű░ĽýŐĄýŁś ýťäý╣ś ýóîÝĹťýŚÉ ŰîÇÝĽť Binary Cross Entropy loss Ű░Ć ŕ░ÇŰíť ýäŞŰíť ŕŞŞýŁ┤ýŚÉ ŰîÇÝĽť MSE loss
ÔĹí Classification loss : ÝĹťýáüýŁś ýóůŰąś(Class)ýŚÉ ŰîÇÝĽť Binary Cross Entropy loss
ÔĹó Confidence loss : ÝâÉýžÇ ŕ▓░ŕ│╝ýŁś ýőáŰó░ŰĆä ýáÉýłś(Confidence score)ýŚÉ ŰîÇÝĽť Binary Entropy loss
5.2 ÝĹťýáü ÝâÉýžÇ ýĽîŕ│áŰŽČýŽś ýä▒ŰŐą Ű╣äŕÁÉ
5.2.1 YOLOv4 ŕŞ░Ű░ś ýĽîŕ│áŰŽČýŽśŰ│ä ÝĹťýáü ÝâÉýžÇ ýä▒ŰŐą Ű╣äŕÁÉ
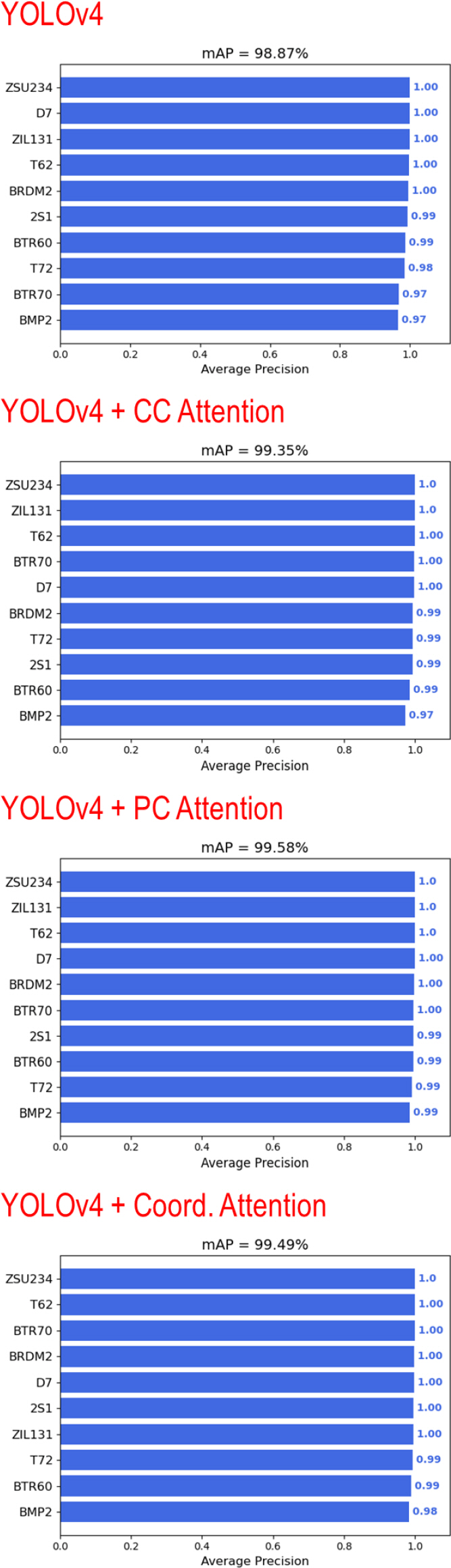
Table 6.
5.2.2 ÝĹťýáü ýőáÝśŞ Ű»ŞýĽŻ ýâüÝÖęýŚÉýäťýŁś YOLOv4 ŕŞ░Ű░ś ýĽîŕ│áŰŽČýŽśŰ│ä ÝĹťýáü ÝâÉýžÇ ýä▒ŰŐą Ű╣äŕÁÉ
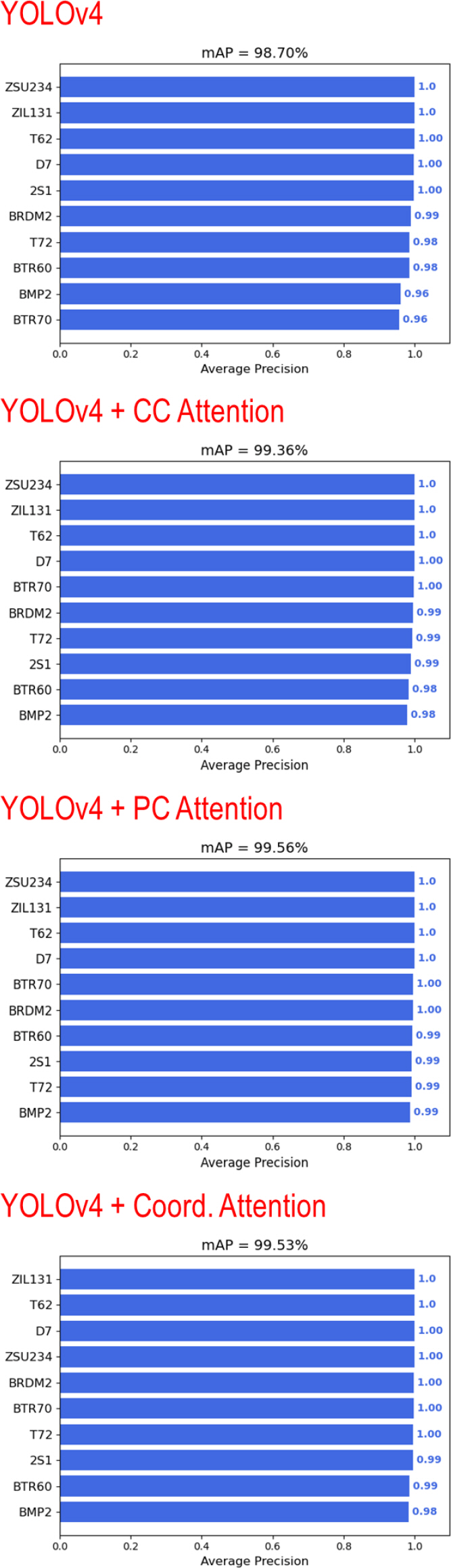
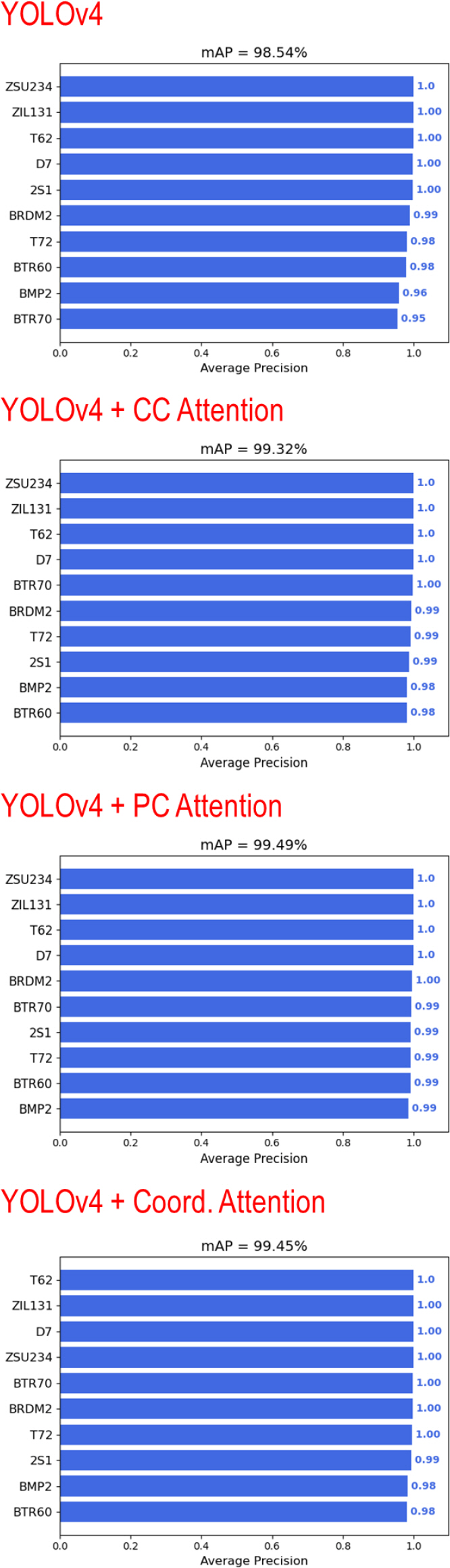

Table 7.

ŕ▓░ Űíá
ÔĹá ÔĹá ÝŐŞŰםýŐĄÝĆČŰĘŞ(Transformer) ŕŞ░Ű░ś Ű░▒Ű│Ş ŰäĄÝŐŞýŤîÝüČ : Ýśäý×Č ÝÖťŰ░ťÝ׳ ýŚ░ŕÁČŰÉśŕ│á ý׳ŰŐö ýú╝ýáťýŁŞ ý×ÉŕŞ░-ýľ┤ÝůÉýůś(self- attention) ŕŞ░Ű▓ĽýŁä ÝÖťýÜęÝĽť ÝŐŞŰםýŐĄÝĆČŰĘŞ ŕÁČýí░Űą╝ Ű░▒Ű│Ş ŰäĄÝŐŞýŤîÝüČýŚÉ ýáüýÜęÝĽśýŚČ ŰĆÖýŁ╝ÝĽť ýŚ┤ýĽůÝĽť ÝĹťýáü ÝâÉýžÇ ýâüÝÖęýŚÉýäť ýä▒ŰŐąýŁ┤ ÝľąýâüŰÉá ýłś ý׳ýŁîýŁä Ű│┤ýŁŞŰőĄ. ŰőĄŰžî, ÝŐŞŰםýŐĄÝĆČŰĘŞ ŕÁČýí░Űą╝ Ű░▒Ű│Ş ŰäĄÝŐŞýŤîÝüČýŚÉ ýÂöŕ░ÇÝĽśŰę┤ Ű│Ş Űů╝ŰČŞýŚÉýäť ý▒äÝâŁÝĽť ýľ┤ÝůÉýůś ۬ĘŰôłŰ│┤ŰőĄ ŕ│äýé░ Ű│Áý×íŰĆäŕ░Ç ýâüŰő╣Ý׳ ýŽŁŕ░ÇÝĽśŕŞ░ ŰĽîŰČŞýŚÉ, ýÂöŰíá ýćŹŰĆäýÖÇ ýä▒ŰŐąýŁä ۬ĘŰĹÉ ŕ│áŰáĄÝĽśŰŐö ýŞíŰę┤ýŚÉýäť ÝĽ┤Űő╣ ŕÁČýí░ýŚÉ ŰîÇÝĽť ÝÜĘŕ│╝ýáüýŁŞ ÝÖťýÜę Ű░ęýĽłýŁä ۬ĘýâëÝĽśŕ│áý×É ÝĽťŰőĄ.
ÔĹí ýćÉýőĄ ÝĽĘýłśŰą╝ ýťäÝĽť ÝâÉýžÇ Ű░öýÜ┤Űöę Ű░ĽýŐĄ Ű│┤ýÖä : Ýśäý×Č ÝĽÖýŐÁ Ű░Ć ÝůîýŐĄÝŐŞýŚÉ ýéČýÜęŰÉśŰŐö ÝâÉýžÇ Ű░öýÜ┤Űöę Ű░ĽýŐĄŰŐö ŕ╝şýžôýáÉýŁś ýťäý╣ś Ű░Ć ŕŞŞýŁ┤ ýáĽŰ│┤Űžî ÝĆČÝĽĘÝĽśŕ│á ý׳ýť╝Ű»ÇŰíť ŰőĄýľĹÝĽť Ű░ęýťäŰ░ęÝľąýŁä ŕ░ÇýžÇŰŐö ÝĹťýáüýŁś ýáĽÝÖĽÝĽť ýťäý╣śŰą╝ ŰéśÝâÇŰé┤ŕŞ░ ýľ┤ŰáÁŰőĄ. ýŁ┤Űą╝ ÝĽ┤ŕ▓░ÝĽśŕŞ░ ýťäÝĽ┤ Ű░öýÜ┤Űöę Ű░ĽýŐĄýŚÉ ŕ░üŰĆä ýáĽŰ│┤Űą╝ ÝĆČÝĽĘÝĽ┤ýäť ÝĹťýáüýŁś Ű░ęýťäŰ░ęÝľąýŚÉ Űö░ŰŁ╝ýäť ŰŹöýÜ▒ ýáĽŰ░ÇÝĽśŕ▓î ÝĹťýáüýŁś ýťäý╣śŰą╝ ŰéśÝâÇŰé╝ ýłś ý׳ŰĆäŰíŁ Ű│┤ýÖäÝĽťŰőĄŰę┤ ýćÉýőĄÝĽĘýłś ŕ│äýé░ Ű░Ć IoU ŕ│äýé░ ýŞíŰę┤ýŚÉýäť ŰćĺýŁÇ ýőáŰó░ŰĆäŰą╝ ÝÖĽŰ│┤ÝĽá ýłś ý׳ŰőĄ.




