서 론
최근 10여 년간 컴퓨터 비전 분야 등지에서 비약적으로 발전해온 딥러닝(deep learning)기술은 이제 센서영상인 합성 개구면 레이더(Synthetic Aperture Radar, SAR) 영상에서의 관심표적 탐지 및 분류 분야에도 폭넓게 적용되고 있으며, 관련하여 많은 연구결과가 발표되었다. 관련 연구의 초기에 해당되는 2010년대 중후반에는 주로 관심지역을 촬영한 전체 SAR 영상 씬(scene)의 일부분에 해당되는 표적의 SAR 영상 데이터셋(주로 MSTAR 데이터 셋
[1])에 대해서 합성곱 신경망(Convolutional Neural Network, CNN) 기반의 딥러닝 기법을 차용한 분류 정확도 향상 연구가 많았다
[2,3]. 이후 2020년대에 들어서는 다양한 위성 플랫폼에서 획득되어 해상/해안의 선박 표적을 포함하고 있는 SAR 영상 데이터 셋이 온라인에 공개된 것을 계기로, Faster R-CNN(Region with CNN)이나 YOLO(You Only Look Once)와 같은 딥러닝 탐지/분류 네트워크를 SAR 영상에 적용하는 연구가 촉진되었다
[4,5]. 이들 연구의 흐름은 주로 기존 컴퓨터 비전 분야에서 발표된 기법을 차용하던 것에서, 점차 SAR 선박탐지에 적합하도록 기존의 기법을 수정하거나 새로운 딥러닝 탐지/분류 네트워크 및 학습기법을 창안하는 방향으로 발전해왔다. 그러나 이들 SAR 딥러닝 탐지/분류 네트워크 연구에는 다음 2가지의 한계가 있다. 첫째, 연구의 목표가 단일 부류(single class) 선박탐지에 대부분 국한되며, 지상표적에 대한 적용사례는 찾아보기 힘들다. 선박이 위치한 해상 환경에 비해 차량 등 지상표적이 위치한 환경은 지형지물이나 인공 구조물로 인해 전자파 산란특성이 보다 복잡하며, 지면의 스펙클(speckle) 잡음 또한 고려해야 할 요소이다. 둘째, 기존 연구에서 딥러닝 탐지/분류 네트워크의 학습 데이터는 실측 SAR 영상으로 구성되어 있으며, 합성 데이터를 사용한 연구사례는 찾아보기 힘들다. 공개된 SAR 선박탐지 데이터셋을 이용한 탐지/분류 연구의 경우, 충분한 학습 데이터를 기반으로 탐지성능을 향상시키는 쪽으로 연구방향이 설정되어 있다. 반면 SAR 표적영상 만을 분류하는 연구 분야에서는 딥러닝 분류 네트워크 학습을 위한 실측 데이터가 부족한 상황을 가정하여, 전자파 산란 시뮬레이션으로 생성한 영상을 이용하여 일정 수준 이상의 분류 정확도를 도출하기 위한 연구도 수행된 바 있다
[6,7].
본 논문에서는 이러한 문제의식으로부터 출발하여, 합성 데이터를 이용하여 SAR 지상 차량표적에 대한 딥러닝 탐지/분류 실험 및 성능분석을 수행한다. 이를 위해 합성 데이터를 제작하고, 합성 데이터만을 활용하여 딥러닝 탐지/분류 네트워크를 학습한 뒤 실측 SAR 영상에서의 지상표적 탐지/분류 성능을 시험한다. 이어서, 학습 데이터에 포함되는 실측영상의 비율 및 수량에 따른 성능변화 또한 분석한다. 이로써 본 논문이 기여한 바는 다음과 같다.
① 기존의 연구 및 데이터 공개 사례에서는 찾아볼 수 없는 SAR 지상표적에 대해, 자체적으로 실측 데이터 셋을 확보하여 딥러닝 탐지/식별 네트워크 연구를 수행하였다.
② 상기 실측 SAR 지상표적 데이터 셋 수량이 부족한 상황을 가정하여, 전자파 시뮬레이션으로 예측된 SAR 표적영상을 이용한 합성 데이터를 제작하고 이를 딥러닝 탐지/식별 네트워크 학습에 적용함으로써 성능을 분석하였다. 이러한 연구방법의 채택 또한 기존의 연구사례에서 찾아보기 힘들며, 최초의 시도로 판단된다.
③ 딥러닝 탐지/식별 네트워크 학습 시, 예측영상의 포함여부 및 실측영상의 비율을 다양한 값으로 부여함으로써 그에 따른 성능분석 또한 수행하였다.
본 논문의 2장에서는 전체 실험의 구성에 대해 기술하고, 3장에서는 실험결과를 분석하며, 4장에서는 실험결과를 정리하고 한계점과 함께 결론을 맺는다.
SAR 지상표적 탐지/분류 실험의 구성
Fig. 1에는 SAR 지상 차량표적에 대한 딥러닝 탐지/분류 실험의 구성도를 나타내었다.
Fig. 1.
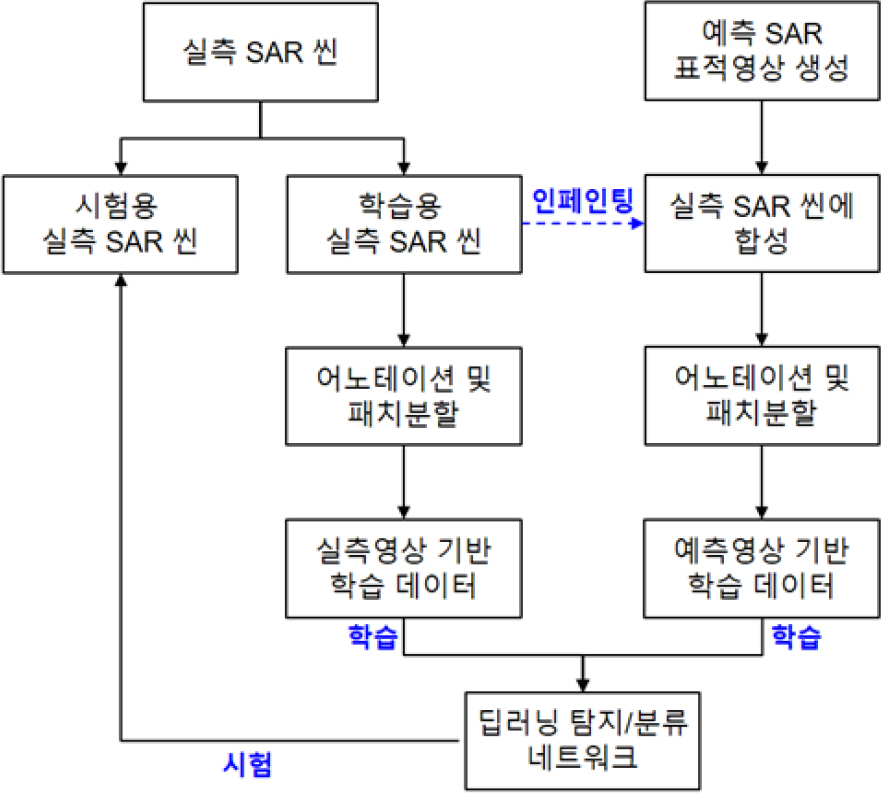
2.1 실측 SAR 씬(scene)
실측 SAR 씬은 SAR 장비를 항공기 플랫폼 등에 장착하여 관심지역의 SAR 영상을 획득한 결과로서, 본 논문에서는 ’21년도 11월에 3회에 걸쳐 약 0.1 km
2 넓이의 관심지역에 대해 획득한 영상 790건을 활용한 다. 실측 SAR 씬의 예시를
Fig. 2에 나타내었으며, 각 영상은 2,048×2,048 픽셀 수 및 15° 촬영고각, 0.3 m 급의 해상도를 갖는다. 획득된 SAR 씬 중, 임의로 절반씩(395) 나누어 각각 딥러닝 탐지/분류 네트워크의 학습용과 시험용으로 사용한다.
Fig. 2.
Examples of the real measured SAR scenes

모든 실측 SAR 씬에는
Fig. 3과 같은 지상 차량표적 7종이 포함되어 있으며, 주로 공사용 중장비이다.
Fig. 3.
Ground vehicle targets in the SAR scenes

• (a1) : 50톤 크레인 /(a2) : 100톤 크레인
• (a3) : 250톤 크레인 /(a4) : 500톤 크레인
• (a5) : 카고크레인 트럭 /(a6) : 5톤 사다리차
• (a7) : 25톤 크레인
Fig. 1의 학습용 실측 SAR 씬에 대해서는 표적의 종류 및 위치를 표시한 정답지(ground truth)를 제작하는 어노테이션(annotation) 작업을 수행하고, 딥러닝 탐지/분류 네트워크의 입력크기를 고려하여 832×832 크기의 영상패치(patch)로 분할한다. 패치분할 시에는 패치 내에 표적이 1개 이상 포함되도록 임의의 위치에 대해 씬 당 복수의 패치를 추출하고, 패치 별 표적의 위치/종류 정보와 정답지의 정보를 매칭하여 실측영상 기반 학습데이터(총 패치 수 5,141개)를 생성한다. 시험용 실측 SAR 씬에 대해서는 차후 성능산출을 위한 어노테이션 작업을 수행한다.
2.2 예측 SAR 표적영상 및 합성 데이터
본 논문에서 언급하는 합성 데이터(synthetic data)는 전자파 산란 시뮬레이션으로 예측된 SAR 표적영상을 실측 SAR 씬에 합성한 결과를 의미한다.
Fig. 4에는 예측 SAR 표적영상과 합성 데이터의 생성 개념을 나타내었다.
Fig. 4(a)에는 예측 SAR 표적영상 생성을 위한 표적의 CAD 모델을 나타내었으며, 25톤 크레인(a7)을 제외한
Fig. 3의 지상차량을 정밀 모사하여 제작되었다. a7 차량의 경우 측정간 공간적/시간적 제약으로 인해 별도의 CAD 모델을 제작하지 않았으며, 실험 시 탐지/식별 대상이 아닌 허위표적으로서의 역할을 한다. 해당 CAD모델을 이용하여
Fig. 4(b)와 같이 SE-RAY-SAR 소프트웨어(OKTAL-SE 社)로 예측 SAR 표적영상을 생성하였다. 영상합성 수행 전,
Fig. 4(c)와 같이 표본기반 인페인팅(exemplar-based inpainting)
[8]을 통해 학습용 실측 SAR 씬에 존재하고 있던 표적영상을 제거하고, 제거된 영역에 인근의 스펙클(speckle) 잡음 패턴을 채운다.
Fig. 4(d)에는 인페인팅이 완료된 실측 SAR 씬에 예측 SAR 표적영상(①)을 합성하는 예시를 나타내었으며, 표적영상의 이진 마스크(binary mask)를 ②와 같이 추출하고, 마스크 영역 내의 표적영상 신호레벨을 SAR 씬 내 합성위치의 신호레벨과 동일하게 조정함으로써 합성 데이터(③)를 생성한다. 이러한 방법으로, 6종의 CAD모델 각각에 대해 15°의 촬영고각과 2° 간격의 방위각을 갖도록 생성된 예측 SAR 표적영상 1,080건을 383개의 실측 SAR 씬에 분배하여 합성한다. 이러한 합성 데이터로부터 어노테이션 및 패치분할을 통해 총 5,745개의 패치로 구성된 예측영상 기반 학습데이터를 생성한다.
Fig. 4.
Concept of SAR synthesis data generation

2.3 딥러닝 탐지/분류 네트워크의 학습
본 논문에서 SAR 지상 차량표적을 탐지 및 분류할 네트워크는
Fig. 5에 나타낸 YOLOv4
[9] 형태의 구조를 갖는다. 네트워크의 학습 전 가중치는 가우시안 분포를 갖는 값으로 초기화되어 있으며, CSP-Darknet53 구조의 백본(backbone)과 FPN(Feature Pyramid Network), PAN(Path Aggregation Network)으로 구성된 ‘neck’, 그리고 탐지/분류 결과 특징맵(feature map)이 도출되는 ‘head’로 구성된다. 그 외 본 논문에서 활용된 딥러닝 탐지/분류 네트워크의 특성은 다음과 같다.
Fig. 5.
Adopted YOLOv4-type network structure

① 딥러닝 탐지/분류 네트워크의 백본과 FPN 간에는 SPP(Spatial Pyramid Pooling)기법을 적용하여, 다중 스케일의 특징맵 각각에서 표적영상 부분이 차지하는 영역을 네트워크 학습과 추론에 반영함으로써 유효한 수용영역을 확대하였다. 이를 통해 표적 검출능력을 향상시킬 수 있음을 참고문헌 [9]에서는 기술하고 있다.
② FPN과 PAN에서 특징맵의 스케일을 증가시키기 위해, 기존의 YOLOv4에서는 특징맵에 대한 내삽(interpolation) 기반의 업 샘플링(upsampling)을 적용하였다. 그러나 본 논문에서는 지상 차량표적의 SAR 영상이 영상 패치에서 차지하는 비중이 상대적으로 적어 학습된 필터를 통해 업 샘플링을 수행할 수 있는 전치 합성곱(transposed convolution)으로 대체하였다.
③ 탐지결과의 초기 영역이 되는 앵커(anchor)박스는 학습데이터로부터 k-평균 군집화에 의해 9개가 선정되며, 이들을 ‘head’에서 도출되는 특징맵 3종의 스케일을 고려하여 6개씩 분배한다. 각 특징맵의 스케일은 입력영상 크기의 1/32, 1/16, 1/8이다.
딥러닝 탐지/분류 네트워크 학습은
Table 1과 같이 6가지 학습 데이터 조합별로 수행된다. 조합 ‘case 1’은 2.2절의 합성 데이터에서 생성된 예측영상 기반 학습 데이터만으로 네트워크를 학습하는 경우이며, ‘case 2∼6’는 ‘case 1’의 학습 데이터에 실측영상 기반 학습 데이터를 각각 6.25 %, 12.5 %, 25 %, 50 %, 100 % 만큼 추가하는 경우이다. 네트워크 학습 시에는 특정 데이터로 네트워크를 미리 학습시키는 전이학습(transfer learning)은 활용하지 않고, 처음부터 대상 패치를 학습에 적용하였다(from the scratch). 네트워크 성능 개선을 위해 아래의 데이터 증대(data augmentation)를 적용하였다. 이 때 데이터 증대는 영상패치 원본으로부터 증대방식이 적용된 영상패치를 물리적으로 생성하지 않고, 네트워크 학습의 반복수(iteration)에 따라 아래 데이터 증대 기법이 선택적으로 조합된다.
Table 1.
Network training data combinations
|
조 합 |
예측 학습데이터 |
실측 학습데이터 |
|
씬 수 |
패치 수 |
씬 수 |
패치 수 |
사용 비 |
|
case1 |
383 |
5,745 |
0 |
0 |
0.00 % |
|
case2 |
383 |
5,745 |
25 |
316 |
6.25 % |
|
case3 |
383 |
5,745 |
50 |
647 |
12.5 % |
|
case4 |
383 |
5,745 |
99 |
1,287 |
25.0 % |
|
case5 |
383 |
5,745 |
198 |
2,589 |
50.0 % |
|
case6 |
383 |
5,745 |
395 |
5,141 |
100 % |
① 분산 10-5 이내의 가우시안 잡음 추가(noising)
② 가로/세로방향으로 영상 반전(flip)
③ ±5 픽셀 이내 가로/세로방향 평행이동(translation)
④ ±5° 범위 이내 영상회전(rotation)
⑤ 영상 도시범위(Dynamic Range, DR) 변화 : 40∼70 dB
위 데이터 증대방법 중 ⑤의 ‘영상 도시범위’는 영상 데이터를 도시하는데 있어서 영상 픽셀의 최댓값과 최솟값 간의 비율(dB)을 의미한다.
Fig. 6에 영상 도시범위에 따른 SAR 영상의 예시를 나타내었다.
Fig. 6.
Concept of dynamic range of SAR images

그 외 네트워크 학습 환경변수는 아래와 같다.
① 하드웨어 : NVIDIA A100 GPU, 40 GB 메모리
② MATLAB Deep Learning Toolbox Framework
③ 최적화 기법 : SGD(Stochastic Gradient Descent)
④ 최대 에폭(epoch)수 : 50
⑤ 미니배치(mini-batch) 크기 : 4
-
⑥ 학습률(learning rate) : 최대 0.001
- 5 th 에폭 워밍업 학습, 30 th/40 th 에폭 1/10 씩 감쇄
⑦ 대상표적 부류(class) : a1∼a6 등 지상차량 6종
2.4 딥러닝 탐지/분류 네트워크의 시험
학습이 완료된 딥러닝 탐지/분류 네트워크 시험 시에는 시험용 실측 SAR 씬을 9개의 겹침을 허용하는 영상패치로 분할한 후, 각 패치를 배치 단위로 묶어서 네트워크에 입력하여 ‘head’단에서 특징맵을 획득한다. 이후 특징맵의 후처리(post processing)과정에서는 특징맵에 포함된 표적 존재여부 점수(objectness score)를 바탕으로 일부 탐지결과만 남긴 후, 위치가 겹치는 탐지결과들은 겹침정도(IoU, Intersection of Union)를 바탕으로 비최대 억제(Non-Maximum Suppression, NMS)를 적용한다. 탐지결과의 분류결과는 특징맵에 포함된 표적 부류 별 조건부 확률을 참조한다. 위치좌표는 특징맵에 기재된 0∼1 사이의 값을 앵커박스에 적용하고, 특징맵의 스케일을 고려하여 영상패치 기준의 좌표로 환산한 후, 다시 원래의 실측 SAR 씬 기준의 좌표로 변환한다. 최종결과 도출을 위한 확신도 점수의 문턱치(threshold) 및 NMS IoU 문턱치는 0.5로 부여하였다. 시험용 실측 SAR 씬 1건 당 평균 탐지/분류 소요시간은 NVIDIA Geforce RTX 3060 GPU를 기준으로 약 5.3초로서, 네트워크 연산이 전체의 99 %를 차지한다.
실험결과
3.1 예측영상 기반 학습 데이터 활용 실험결과
3.1절에서는 예측영상 기반 학습 데이터만을 딥러닝 탐지/분류 네트워크 학습에 활용한 ‘case 1’의 실험결과를 주로 기술한다.
Fig. 7에는 시험용 실측 SAR 씬에 대한 탐지/분류 결과의 예시를 나타내었으며, 결과 하단에 표적 부류(a1∼a6)와 확신도 점수를 표시하였다. 흰색 글씨는 올바르게 탐지 및 분류가 수행된 결과를 의미하고, 탐지되지 않았거나 잘못 분류(오분류)된 결과는 흰색 바탕에 색상이 있는 글자로 표시하였다. 오경보(false alarm)는 표적이 아닌 탐지결과로서 씬 당 1개 이내로 탐지되는데, 이는 대부분
Fig. 7(a)∼(d)와 같이 a7표적(25톤 크레인)을 a1표적(50톤 크레인)으로 탐지 및 분류한 사례에 해당된다. 본 실험의 특성상, a7표적은 학습대상에 없으므로 원칙적으로는 오경보에 해당한다. 그러나
Fig. 3과 같이 a7표적은 a1표적과 유사한 표적형태를 가지므로 표적특징의 유사성을 딥러닝 네트워크가 포착하였다고 볼 수 있다. 그 외
Fig. 7(a)에서는 a2표적을 a3표적으로,
Fig. 7(d) 및
Fig. 7(g)에서는 a1표적을 a5표적으로 잘못 분류하였으며,
Fig. 7(g)∼(h)에는 탐지에 실패한 사례 3건을 나타내었다.
Fig. 7.
Examples of detection/classification(case 1)

Table 2에는 395건의 시험용 실측 SAR 씬에 대해 각기 다른 영상 도시범위(DR)를 적용함에 따른 탐지/분류 성능지표를 나타내었다. 통상적으로 딥러닝 탐지/분류 네트워크의 성능지표로는 재현율(recall)과 정밀도(precision), mAP(mean Average Precision) 등을 활용하나, 본 논문에서는 탐지확률과 오경보율, 분류확률 등 3종을 채택하였다. 아래에 설명한 각 지표 별 설명에 나타낸 바와 같이, 본 논문에서 주로 채택하는 지표가 표적의 탐지/분류 여부 및 성공비율, 부정확한 탐지의 평균적인 개수를 보다 직관적으로 보여주기 때문이다.
Table 2.
Experiment results for ‘case 1’ for various dynamic ranges(DR)
|
DR |
표적 수 |
탐지확률 |
오경보율 |
분류확률 |
|
40 dB |
1,688 |
97.04 % |
7.31/km2
|
83.33 % |
|
45 dB |
1,688 |
95.79 % |
7.59/km2
|
80.64 % |
|
50 dB |
1,688 |
94.31 % |
7.43/km2
|
80.84 % |
|
55 dB |
1,688 |
94.61 % |
7.43/km2
|
80.84 % |
|
60 dB |
1,688 |
95.79 % |
7.57/km2
|
80.52 % |
|
65 dB |
1,688 |
95.91 % |
7.59/km2
|
80.36 % |
|
70 dB |
1,688 |
95.73 % |
7.59/km2
|
80.07 % |
|
평 균 |
95.60 % |
7.50/km2
|
80.95 % |
① 탐지확률(detection rate) : 시험용 실측 SAR 씬 395건에 포함되어 있는 모든 표적의 수(=1,688개) 대비 네트워크가 탐지에 성공한 표적의 수 간 비율로서, 재현율과 연관된다. 분류 정확도와는 무관한, 탐지 정확도 지표이다.
② 오경보율(false alarm rate) : 전체 SAR 씬의 면적대비 탐지된 오경보의 개수의 비율로서, 단위는 개(EA)/km2이고, 정밀도와 연관된다. 탐지 정확도 지표 중 하나로서, 본 실험의 경우 395건의 SAR 씬총 면적은 약 35.55 km2이므로 Table 2의 ‘평균 7.50개/km2’는 SAR 씬 한 건당 0.675개로 환산할 수 있다.
③ 분류확률(classification rate) : 탐지에 성공한 표적 수 대비 이들 중 올바르게 분류된 표적의 수 간 비율이다. 미탐지 표적은 지표에 반영하지 않는다.
① 영상 도시범위가 40 dB인 경우의 탐지 및 분류 성능이 전반적으로 높다. 이는 영상 도시범위를 줄일수록 상대적으로 강한 표적의 SAR 영상신호가 강조되고, 스펙클 잡음 등은 억제됨에 따른 것으로 분석할 수 있다.
② 네트워크 학습에 실측영상이 쓰이지 않았음에도 95 % 이상의 탐지확률이 도출된다. 이는 획득 기하조건(15°)뿐 아니라 시험용 실측 SAR 씬과 예측영상 기반 학습 데이터 간 표적위치 및 배치형태의 유사성에 따른 것으로 해석할 수 있다. 여기서 표적위치라 함은 다음과 같이 설명할 수 있다. Fig. 2와 Fig. 7에 의하면 표적영상이 모두 씬 중앙 아스팔트 도로 상에 위치하고 있다. 이는 기본적으로 표적영상 신호의 주변은 모두 아스팔트 재질의 배경 반사면에서 도출된 전자파 산란신호로 구성되어 있음을 의미한다. 2.2절에 기술한 합성 데이터 또한 예측 SAR 표적영상을 도로 상에 합성하였으므로, 이러한 신호구성의 유사성을 딥러닝 탐지/분류 네트워크가 포착하였다고 볼 수 있다. 이는 학습용 합성 데이터를 생성 시, 표적의 통상적 위치나 배치와 같은 사전정보가 탐지성능 개선에 영향을 미칠 가능성을 시사한다.
③ 분류성능은 네트워크 학습에 실측영상이 전혀 사용되지 않았음을 감안하면, 낮지 않다고 볼 수 있다. 분류성능은 실측 및 예측 표적영상 간 유사성에 주로 영향을 받으며, 두 영상 간의 차이를 야기하는 요인에는 전자파 산란 시뮬레이션 기법의 실측과의 오차와 해석대상 CAD 모델의 실물과의 오차를 들 수 있다. 본 실험의 지상 차량표적은 실제 접근하여 정밀 CAD 모델을 제작할 수 있으므로 한 가지 오차 요인이 사실상 제거되었다. 이는 실측 표적영상과 예측 표적영상 간의 유사도를 높이는 요인이 되므로 전체적인 분류성능 뿐만 아니라 개별 탐지/식별 결과 중에서도 0.9 이상의 높은 확신도 점수를 갖는 것이 다수 확인된다. 다른 한편으로는 정밀 모델링이 제한적인 접근불가 표적의 경우, 수용 가능한 성능을 도출하기 위해서는 전자파 산란 시뮬레이션 기법 및 딥러닝 네트워크 학습기법 보완의 중요도가 높다는 것을 의미한다.
④ 오경보율 성능은 상기 언급한 바와 같이 주로 25톤 크레인(a7)에 의한 것으로서, 인공 구조물 및 지형지물에 의한 오경보 개수는 0에 가깝다. 이는 씬으로부터 다양한 위치에서 패치를 추출함에 따라 표적이 아닌 샘플(negative sample)에 대해 학습이 이루어졌기 때문으로 판단된다.
3.2 실측영상 기반 학습 데이터에 따른 실험 결과
3.2절에서는 실측영상 기반 학습 데이터의 포함 비율에 따른 실험결과를 주로 기술한다. 기본적으로는
Table 1의 ‘case 1∼6’과 같이 예측영상 기반 학습 데이터를 100 % 포함하되, ‘case 2∼6’에 대해서는 예측영상 기반 학습 데이터를 포함하지 않은 경우에도 실험을 수행한다.
Fig. 8(a)∼(c)에는 상기 실험 시나리오들에 대한 탐지확률과 오경보율, 분류확률을 나타내었다.
Fig. 8.
Performance metrics for experiments
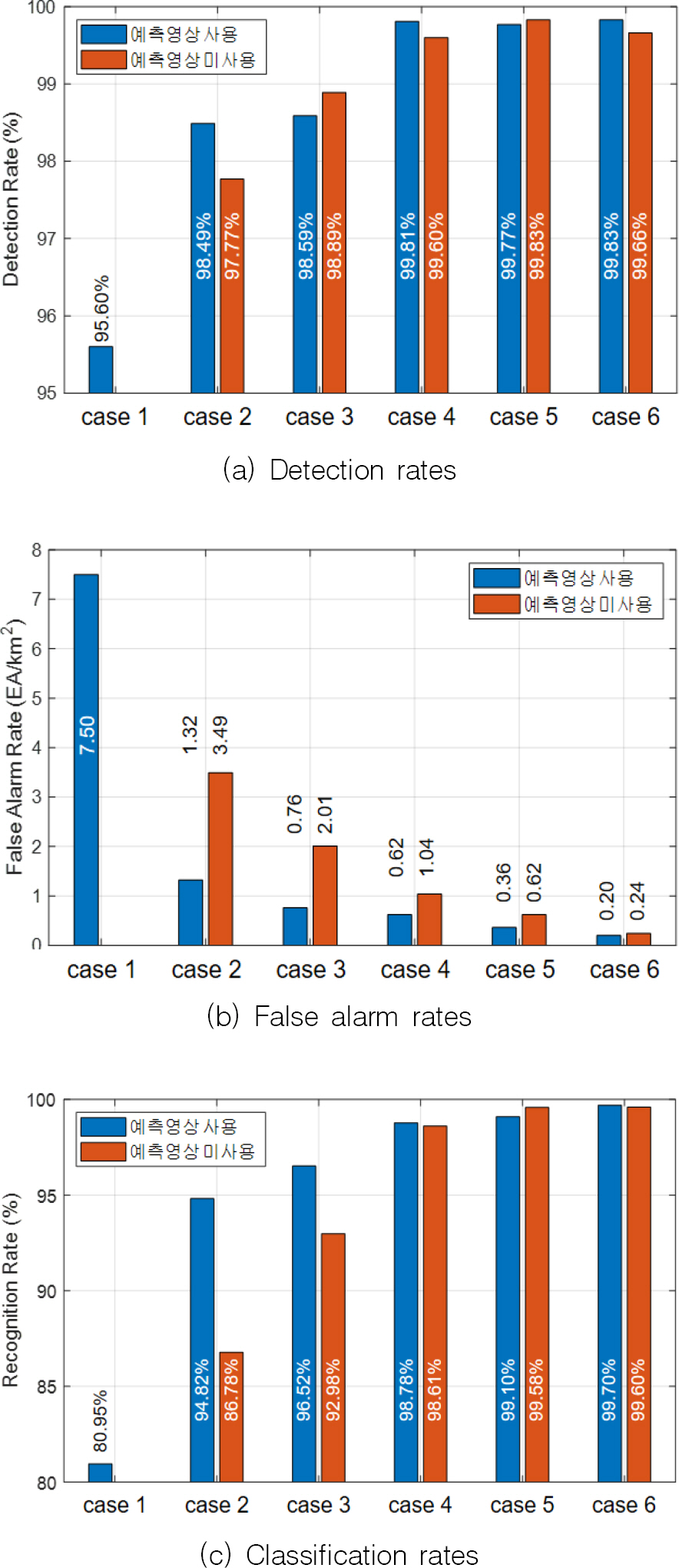
Fig. 8(a)의 탐지확률은 실측영상이 학습에 포함된 이후 최소 3 %의 성능개선이 확인된다. ‘case 2∼6’에서 예측영상 포함에 따른 탐지확률 차이는 1 % 이내이고, case 3 이후부터는 0.5 % 내외의 작은 차이를 보인다. 전반적으로 탐지확률 측면에서는 예측영상 사용여부에 따른 성능차이가 크지 않은데, 이는 제작한 합성 데이터로 달성가능한 탐지성능은 한계가 있으며, 이후의 성능 향상은 실측영상의 수령에 좌우됨을 확인할 수 있다. 합성데이터 만으로 탐지성능을 높이기 위해서는 보다 다양한 경우(표적의 종류 및 방위각 등)를 고려한 합성 데이터를 추가로 제작하여야 할 것으로 보인다.
Fig. 8(b)의 오경보율은 실측영상 포함 전후의 성능변화가 두드러지는데, 이는 실측영상 내에 포함되어 있는 a7표적이 탐지/분류 대상이 아니라는 것을(negative sample) 네트워크가 비로소 학습하였기 때문이다. ‘case 2∼6’에서는 예측영상을 학습에 포함한 경우가 그렇지 않은 경우에 비해 오경보율 개선효과가 높으며, 그 효과는 실측영상의 포함비율에 따라 낮아짐을 확인할 수 있다.
Fig. 8(c)에서는 ‘case 1’의 예측영상 만을 활용한 경우의 분류확률이 80.95 %인데 비해, 여기에 실측영상 6.25 %만을 추가(case 2)해도 분류확률이 94.82 %로 상승한다. 실측영상 6.25 %만을 활용한 경우의 분류확률이 86.78 %이므로, 예측영상 기반 학습 데이터의 추가에 따른 데이터 다양성 개선의 효과가 뚜렷하다고 볼 수 있다. 실측영상 12.5 %를 추가(case 3)한 경우에도 예측영상 포함 전후의 분류확률 차이가 약 2.5 % 인데, 실측영상 12.5 % 만을 학습에 포함한 경우(92.98 %)보다 실측영상 6.25 %와 예측영상 100 %를 포함한 경우(94.82 %)가 더 높은 성능을 보인다. 단, 실측영상의 포함비율이 높아지고 수량이 충분해질수록(case 4 이후, 실측영상 비율 25 % 이상) 성능향상 효과는 미미해지는데, 이는 전이학습이 SAR 표적영상 분류에 미치는 영향에 대해 연구한 타 문헌
[10]에서 기술하는 바와 흡사하다.
Table 3에는 실측영상 기반 학습 데이터의 포함 비율에 따른 실험결과를 종래의 연구에서 주로 차용하는 mAP 지표를 이용하여 나타내었으며, 전반적으로
Fig. 8의 결과와 동일한 변화양상을 보인다.
Table 3.
|
DR |
case1 |
case2 (사용) |
case2 (미사용) |
case3 (사용) |
case3 (미사용) |
|
|
40 dB |
0.7752 |
0.9509 |
0.8663 |
0.9606 |
0.9276 |
|
|
45 dB |
0.7471 |
0.9548 |
0.8703 |
0.9668 |
0.9355 |
|
50 dB |
0.7391 |
0.9520 |
0.8697 |
0.9652 |
0.9375 |
|
55 dB |
0.7440 |
0.9529 |
0.8693 |
0.9690 |
0.9381 |
|
60 dB |
0.7428 |
0.9564 |
0.8719 |
0.9727 |
0.9396 |
|
65 dB |
0.7492 |
0.9557 |
0.8738 |
0.9747 |
0.9388 |
|
70 dB |
0.7440 |
0.9560 |
0.8747 |
0.9758 |
0.9413 |
|
DR |
case4 (사용) |
case4 (미사용) |
case5 (사용) |
case5 (미사용) |
case6 (사용) |
case6 (미사용) |
|
40 dB |
0.9862 |
0.9754 |
0.9893 |
0.9864 |
0.9958 |
0.9961 |
|
45 dB |
0.9914 |
0.9829 |
0.9923 |
0.9921 |
0.9981 |
0.9975 |
|
50 dB |
0.9927 |
0.9854 |
0.9947 |
0.9944 |
0.9981 |
0.9968 |
|
55 dB |
0.9924 |
0.9858 |
0.9936 |
0.9933 |
0.9976 |
0.9969 |
|
60 dB |
0.9931 |
0.9842 |
0.9930 |
0.9944 |
0.9975 |
0.9969 |
|
65 dB |
0.9932 |
0.9855 |
0.9936 |
0.9945 |
0.9969 |
0.9969 |
|
70 dB |
0.9926 |
0.9853 |
0.9936 |
0.9950 |
0.9969 |
0.9969 |
결 론
본 논문에서는 표적의 예측영상을 이용한 합성 데이터를 제작하여 딥러닝 탐지/분류 네트워크의 학습에 활용하고, 이를 실측 SAR 씬 내의 지상 차량표적을 탐지 및 분류하는데 적용하여 탐지확률, 오경보율, 분류확률과 같은 성능을 산출하였다. 네트워크 학습 시에는 예측영상 기반 학습 데이터만을 활용하거나 실측영상 기반 학습 데이터의 포함 비율을 변화시켰으며, 그에 따른 성능분석을 수행하였다. 실험의 결과는 생성(generative) 네트워크에 의한 영상변환이나 태스크 지향 도메인 적응(task driven domain adaptation)과 같은 기법 없이 데이터 자체로부터 획득하였으며, 이로부터 다음의 한계점 및 보완사항을 도출할 수 있다.
① 탐지성능 : 시험용 SAR 씬의 전반적 탐지/분류 난이도가 정형화된 표적배치 및 알려진 표적종류, 획득기하의 유사성, 고정적인 주변 환경 등으로 인해 낮은 편이다. 그러나 이들 중 일부는 성능향상에 기여할 수 있는 사전정보로 활용할 수도 있다.
② 분류성능 : 탐지/분류 대상 표적에 대해 실제와 흡사하게 정밀 CAD 모델링이 가능했다. 이는 접근이 불가능한 표적에는 해당되지 않으며, 모델링 정확도의 한계를 딥러닝 기법 등과 같은 기술적 보완으로써 극복하여야 한다.
③ 성능분석 : 상기 실험결과에 대한 분석사항을 정량적으로 뒷받침할 수 있는 근거에 대한 연구가 필요하다. 또한 예측영상과 실측영상을 함께 학습에 이용하는데 있어서 본 논문에서와 같이 처음부터(from the scratch) 학습하는 경우와, 수량이 비교적 많은 예측영상(합성 데이터)으로 학습 후 실측영상을 전이 학습하는 경우 성능을 비교 분석하는 것 또한 향후 연구 방향이 될 것이다.
후 기
이 논문은 2023년 정부의 재원으로 수행된 연구 결과임.








