



м„ң лЎ
мһ мҲҳн•Ёмқҳ мӨ‘мҡ”м„ұкіј к°Җм№ҳлҠ” л¬ҙкё°мІҙкі„лЎңм„ң ліёкІ©м Ғмқё м—ӯн• мқ„ мӢңмһ‘н•ң 1м°Ё м„ёкі„лҢҖм „ мқҙлһҳ лӢӨм–‘н•ң н•ҙмғҒм „м—җм„ң мһ…мҰқлҗҳм–ҙ мҷ”лӢӨ. 2м°Ё м„ёкі„лҢҖм „ лӢ№мӢң мҳҒкөӯ мҲҳмғҒмңјлЎң мһ¬мһ„н•ҳмҳҖлҚҳ мңҲмҠӨн„ҙ мІҳм№ мқҖ вҖңм „мҹҒкё°к°„ мӨ‘ м •л§җ лӮҳлҘј л‘җл өкІҢ н–ҲлҚҳ лӢЁ н•ҳлӮҳмқҳ л¬ҙкё°вҖқлЎң мң ліҙнҠёлҘј м–ёкёүн•ҳмҳҖмңјл©°, 1982л…„ нҸ¬нҒҙлһңл“ң н•ҙм „м—җм„ң м•„лҘҙн—ЁнӢ°лӮҳмқҳ лӢЁ 1мІҷмқҳ мһ мҲҳн•ЁмқҖ мҳҒкөӯмқҳ кё°лҸҷн•ЁлҢҖк°Җ 34мқј лҸҷм•Ҳ л°©м–ҙм Ғмқё лҢҖмһ м „мқ„ мҲҳн–үн•ҳлҸ„лЎқ к°•мҡ”н•ҳмҳҖлӢӨ[1]. мқҙмІҳлҹј мһ мҲҳн•ЁмқҖ мқҖл°Җм„ұ, кіөм„ём„ұ, м–өм ң л°Ҹ л°©м–ҙмҲҳлӢЁмңјлЎңм„ңмқҳ мң мҡ©м„ұмқ„ л°”нғ•мңјлЎң нҳ„лҢҖн•ҙмғҒм „мқҳ мЈјлҸ„к¶Ңмқ„ мўҢмҡ°н• мҲҳ мһҲлҠ” м „лһөм Ғмқё л¬ҙкё°мІҙкі„мқҙлӢӨ.
н•ңнҺё л¶Ғн•ңмқҖ 1960л…„лҢҖл¶Җн„° мң„мҠӨнӮӨкёү мһ мҲҳн•Ёмқ„ ліҙмң н•ҳкё° мӢңмһ‘н•ҳм—¬ мғҒм–ҙкёү, м—°м–ҙкёү л“ұ 70вҲј80м—¬мІҷмқҳ мһ мҲҳн•Ё(м •)мқ„ ліҙмң мӨ‘мқҙл©°, мқҙлҘј нҷңмҡ©н•ҳм—¬ мҡ°лҰ¬ н•ҙм—ӯмқ„ м№ЁлІ”н•ҙ м ҒлҢҖ н–үмң„лҘј н• к°ҖлҠҘм„ұмқҙ н•ӯмғҒ лҸ„мӮ¬лҰ¬кі мһҲлӢӨ. мӢӨм ңлЎң л¶Ғн•ңмқҖ 1996л…„ мғҒм–ҙкёү мһ мҲҳн•Ё к°•лҰүм№ЁнҲ¬, 1998л…„ мң кі кёү мһ мҲҳм • мҶҚмҙҲм№ЁнҲ¬, 2010л…„ м—°м–ҙкёү мһ мҲҳм • мІңм•Ҳн•Ё нҸӯм№Ё л“ұмқ„ мһҗн–үн•ң л°” мһҲлӢӨ. лҝҗл§Ң м•„лӢҲлқј, кІҪмҹҒм ҒмңјлЎң мһ мҲҳн•Ё м „л Ҙ мҰқк°•м—җ л°•м°ЁлҘј к°Җн•ҳкі мһҲлҠ” мЈјліҖкөӯмқҳ мһ мҲҳн•Ё лҳҗн•ң мң мӮ¬мӢң м ңн•ҙк¶Ң нҷ•ліҙмҷҖ н•ҙмғҒкөҗнҶөлЎң көҗлһҖмқ„ мң„н•ҙ мҡ°лҰ¬ н•ҙм—ӯм—җм„ң нҷңлҸҷн• к°ҖлҠҘм„ұмқҙ мЎҙмһ¬н•ңлӢӨ. лҢҖн•ңлҜјкөӯ н•ҙкө°мқҖ мқҙк°ҷмқҖ л¶Ғн•ң л°Ҹ мЈјліҖкөӯ мһ мҲҳн•Ёмқҳ мң„нҳ‘м—җ лҢҖ비н•ҳкё° мң„н•ҳм—¬ мһ мҲҳн•Ёмқ„ мЎ°кё°м—җ нғҗм§Җн• мҲҳ мһҲлҠ” лҠҘл Ҙ нҷ•м¶©мқҙ м ҲмӢӨнһҲ н•„мҡ”н•ҳлӢӨ.
мһ мҲҳн•Ёмқҳ нғҗм§ҖлҘј мң„н•ҙм„ңлҠ” нҒ¬кІҢ мқҢн–Ҙ, 비мқҢн–Ҙ нғҗм§Җл°©лІ•мқҙ мӮ¬мҡ©лҗҳлҠ”лҚ°, мқҢн–Ҙ нғҗм§Җл°©лІ•мқҖ мҲҳмӨ‘м—җм„ңлҠ” мһҳ м „лӢ¬лҗҳм§Җ м•ҠлҠ” м „мһҗнҢҢ лҢҖмӢ мқҢнҢҢлҘј мқҙмҡ©н•ҳм—¬ мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳлҠ” л°©лІ•мқҙлӢӨ. к·ёлҹ¬лӮҳ мқҢнҢҢлҸ„ мҲҳмӨ‘м—җм„ңмқҳ көҙм Ҳ, мӮ°лһҖмңјлЎң мқён•ҙ мһҳ м „лӢ¬лҗҳм§Җ м•Ҡмқ„ мҲҳ мһҲкі , лҚ”л¶Ҳм–ҙ н•ңл°ҳлҸ„ мЈјліҖн•ҙм—ӯмқҳ ліөмһЎн•ң н•ҙм–‘нҷҳкІҪмқҖ мқҢнҢҢлҘј нҶөн•ң мһ мҲҳн•Ё нғҗм§ҖлҘј лҚ”мҡұ м–ҙл өкІҢ л§Ңл“Өкі мһҲлӢӨ. нҠ№нһҲ, лҸ…нҠ№н•ң көҙм ҲлҘ мқ„ к°Җ진 мқҢн–Ҙл©”нғҖл¬јм§Ҳкіј к°ҷмқҙ мһ мҲҳн•Ёмқҳ мқҖл°Җм„ұмқ„ лҚ”мҡұ ліҙмһҘн•ҳлҠ” кё°мҲ л“Өмқҙ м ‘лӘ©лҗңлӢӨл©ҙ мһ мҲҳн•Ёмқҳ мқҢн–Ҙ нғҗм§ҖлҠ” лҚ”мҡұ нһҳл“Өм–ҙм§Ҳ кІғмһ„мқҙ 분лӘ…н•ҳлӢӨ.
비мқҢн–Ҙ нғҗм§Җл°©лІ•мқҖ мҲҳмғҒн•ЁмқҙлӮҳ н•ӯкіөкё°м—җм„ң мҡҙмҡ©н•ҳлҠ” нғҗм§Җл ҲмқҙлҚ”, м Ғмҷём„ нғҗм§ҖмһҘ비, лӢ№м§Ғмһҗмқҳ мҢҚм•ҲкІҪ л°Ҹ мңЎм•ҲмңјлЎң мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳлҠ” л°©лІ•мңјлЎң мһ л§қкІҪмӢ¬лҸ„(Periscope depth)м—җм„ң н•ӯн•ҙн•ҳл©ҙм„ң л§ҲмҠӨнҠём„ёнҠё(Mast set)лҘј мҡҙмҡ©н•ҳлҠ” мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳкё° мң„н•ҙ мӮ¬мҡ©лҗҳл©°, мқҢн–Ҙ нғҗм§Җл°©лІ•мқ„ ліҙмҷ„н•ҳкё° мң„н•ҙ н•„мҲҳм ҒмңјлЎң мҲҳн–үлҗҳлҠ” л°©лІ•мқҙлӢӨ. нҠ№нһҲ, м¶•м „м§Җ м¶©м „мқҙлӮҳ н•ҙмғҒкҙҖмёЎ, мң„м№ҳліҙм •, кіөкІ©м§Ғм „ лӘ©н‘ңл¬ј нҷ•мқё л“ұмқ„ мң„н•ҙ мҲҳл©ҙ к°Җк№ҢмқҙлЎң л¶ҖмғҒн•ҳлҠ” кІғмқҙ кјӯ н•„мҡ”н•ң л””м Өмһ мҲҳн•Ёмқ„[2] нғҗм§Җн•ҳлҠ”лҚ° мң мҡ©н•ҳл©°, л¶ҖмғҒн•ҳлҠ” мӢңкё°к°Җ мһ мҲҳн•Ёмқҙ к°ҖмһҘ м·Ём•Ҫн•ң мӢңкё°мқҙлҜҖлЎң мҲҳмғҒн•Ё л°Ҹ н•ӯкіөкё°лҠ” мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳкё° мң„н•ҙ мқҙлҘј нҡЁкіјм ҒмңјлЎң нҷңмҡ©н•ҳм—¬м•ј н•ңлӢӨ.
к·ёлҹ¬лӮҳ 비мқҢн–Ҙ нғҗм§Җл°©лІ• лҳҗн•ң м ңм•ҪмӮ¬н•ӯл“Өмқҙ мһҲлҠ”лҚ°, л§ҲмҠӨнҠём„ёнҠёлҘј мҡҙмҡ©н•ҳлҠ” мһ мҲҳн•Ёмқ„ нғҗм§Җн• мҲҳ мһҲлҠ” мӢңк°„мқҙ м§§кі , мһ мҲҳн•Ёмқём§Җ нҢҗлӢЁн•ҳлҠ”лҚ° мҲҳмғҒн•Ё к·јл¬ҙмһҗмқҳ м§ҒкҙҖкіј кІҪн—ҳм—җ нҒ¬кІҢ мқҳмЎҙн•ңлӢӨлҠ” кІғмқҙлӢӨ. нҠ№нһҲ, мһ мҲҳн•Ё мқҳ 비мқҢн–Ҙ нғҗм§ҖмҲҳлӢЁмңјлЎң мң мҡ©н•ҳкІҢ м—¬кІЁм§ҖлҠ” л°©лІ• мӨ‘ н•ҳлӮҳмқё мҢҚм•ҲкІҪмқҙлӮҳ мңЎм•ҲмңјлЎң м „л°©мқ„ к°җмӢңн•ҳм—¬ нғҗм§Җн•ҳлҠ” л°©лІ•мқҖ лҢҖл¶Җ분 мҲҳмғҒн•Ё к·јл¬ҙ кІҪл Ҙмқҙ 짧мқҖ н•ҙмғҒлі‘мқҙ к·ё мһ„л¬ҙлҘј мҲҳн–үн•ҳкі мһҲм–ҙ нҡЁкіјм Ғмқё нғҗм§ҖлҘј лҚ”мҡұ м–ҙл өкІҢ н•ҳл©°, к·ёл§Ҳм ҖлҸ„ м Җм¶ңмӮ° мӢңлҢҖлЎң мқён•ң көӯл°©к°ңнҳҒмңјлЎңм җм°Ё лі‘л Ҙмқ„ к°җ축н•ҙ лӮҳк°Ҳ кІғмқ„ кі л Өн•ҳл©ҙ мһ„л¬ҙлҘј мҲҳн–үн•ҙм•ј н• мқёмӣҗмқҙ к°ҲмҲҳлЎқ л¶ҖмЎұн•ҙм§Ҳ м „л§қмқҙлӢӨ.
мқҙм—җ ліё м—°кө¬лҠ” 4м°Ё мӮ°м—…нҳҒлӘ…мқҳ мӨ‘мӢ¬кё°мҲ мқё л”Ҙлҹ¬лӢқ мӨ‘м—җм„ңлҸ„ мқҙлҜём§Җ мқёмӢқм—җ мөңм Ғнҷ”лҗң CNN(Convolutional Neural Network) лӘЁлҚёмқ„ 비мқҢн–Ҙ нғҗм§Җм—җ нҷңмҡ©н•ҳм—¬ мһ л§қкІҪмқ„ 비лЎҜн•ң мҠӨл…ёнҒҙ(Snorkel), нҶөмӢ , ES(Electronic Support) л“ұмқҳ л§ҲмҠӨнҠёлҘј мҡҙмҡ©мӨ‘мқё мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳлҠ” л°©м•Ҳмқ„ мөңмҙҲлЎң м ңмӢңн•ҳмҳҖлӢӨ. лҳҗн•ң мҲҳл©ҙ мң„лЎң мҳ¬лқјмҳӨлҠ” л§ҲмҠӨнҠёлҠ” мҶҢнҳ•н‘ңм ҒмқҙлҜҖлЎң 분лҘҳ м •нҷ•лҸ„к°Җ лӮ®мқ„ мҲҳ мһҲлҠ”лҚ°, мқҙлҘј ліҙмҷ„н•ҳкё° мң„н•ҙ м—¬лҹ¬ CNN лӘЁлҚёмқ„ кІ°н•©н•ң м•ҷмғҒлё”(Ensemble) лӘЁлҚёмқ„ нҷңмҡ©н•ҳм—¬ м„ұлҠҘмқ„ н–ҘмғҒмӢңнӮӨлҠ” л°©м•Ҳмқ„ лӘЁмғүн•ҳмҳҖлӢӨ. 2мһҘм—җм„ңлҠ” мһ мҲҳн•Ё нғҗм§Җл°©лІ•мқ„ мқҙлЎ м ҒмңјлЎң кі м°°н•ҳмҳҖмңјл©°, CNN лӘЁлҚёмқ„ нҷңмҡ©н•ҳм—¬ мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳкі мһҗ н•ң м„ н–үлҗң м—°кө¬л“Өмқ„ мҶҢк°ңн•ҳмҳҖлӢӨ. 3мһҘм—җм„ңлҠ” ліё м—°кө¬м—җм„ң м ңмӢңн•ң мһ мҲҳн•Ё 분лҘҳ лӘЁлҚёмқ„ мҶҢк°ңн•ҳмҳҖкі , 4мһҘм—җм„ңлҠ” лҚ°мқҙн„°лҘј мҲҳ집н•ң нӣ„ 3мһҘм—җм„ң мҶҢк°ңн•ң мһ мҲҳн•Ё 분лҘҳ лӘЁлҚём—җ л”°лқј м—¬лҹ¬ CNN лӘЁлҚёмқҳ м Ғн•©н•ң н•ҳмқҙнҚјнҢҢлқјлҜён„°(Hyperparameter)лҘј нғҗмғүн•ҳкі , лӢӨм–‘н•ң м•ҷмғҒлё” лӘЁлҚёмқ„ нҷңмҡ©н•ҳм—¬ м„ұлҠҘмқҳ н–ҘмғҒ м—¬л¶ҖлҘј нҷ•мқён•ҳмҳҖлӢӨ. 5мһҘм—җм„ңлҠ” м—°кө¬кІ°лЎ л°Ҹ м ңн•ңмӮ¬н•ӯмқ„ м ңмӢңн•ҳмҳҖлӢӨ.
кё°мЎҙ м—°кө¬ лҸҷн–Ҙ
2.1 мһ мҲҳн•Ё нғҗм§Җм—җ лҢҖн•ң мқҙлЎ м Ғ кі м°°
2.1.1 мһ мҲҳн•Ё мқҢн–Ҙ нғҗм§Җмқҳ н•ңкі„
мқҢнҢҢлҠ” мҲҳмӨ‘м—җм„ң м „мһҗнҢҢліҙлӢӨ нӣЁм”¬ л№ лҘҙкі л©ҖлҰ¬ м „лӢ¬лҗҳкё° л•Ңл¬ём—җ мқҙлҘј мқҙмҡ©н•ң лҢҖмһ к°җмӢңк°Җ мҡ°мҲҳн•ң нғҗм§ҖмҲҳлӢЁмһ„мқҖ 분лӘ…н•ҳм§Җл§Ң, мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳкё° мң„н•ң мң мқјн•ң мҲҳлӢЁмңјлЎңм„ңлҠ” л§ҺмқҖ м ңм•Ҫмқҙ мһҲлӢӨ[3].
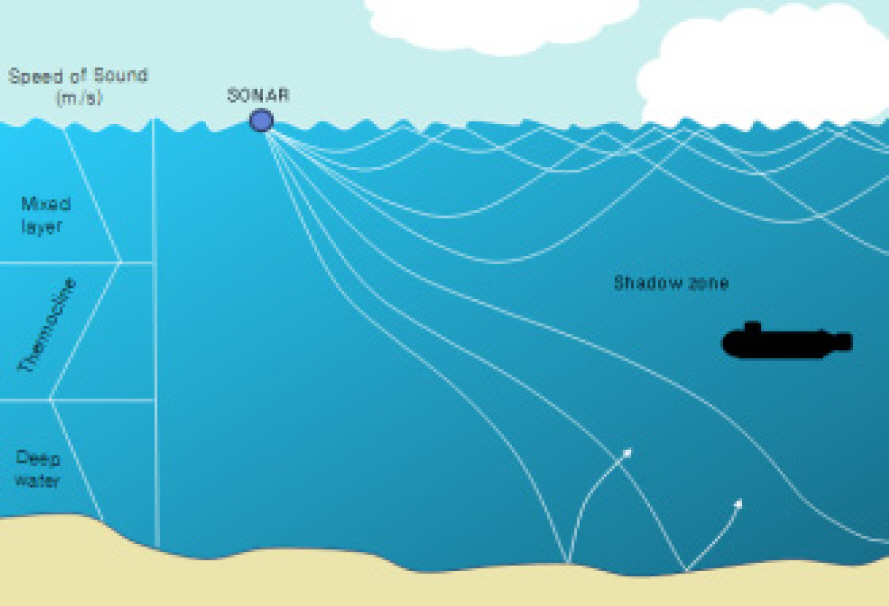
к·ё мқҙмң лҘј мӮҙнҺҙліҙл©ҙ, мІ«м§ё, мқҢнҢҢлҠ” мҲҳмӨ‘м—җм„ң нҷ•мӮ°кіј к°җмҮ лЎң мқён•ң м „лӢ¬мҶҗмӢӨмқ„ к°Җм§ҖлҜҖлЎң м „лӢ¬лҗҳл©ҙм„ң мқҢмқҳ к°•лҸ„к°Җ м җм°Ё к°җмҶҢлҗҳм–ҙ нғҗм§Җкұ°лҰ¬к°Җ 짧아진лӢӨ. л‘ҳм§ё, мқҢнҢҢлҠ” Fig. 1кіј к°ҷмқҖ мқҢмҶҚмқҳ мҲҳм§Ғкө¬мЎ°м—җ мқҳн•ҙ нҳјн•©мёө(Mixed layer), мҲҳмҳЁм•Ҫмёө(Thermocline), мӢ¬н•ҙмёө(Deep water)мқ„ нҳ•м„ұн•ҳлҠ”лҚ°, к°Ғ мёөлі„лЎң мқҢнҢҢм „лӢ¬ м–‘мғҒмқҙ лӢ¬лқј мқҢнҢҢк°Җ м „лӢ¬лҗҳм§Җ м•ҠлҠ” мқҢмҳҒкө¬м—ӯмқ„ л°ңмғқмӢңнӮ¬ мҲҳ мһҲлӢӨ. м…Ӣм§ё, л¬јлҰ¬м Ғ нҷ”н•ҷм Ғ нҠ№м„ұмқҙ м„ңлЎң лӢӨлҘё н•ҙмҲҳк°Җ л§ҢлӮҳ мғқм„ұлҗҳлҠ” мҲҳмҳЁм „м„ л°Ҹ мҷҖлҸҷлҘҳлЎң мқён•ҙ мқҢнҢҢм „лӢ¬ нҠ№м„ұмқҙ кёүкІ©н•ҳкІҢ ліҖнҷ”н•ҳм—¬ нғҗм§Җкұ°лҰ¬к°Җ к°җмҶҢлҗ мҲҳ мһҲлӢӨ. л„·м§ё, нҢҢлҸ„мҶҢлҰ¬, м–ҙлҘҳм—җ мқҳн•ң мҶҢлҰ¬, мң мІҙмҶҢмқҢ л“ұмқҳ к°Ғмў… л°°кІҪмҶҢмқҢмңјлЎң мқён•ҙ н‘ңм ҒмҶҢмқҢмқҳ нғҗм§Җк°Җ м ңн•ңлҗ мҲҳ мһҲлӢӨ. мқҙмІҳлҹј мқҢнҢҢлҠ” мҲҳмӨ‘м—җм„ң л¬јмІҙлҘј нғҗм§Җн•ҳлҠ”лҚ° мҡ°мҲҳн•ң мҲҳлӢЁмқҙлӮҳ м–ёкёүн•ң м ңм•ҪмӮ¬н•ӯл“Өмқ„ к°Җм§Җл©°, мқҙлҘј ліҙмҷ„н• мҲҳ мһҲлҠ” мҲҳлӢЁмқҙ н•„мҡ”н•ҳлӢӨ.
2.1.2 мһ мҲҳн•Ё 비мқҢн–Ҙ нғҗм§Җмқҳ к°ҖлҠҘм„ұ
л””м Өмһ мҲҳн•ЁмқҖ м¶•м „м§Җ м¶©м „мқ„ мң„н•ҙм„ң л°ҳл“ңмӢң мЈјкё°м ҒмңјлЎң мҲҳл©ҙ к°Җк№ҢмқҙлЎң л¶ҖмғҒн•ҳм—¬ мҠӨл…ёнҒҙмқ„ н•ҳм—¬м•ј н•ңлӢӨ. мһ мҲҳн•ЁмқҖ мҲҳмӨ‘н•ӯн•ҙмӢң м¶•м „м§Җм—җ м ҖмһҘлҗң м „л ҘмңјлЎң 추진 м „лҸҷкё°лҘј кө¬лҸҷн•ҳкі , мқҙ м „лҸҷкё°м—җ м—°кІ°лҗң н”„лЎңнҺ лҹ¬лҘј нҡҢм „мӢңнӮҙмңјлЎңмҚЁ 추진л Ҙмқ„ м–»кІҢ лҗңлӢӨ. к·ёлҹ¬лӮҳ м¶•м „м§ҖлҠ” н•ӯн•ҙмӢң м ҖмҶҚмңјлЎң кё°лҸҷн•ҳлҚ”лқјлҸ„ м•Ҫ 2вҲј4мқјмқҙ кІҪкіјн•ҳл©ҙ лӘЁл‘җ л°©м „лҗҳл©°, мқҙлҘј м¶©м „н•ҳкё° мң„н•ҙм„ңлҠ” л””м Ө엔진мқ„ кө¬лҸҷмӢңмјңм•ј н•ҳлҠ”лҚ°, л””м Ө엔진 кө¬лҸҷмқ„ мң„н•ҙм„ң л°ҳл“ңмӢң кіөкё°лҘј кіөкёүн•ҙ мЈјм–ҙм•ј н•ҳлҜҖлЎң кіөкё°лҘј нқЎмһ…н•ҳкё° мң„н•ҙ мҲҳл©ҙ к°Җк№ҢмқҙлЎң л¶ҖмғҒн•ҙм•ј н•ҳлҠ” кІғмқҙлӢӨ. мқҙл•Ң мһ мҲҳн•ЁмқҖ мҲҳл©ҙ мң„лЎң мҷ„м „нһҲ л¶ҖмғҒн•ҳм§Җ м•Ҡкі , мҲҳл©ҙ л°‘ мқјм • к№Ҡмқҙм—җм„ң мҠӨл…ёнҒҙ л§ҲмҠӨнҠёл§Ңмқ„ мҲҳл©ҙ мң„лЎң лӮҙл°Җм–ҙ кіөкё°лҘј нқЎмһ…н•ңлӢӨ. мқҙлҹ¬н•ң нҠ№м„ұмқҖ л¶Ғн•ң л°Ҹ мЈјліҖкөӯ л””м Өмһ мҲҳн•ЁлҸ„ лҸҷмқјн•ңлҚ°, кіјкұ° л¶Ғн•ңмқҳ м№ЁнҲ¬мӮ¬лЎҖлҘј 분м„қн•ҳмҳҖмқ„ л•ҢлҸ„ л¶Ғн•ң мһ мҲҳн•ЁмқҖ NLL л¶Ғл°©м—җм„ңл¶Җн„° мһ н•ӯн•ҳм—¬ мҡ°лҰ¬н•ҙм—ӯмңјлЎң 진мһ…нӣ„ м¶•м „м§Җ м¶©м „мңЁ 00 % лҸ„лӢ¬ мӢң м•јк°„мқ„ нӢҲнғҖ 0мӢңк°„ мқҙмғҒ мҠӨл…ёнҒҙмқ„ н•ҳмҳҖмқҢмқҙ л°қнҳҖ진 л°” мһҲлӢӨ[4].
н•ңнҺё, мһ мҲҳн•ЁмқҖ мҠӨл…ёнҒҙ мҷём—җлҸ„ мҲҳл©ҙ к°Җк№ҢмқҙлЎң л¶ҖмғҒн•ҳм—¬ л§ҲмҠӨнҠём„ёнҠёлҘј мҡҙмҡ©н•ҳлҠ” кІҪмҡ°к°Җ мһҲлҠ”лҚ°, к·ё лҢҖн‘ңм Ғмқё кІҪмҡ°к°Җ мһ л§қкІҪ(Periscope)мқ„ мҡҙмҡ©н• л•ҢмқҙлӢӨ. мһ л§қкІҪмқҖ кіөкІ©мһ л§қкІҪ(Attack periscope)кіј нғҗмғүмһ л§қкІҪ(Search periscope)мңјлЎң кө¬л¶„лҗҳлҠ”лҚ°, кіөкІ©мһ л§қкІҪмқҖ кіөкІ© м§Ғм „ лӘ©н‘ңл¬јмқҳ л°©мң„ л“ұмқ„ мөңмў…м ҒмңјлЎң нҷ•мқён•ҳкё° мң„н•ҙ мӮ¬мҡ©н•ҳл©°, нғҗмғүмһ л§қкІҪмқҖ н•ҙмғҒ кҙҖмёЎмҡ© лҳҗлҠ” GPS(Global Positioning System)лҘј нҶөн•ң мң„м№ҳліҙм •мқ„ мң„н•ҙ мӮ¬мҡ©н•ңлӢӨ. мһ мҲҳн•Ёмқҙ мҲҳмғҒн•Ём—җ лҢҖн•ң кіөкІ©мқ„ н•ңлӢӨл©ҙ мҲҳмӨ‘м—җм„ң мҲҳлҸҷмҶҢлӮҳ(Passive sonar)лҘј мқҙмҡ©н•ҳм—¬ лӘ©н‘ңл¬јмқҳ л°©мң„В·мҶҚлҸ„лҘј нҢҢм•…н•ҳкІҢ лҗҳлҠ”лҚ°, л¶Ғн•ңмһ мҲҳн•Ём—җ м„Өм№ҳлҗң мҲҳлҸҷмҶҢлӮҳлҠ” к·ё м„ұлҠҘмқҙ м Җкёүн•ҳм—¬ мҲҳмӨ‘м—җм„ңмқҳ кіөкІ© л¬ём ңн•ҙкІ°мқҙ м ңн•ңлҗҳлҜҖлЎң мһ л§қкІҪмңјлЎң мөңмў… лӘ©н‘ңл¬јмқ„ нҷ•мқён• нҷ•лҘ мқҙ л§Өмҡ° лҶ’мқ„ кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ[5]. мқҙлҘј л’·л°ӣм№Ён•ҙ мЈјл“Ҝмқҙ л¶Ғн•ңмқҳ кіјкұ° м№ЁнҲ¬ мӮ¬лЎҖм—җм„ңлҸ„ мқјлӘ° м§Ғнӣ„м—җ мҡ°лҰ¬н•ҙм—ӯм—җм„ң мһ л§қкІҪмқ„ мҡҙмҡ©н•ҳм—¬ кіөкІ© лӘ©н‘ңлӮҳ н•ҙм•Ҳмқ„ м •м°°н•ҳмҳҖмқҢмқҙ л“ңлҹ¬лӮң л°” мһҲлӢӨ.
мқҙмІҳлҹј мһ мҲҳн•ЁмқҖ Fig. 2мҷҖ к°ҷмқҙ мҠӨл…ёнҒҙ л§ҲмҠӨнҠё, мһ л§қкІҪ л“ұмңјлЎң кө¬м„ұлҗң л§ҲмҠӨнҠём„ёнҠёлҘј мҡҙмҡ©н•ңлӢӨ. мқҙл•Ңк°Җ мһ мҲҳн•Ём—җкІҢлҠ” к°ҖмһҘ м·Ём•Ҫн•ң мӢңкё°мқҙл©°, 1997л…„ м„ңн•ҙ мҶҢнқ‘мӮ°лҸ„ к·јн•ҙ мһ л§қкІҪмңјлЎң ліҙмқҙлҠ” л¬јмІҙлҘј л°ңкІ¬н–ҲлӢӨлҠ” м–ҙлҜјмқҳ мӢ кі лЎң мӨ‘көӯмқҳ л°Қкёү мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳм—¬ л¶ҖмғҒмӢңнӮЁ мӮ¬лЎҖлҸ„ мһҲлӢӨ[7]. л”°лқјм„ң мҲҳмғҒн•Ё л°Ҹ н•ӯкіөкё°м—җм„ңлҠ” л ҲмқҙлҚ” лҝҗл§Ң м•„лӢҲлқј мҢҚм•ҲкІҪ л°Ҹ мңЎм•Ҳмқ„ мқҙмҡ©н•ҳм—¬ мқҙлҘј м Ғк·№м ҒмңјлЎң нғҗм§Җн• н•„мҡ”к°Җ мһҲлӢӨ. н•ҳм§Җл§Ң, м„ңлЎ м—җм„ң м–ёкёүн•ң кІғкіј к°ҷмқҙ нҢҗлӢЁн• мҲҳ мһҲлҠ” мӢңк°„мқҙ м§§кі мҲҳмғҒн•Ё к·јл¬ҙмһҗмқҳ кІҪн—ҳкіј нҢҗлӢЁмқҳ к°ңмһ…мқҙ м»Ө нҡЁкіјм ҒмңјлЎң нғҗм§Җн•ҳлҠ” кІғмқҙ м–ҙл өлӢӨ. л”°лқјм„ң мҲҳмғҒн•Ём—җм„ң мҡҙмҡ©н•ҳкі мһҲлҠ” TVм№ҙл©”лқјлЎң нҡҚл“қн•ҳлҠ” мҳҒмғҒм—җ 4м°Ё мӮ°м—…нҳҒлӘ…мқҳ лҢҖн‘ңм Ғмқё кё°мҲ мқё л”Ҙлҹ¬лӢқ кё°мҲ мқ„ м Ғмҡ©н•ңлӢӨл©ҙ мһ мҲҳн•Ё л§ҲмҠӨнҠёмқҳ мҲҳл©ҙмң„ л…ём¶ңмқ„ нҡЁкіјм ҒмңјлЎң нҸ¬м°©н• мҲҳ мһҲмқ„ лҝҗл§Ң м•„лӢҲлқј мҲҳмғҒн•Ё к·јл¬ҙмһҗмқҳ кІҪн—ҳм Ғ мҡ”мҶҢлӮҳ мҷёл¶Җ нҷҳкІҪмҡ” мҶҢмқҳ мҳҒн–Ҙмқ„ л°ӣм§Җ м•Ҡкі нҡЁмңЁм ҒмңјлЎң мһ мҲҳн•Ёмқ„ нғҗм§Җн• мҲҳ мһҲмқ„ кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ.

2.2 CNN лӘЁлҚёкіј мһ мҲҳн•Ё нғҗм§Җ
ліё м—°кө¬м—җм„ң мһ мҲҳн•Ёмқҳ л§ҲмҠӨнҠёлҘј нғҗм§Җн•ҳкё° мң„н•ҙ м Ғмҡ©н•ң лӘЁлҚёмқҖ л”Ҙлҹ¬лӢқ м•Ңкі лҰ¬мҰҳ мӨ‘ мқҙлҜём§Җ 분야лҘј лӢӨлЈЁкё°м—җ мөңм Ғнҷ”лҗң CNN(Convolutional Neural Network) лӘЁлҚёмқҙлӢӨ. CNNмқҖ нҒ¬кІҢ м»ЁліјлЈЁм…ҳмёө(Convolution layer)кіј н’Җл§Ғмёө(Pooling layer), мҷ„м „м—°кІ°мёө(Fully-connected layer)мңјлЎң кө¬м„ұлҗҳм–ҙ мһҲлӢӨ. м»ЁліјлЈЁм…ҳмёөмқҖ м»ЁліјлЈЁм…ҳ м—°мӮ°мқ„ нҶөн•ҙ мқҙлҜём§Җмқҳ нҠ№м§•мқ„ 추м¶ңн•ҙ лӮҙлҠ” мёөмқёлҚ°, мӮ¬мҡ©н•ҳлҠ” н•„н„°(Filter)м—җ л”°лқј мӣҗліё мқҙлҜём§Җм—җм„ң лӢӨм–‘н•ң нҠ№м§•мқ„ 추м¶ңн•ҙ лӮј мҲҳ мһҲлӢӨ. н’Җл§Ғмёө(Pooling layer)мқҖ мөңлҢҖн’Җл§Ғ(Max pooling), нҸүк· н’Җл§Ғ(Average pooling), мөңмҶҢн’Җл§Ғ(Min pooling)мқ„ нҶөн•ҙ мқҙлҜём§Җ м°Ёмӣҗмқ„ 축мҶҢн•ЁмңјлЎңмҚЁ н•„мҡ”н•ң м—°мӮ°лҹүмқ„ к°җмҶҢмӢңнӮӨкі , мқҙлҜём§Җмқҳ к°•н•ң нҠ№м§•л§Ңмқ„ м„ лі„н•ңлӢӨ[8]. мҷ„м „м—°кІ°мёө(Fully-connected layer)мқҖ м»ЁліјлЈЁм…ҳмёөмқҳ 3м°Ёмӣҗ м¶ңл Ҙк°’мқ„ 1м°Ёмӣҗ лІЎн„°лЎң л§Ңл“Өм–ҙ м¶ңл Ҙмёөмқҙ мқҙлҜём§Җмқҳ мөңмў… 분лҘҳлҘј н• мҲҳ мһҲлҸ„лЎқ нҢҗлӢЁн•ҳлҠ” к°’мқ„ м ңкіөн•ңлӢӨ.
CNN лӘЁлҚёкіј к°ҷмқҖ л”Ҙлҹ¬лӢқ кё°мҲ мқ„ нҷңмҡ©н•ҳм—¬ мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳл ӨлҠ” м—°кө¬лҠ” мЈјлЎң мқҢн–Ҙ нғҗм§Җ분야м—җм„ң мқҙлЈЁм–ҙ мЎҢлӢӨ. Kim et al.[9]мқҖ лҠҘлҸҷмҶҢлӮҳм—җм„ң мһ мҲҳн•Ё лҳҗлҠ” кё°лў°лҘј л°”мң„мҷҖ к°ҷмқҖ 비н‘ңм Ғкіј кө¬л¶„н•ҳкё° мң„н•ҙ CNN лӘЁлҚё мӨ‘ н•ҳлӮҳмқё Alexnet лӘЁлҚёмқ„ мқјл¶Җ ліҖкІҪн•ҳм—¬ н•ҷмҠөн•ҳл©ҙм„ң, лҚ°мқҙн„°мқҳ м–‘м—җ л”°лҘё лӘЁлҚё м„ұлҠҘ ліҖнҷ”лҘј нҷ•мқён•ҳмҳҖлӢӨ. Kim et al.[10]мқҖ лҠҘлҸҷмҶҢлӮҳм—җ мқҳн•ң н‘ңм Ғ мқҙлҜём§ҖлҘј лҚ°мқҙн„° нҷ•мһҘн•ҳкі , мғқм„ұлҗң мқҙлҜём§Җк°Җ н‘ңм Ғмқ„ нҸ¬н•Ён•ҳлҠ” 비мңЁм—җ л”°лқј CNN лӘЁлҚёмқ„ нҷңмҡ©н•ҳм—¬ н‘ңм Ғ/비н‘ңм Ғмқ„ 분лҘҳн•ҳлҠ” м—°кө¬лҘј 진н–үн•ҳмҳҖлӢӨ. к·ё мҷём—җ мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳлҠ” м—°кө¬лЎң Kim et al.[11]мқҖ Faster R-CNNмқ„ мқҙмҡ©н•ҳм—¬ н•ҙм–‘м—җм„ңмқҳ м„ л°•мқ„ кІҖм¶ң нӣ„ н•ӯкіөлӘЁн•Ё, мһ мҲҳн•Ё, м»Ён…Ңмқҙл„Ҳм„ л“ұ 7к°Җм§ҖлЎң 분лҘҳн•ҳмҳҖлӢӨ. к·ёлҹ¬лӮҳ мқҙ м—°кө¬мқҳ лӘ©м ҒмқҖ н•ҙмғҒм—җм„ң 충лҸҢмқ„ н”јн•ҳкё° мң„н•ҙ н•ӯн•ҙн•ҳлҠ” лӢӨм–‘н•ң л¬јн‘ңл“Өмқ„ кІҖм¶ңн•ҳкі л¶„лҘҳн•ҳлҠ” кІғмңјлЎң мһ мҲҳн•Ё лҳҗн•ң мҷ„м „нһҲ л¶ҖмғҒн•ӯн•ҙн•ҳлҠ” мһ мҲҳн•Ёмқ„ кІҖм¶ңн•ҳлҠ” кІғмқҙлӢӨ. л”°лқјм„ң мқҖл°Җм„ұмқ„ мң м§Җн•ҳкі мһҗ н•ҳлҠ” мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳлҠ” ліё м—°кө¬мҷҖлҠ” лӘ©м Ғкіј 추нӣ„ лӘЁлҚё нҷңмҡ© л°©лІ•мқҙ лӢӨлҘҙлӢӨ.
CNN лӘЁлҚёмқҳ м•ҷмғҒлё”мқ„ мӢӨн—ҳн•ң м—°кө¬лЎң Park et al.[12]мқҖ мӮ°лҰјкіӨ충 лҚ°мқҙн„°м„ёнҠём—җ лҢҖн•ҙ CNN лӘЁлҚёмқҳ м•ҷмғҒлё” кІ°н•© л°©лІ•м—җ л”°лҘё м„ұлҠҘ 분м„қм—җ кҙҖн•ң м—°кө¬лҘј 진н–үн•ҳмҳҖмңјл©°, B. S. Kim[13]мқҖ мһ¬нҷңмҡ©м“°л Ҳкё° лҚ°мқҙн„°м„ёнҠём—җ лҢҖн•ҙ CNN лӘЁлҚёмқ„ нҷңмҡ©н•ҳм—¬ лҜём„ёмЎ°м •(Fine tuning), м•ҷмғҒлё” лӢЁкі„лҘј кұ°м№ҳл©ҙм„ң м„ұлҠҘмқҙ н–ҘмғҒлҗЁмқ„ ліҙмқҙкі , мқҙ лӘЁлҚёмқҙ кё°мЎҙм—җ мӮ¬мҡ©лҗҳм—ҲлҚҳ лӘЁлҚёмқё SVM(Support Vector Machine)м—җ 비н•ҙ м„ұлҠҘмқҙ мҡ°мҲҳн•Ёмқ„ нҷ•мқён•ҳмҳҖлӢӨ. мқҙм—җ ліё м—°кө¬лҠ” мһ мҲҳн•Ё 비мқҢн–Ҙ нғҗм§Җ분야м—җ мөңмҙҲлЎң CNN лӘЁлҚёмқ„ м Ғмҡ©мӢңмјң мһ мҲҳн•Ёмқҳ л§ҲмҠӨнҠёмҷҖ н•ӯн•ҙ мӨ‘ мң мӮ¬н•ҳкІҢ ліҙмқј мҲҳ мһҲлҠ” н‘ңм Ғл“Өмқ„ 분лҘҳн•ҳкі , мқҙ лӘЁлҚёл“Өмқ„ кІ°н•©н•ң м•ҷмғҒлё” лӘЁлҚёмқ„ нҷңмҡ©н•ЁмңјлЎңмҚЁ мһ мҲҳн•Ё 비мқҢн–Ҙ нғҗм§ҖмңЁ н–ҘмғҒл°©м•Ҳмқ„ м ңмӢңн•ҳкі мһҗ н•ңлӢӨ.
м ңм•Ҳн•ң мһ мҲҳн•Ё 분лҘҳ лӘЁлҚё
ліё м—°кө¬лҠ” м „мҲ м Ғмқё мғҒнҷ©м—җм„ң мһ л§қкІҪмқ„ 비лЎҜн•ң л§ҲмҠӨнҠёлҘј мҳ¬лҰ¬кі н•ӯн•ҙн•ҳлҠ” мһ мҲҳн•Ёмқ„ нғҗм§Җн•ҳлҠ” кІғмқ„ мЈјлӘ©н‘ңлЎң н•ңлӢӨ. 추к°Җм ҒмңјлЎңлҠ” мһ л§қкІҪмқ„ мҳ¬лҰ¬лҠ” кІғ мҷём—җ л¶ҖмғҒн•ң мһ мҲҳн•Ё лҳҗн•ң мӢқлі„ к°ҖлҠҘн•ҳм—¬м•ј н• кІғмқҙл©°, мҲҳмғҒн•Ём—җм„ң мһ мҲҳн•Ё л§ҲмҠӨнҠёлЎң мҳӨмқё к°ҖлҠҘн•ң к№ғлҢҖл¶Җмқҙ(Flag buoy), л“ұл¶Җн‘ң(Lighted buoy), мҶҢнҳ• м–ҙм„ В·ліҙнҠё(Small boat)мҷҖ кө¬лі„ к°ҖлҠҘн• кІғмқ„ лӘ©н‘ңлЎң 진н–үн•ҳмҳҖлӢӨ.
분лҘҳ лӘЁлҚё кө¬м¶•лӢЁкі„лҠ” лҚ°мқҙн„° мҲҳ집, мқҙлҜём§Җ 분лҘҳ лӘЁлҚё н•ҷмҠө л°Ҹ нҸүк°ҖлӢЁкі„лЎң кө¬м„ұлҗңлӢӨ. мҲҳ집лҗң лҚ°мқҙн„°л“ӨмқҖ Fig. 3кіј к°ҷмқҙ 3лӢЁкі„лҘј кұ°міҗ н•ҷмҠөлҗңлӢӨ. 1, 2лӢЁкі„лҠ” мӮ¬м „ н•ҷмҠөлҗң(Pre-trained) лӘЁлҚёмқ„ мӮ¬мҡ©н•ҳм—¬ м „мқҙн•ҷмҠө(Transfer learning)мқ„ мӢӨмӢңн•ҳмҳҖлҠ”лҚ°, мӮ¬м „ н•ҷмҠөлҗң лӘЁлҚёмқҙлһҖ лҢҖк·ңлӘЁ мқҙлҜём§Җ 분лҘҳ л¬ём ңлҘј мң„н•ҙ лҢҖлҹүмқҳ лҚ°мқҙн„°м„ёнҠём—җм„ң лҜёлҰ¬ нӣҲл Ёлҗҳм–ҙ м ҖмһҘлҗң л„ӨнҠёмӣҢнҒ¬лЎң, мқјл°ҳм ҒмңјлЎң ILSVRC (Imagenet Large Scale Visual Recognition Competition)м—җм„ң 100л§ҢмһҘмқҙ л„ҳлҠ” мқҙлҜём§Җ лҚ°мқҙн„°м„ёнҠёмқё мқҙлҜём§Җл„·(Imagenet)мқ„ мқҙмҡ©н•ҳм—¬ н•ҷмҠөн•ң лӘЁлҚёмқҙ мӮ¬мҡ©лҗңлӢӨ. мқҙ лӘЁлҚём—җм„ң н•ҷмҠөлҗң нҢҢлқјлҜён„°(Parameter)мҷҖ л„ӨнҠёмӣҢнҒ¬мқҳ кө¬мЎ°лҘј мқҙмҡ©н•ҳл©ҙ мғҒлҢҖм ҒмңјлЎң мһ‘мқҖ лҚ°мқҙн„°м„ёнҠёл§ҢмңјлЎңлҸ„ мқҙлҜём§Җ 분лҘҳ лӘЁлҚёмқ„ н•ҷмҠөмӢңнӮ¬ мҲҳ мһҲлӢӨ. м—¬кё°м„ң нҢҢлқјлҜён„°лһҖ к°ҖмӨ‘м№ҳ(Weight)мҷҖ нҺён–Ҙ(Bias)мқ„ мқҳлҜён•ҳлҠ”лҚ°, л”Ҙлҹ¬лӢқм—җм„ңлҠ” н•ҷмҠөн•ҳкі мһҗ н•ҳлҠ” лҚ°мқҙн„°лҘј к°ҖмӨ‘м№ҳмҷҖ нҺён–Ҙмқ„ нҸ¬н•Ён•ң к°Җм„Өн•ЁмҲҳлЎң лӮҳнғҖлӮё нӣ„ к°Җм„Өн•ЁмҲҳк°Җ мӢӨм ңлҚ°мқҙн„° мҷҖ м–јл§ҲлӮҳ лӢӨлҘём§ҖлҘј лӮҳнғҖлӮҙлҠ” мҶҗмӢӨн•ЁмҲҳлҘј мөңмҶҢнҷ”н•ҳлҠ” л°©н–ҘмңјлЎң к°ҖмӨ‘м№ҳмҷҖ нҺён–Ҙмқ„ м—…лҚ°мқҙнҠён•ҳкІҢ лҗңлӢӨ. мҰү, нҢҢлқјлҜён„°лһҖ кё°кі„к°Җ н•ҷмҠөн•ҳл©ҙм„ң кІ°м •н•ҳлҠ” к°’мңјлЎң н•ҳмқҙнҚјнҢҢлқјлҜён„°(Hyperparameter)мҷҖлҠ” кө¬л¶„н•ҙм„ң мқҙн•ҙлҗҳм–ҙм•ј н•ҳлҠ”лҚ°, н•ҳмқҙнҚјнҢҢлқјлҜён„°лһҖ н•ҷмҠөлҘ (Learning rate), мң лӢӣ(Unit)мқҳ к°ңмҲҳ, нҷңм„ұнҷ” н•ЁмҲҳ, н•ҷмҠөм„ёлҢҖ(Epoch), л°°м№ҳ(Batch) л“ұ кё°кі„к°Җ мһҗлҸҷмңјлЎң кІ°м •н•ҳлҠ” к°’мқҙ м•„лӢҲлқј м—°кө¬мһҗк°Җ м„Өм •н•ҙмЈјм–ҙм•ј н•ҳлҠ” к°’мқҙлӢӨ.

ліё м—°кө¬мқҳ 1, 2лӢЁкі„м—җм„ң мӮ¬мҡ©н•ң м „мқҙн•ҷмҠөмқҖ кІҪмҡ°м—җ л”°лқј лҜём„ёмЎ°м •(Fine tuning)кіј к°ҷмқҖ мқҳлҜёлЎң мӮ¬мҡ©лҗҳкё°лҸ„ н•ҳм§Җл§Ң, ліё м—°кө¬м—җм„ңлҠ” нҠ№м„ұ추м¶ң(Feature extraction)кіј лҜём„ёмЎ°м • 2к°Җм§ҖлЎң 세분нҷ”н•ҳм—¬ 1лӢЁкі„м—җм„ңлҠ” нҠ№м„ұ추м¶ңмқ„ мӮ¬мҡ©н•ҳкі , 2лӢЁкі„м—җм„ң лҜём„ёмЎ°м •мқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ. нҠ№м„ұ추м¶ңмқҖ м»ЁліјлЈЁм…ҳмёөмқҳ нҢҢлқјлҜён„°лҠ” кі м •мӢңнӮӨкі мҷ„м „м—°кІ°мёөмқҳ нҢҢлқјлҜён„°лҘј мһ¬н•ҷмҠөмӢңнӮӨлҠ” кІғмқ„ мқҳлҜён•ҳкі , лҜём„ёмЎ°м •мқҖ мҷ„м „м—°кІ°мёөкіј лҚ”л¶Ҳм–ҙ м»ЁліјлЈЁм…ҳмёөмқҳ л§Ҳм§Җл§ү лӘҮ к°ңмёө нҢҢлқјлҜён„°лҘј мһ¬н•ҷмҠөмӢңнӮӨлҠ” кІғмқ„ мқҳлҜён•ңлӢӨ. м—¬лҹ¬ к°ңмқҳ м»ЁліјлЈЁм…ҳмёө мӨ‘ м»ЁліјлЈЁм…ҳмқ„ мІҳмқҢ мҲҳн–үн•ҳлҠ” мёөмқҖ мқҙлҜём§Җмқҳ к°ҖлЎң лӘЁм„ңлҰ¬, м„ёлЎң лӘЁм„ңлҰ¬ л“ұмқҳ мқјл°ҳм Ғмқё нҠ№м„ұмқ„ 추м¶ңн•ҳкі л§Ҳм§Җл§ү мёөмңјлЎң к°ҲмҲҳлЎқ мқҙлҜём§Җм—җ нҠ№нҷ”лҗң нҠ№м„ұмқ„ 추м¶ңн•ңлӢӨ[14]. л”°лқјм„ң лҜём„ёмЎ°м •мқ„ н•ЁмңјлЎңмҚЁ мһ мҲҳн•Ё л§ҲмҠӨнҠём—җ нҠ№нҷ”лҗң нҠ№м„ұмқ„ 추м¶ңн•ҳм—¬ мҷ„м „м—°кІ°мёөл§Ң мһ¬н•ҷмҠөн•ҳлҠ” нҠ№м„ұ추м¶ң лҢҖ비 лӘЁлҚё м„ұлҠҘмқҙ н–ҘмғҒлҗҳлҠ”м§Җ нҷ•мқён•ҳмҳҖлӢӨ. 3лӢЁкі„лҠ” м•ҷмғҒлё” лӘЁлҚёмқ„ мӮ¬мҡ©н•ҳмҳҖлӢӨ. лӢЁмқј CNN лӘЁлҚёмқҙ мқҙлҜём§Җ лӮҙм—җм„ң лӘЁл“ нҠ№м„ұл“Өмқ„ 추м¶ңн•ҙ лӮҙм§Җ лӘ»н•ҳлҠ” кІҪмҡ° лӢӨмҲҳмқҳ лӘЁлҚёмқ„ кІ°н•©н•ҳлҠ” м•ҷмғҒлё”мқҖ лӣ°м–ҙлӮң н•ҳлӮҳмқҳ лӘЁлҚёліҙлӢӨ мҡ°мҲҳн•ң м„ұлҠҘмқ„ л°ңнңҳн• мҲҳ мһҲлӢӨ[12]. ліё м—°кө¬лҠ” л§ҲмҠӨнҠёлҘј мҳ¬лҰ¬кі н•ӯн•ҙн•ҳлҠ” мһ мҲҳн•Ёмқҳ нғҗм§ҖмңЁмқ„ к·№лҢҖнҷ”н•ҳкё° мң„н•ҳм—¬ 2лӢЁкі„м—җм„ң мӮ¬мҡ©н•ң мҡ°мҲҳн•ң лӘЁлҚёл“Өмқ„ кІ°н•©н•ң м•ҷмғҒлё” лӘЁлҚёмқ„ мӮ¬мҡ©н•ЁмңјлЎңмҚЁ мқҙлҜём§Җ 분лҘҳ лӘЁлҚёмқҳ м„ұлҠҘмқҙ н–ҘмғҒлҗҳлҠ”м§ҖлҘј нҷ•мқён•ҳмҳҖлӢӨ.
ліё м—°кө¬лҠ” GPU нҷңмҡ©мқ„ мң„н•ҙ л§Һмқҙ мқҙмҡ©лҗҳлҠ” Google colaboratoryлҘј мӮ¬мҡ©н•ҳмҳҖмңјл©°, к·ём—җ л”°лқј Ubuntu 18.04.3 LTS, GPU Persistence-M CUDA Version 10.1, Python 3.6.9, Tensorflow 1.15.0, Keras 2.2.5 мӢӨн—ҳнҷҳкІҪм—җм„ң мҲҳн–үн•ҳмҳҖлӢӨ.
мһ мҲҳн•Ё 분лҘҳ лӘЁлҚё кө¬м¶• л°Ҹ мӢӨн—ҳ
м ңмӢңн•ң лӘЁлҚём—җ л”°лҘё лҚ°мқҙн„° мҲҳ집 л°Ҹ мӢӨн—ҳ кІ°кіјлҠ” лӢӨмқҢкіј к°ҷлӢӨ.
4.1 лҚ°мқҙн„° мҲҳ집
лҚ°мқҙн„°лҠ” м—°кө¬ лӘ©н‘ңм—җ л¶Җн•©н•ҳкё° мң„н•ҳм—¬ Fig. 4мҷҖ к°ҷмқҙ л§ҲмҠӨнҠёлҘј мҳ¬лҰ¬кі н•ӯн•ҙн•ҳлҠ” мһ мҲҳн•Ё, л¶ҖмғҒн•ң мһ мҲҳн•Ё, к№ғлҢҖл¶Җмқҙ, л“ұл¶Җн‘ң, мҶҢнҳ• м–ҙм„ В·ліҙнҠёмқҳ лҚ°мқҙн„°лҘј кө¬кёҖ л°Ҹ л„ӨмқҙлІ„ мқҙлҜём§ҖлҘј кІҖмғүн•ҳм—¬ мҙқ 2,395мһҘмқ„ мҲҳ집н•ҳмҳҖлӢӨ. лҚ°мқҙн„°лҠ” мҲҳмғҒн•Ёмқҳ TVм№ҙл©”лқјк°Җ л°°мңЁнҷ•лҢҖкё°лҠҘмқ„ к°Җм§ҖлҠ” кІғмқ„ кі л Өн•ҳм—¬ н‘ңм Ғ нҒ¬кё°к°Җ нҒ° кІғл¶Җн„° мһ‘мқҖ кІғк№Ңм§Җ лӢӨм–‘н•ҳкІҢ мҲҳ집н•ҳмҳҖлӢӨ. л¶ҖмғҒн•ң мһ мҲҳн•Ёмқҳ кІҪмҡ° н‘ңм Ғмқҙ мқҙлҜём§Җмқҳ м Ҳл°ҳ м •лҸ„ 비мңЁмқ„ м°Ём§Җн•ҳмҳҖмңјлӮҳ, мөңлҢҖн•ң мӣҗкұ°лҰ¬м—җм„ңл¶Җн„° н‘ңм Ғмқ„ 분лҘҳн•ҳлҠ” кё°лҠҘмқ„ кө¬нҳ„н•ҳкё° мң„н•ҙ мӨ‘м җм ҒмңјлЎң нҸ¬н•ЁмӢңнӮЁ Fig. 5мҷҖ к°ҷмқҖ мһ‘мқҖ н‘ңм Ғмқҳ лҚ°мқҙн„°лҠ” н‘ңм Ғмқҙ мқҙлҜём§Җмқҳ мҲҳмІң분мқҳ мқј нҒ¬кё°мҲҳмӨҖмқҙм—ҲлӢӨ.


мҲҳ집н•ң лҚ°мқҙн„°лҠ” кІҖмҰқмқ„ мң„н•ҙ мқјл°ҳм ҒмңјлЎң 7:3, 8:2, 9:1мқҳ 비мңЁлЎң нӣҲл ЁлҚ°мқҙн„°(Training data), кІҖмҰқлҚ°мқҙн„°(Validation data)лЎң лӮҳлҲҢ мҲҳ мһҲлҠ”лҚ° ліё м—°кө¬м—җм„ңлҠ” нӣҲл ЁлҚ°мқҙн„°мқҳ мҲҳлҹү нҷ•ліҙлҘј мң„н•ҙ 9:1мқҳ 비мңЁлЎң лӮҳлҲ„м—Ҳкі , нҸүк°ҖлҚ°мқҙн„°(Test data)лҠ” н…ҢмҠӨнҠё м •нҷ•лҸ„мқҳ м •нҷ•м„ұмқ„ мң„н•ҳм—¬ Table 1кіј к°ҷмқҙ 4к°ң нҒҙлһҳмҠӨк°Җ лҸҷмқјн•ң 50к°ңмқҳ лҚ°мқҙн„°лҘј к°Җм§ҖлҸ„лЎқ лі„лҸ„лЎң кө¬м„ұн•ҳмҳҖлӢӨ. мһ мҲҳн•Ёмқҳ н…ҢмҠӨнҠё мқҙлҜём§Җ 50мһҘмқҖ л§ҲмҠӨнҠё 1к°ң 22мһҘ, л§ҲмҠӨнҠё 2к°ң мқҙмғҒ 12мһҘ, н•Ёкөҗнғ‘к№Ңм§Җ нҸ¬н•Ён•ң мӮ¬м§„ 13мһҘмңјлЎң кө¬м„ұн•ҳмҳҖмңјл©°, н‘ңм Ғмқҳ нҒ¬кё° лҳҗн•ң лӢӨм–‘н•ҳкІҢ кө¬м„ұн•ҳмҳҖлӢӨ.
TableВ 1.
Data set information
л”Ҙлҹ¬лӢқм—җм„ң нӣҲл ЁлҚ°мқҙн„°м—җ лҢҖн•ҙм„ңлҠ” мҳҲмёЎмқ„ мһҳ н•ҳм§Җл§Ң мғҲлЎңмҡҙ лҚ°мқҙн„°м—җ лҢҖн•ң мҳҲмёЎ м •нҷ•лҸ„к°Җ л–Ём–ҙм§ҖлҠ” кіјлҢҖм Ғн•©(Overfitting)мқҙ л°ңмғқн• мҲҳ мһҲлҠ”лҚ°, мқҙлҘј л°©м§Җн•ҳкё° мң„н•ң мң мҡ©н•ң л°©лІ• мӨ‘ н•ң к°Җм§ҖлҠ” н•ҳлӮҳмқҳ лҚ°мқҙн„°лҘј нҡҢм „, мқҙлҸҷ л“ұмқҳ л°©лІ•мңјлЎң лҚ°мқҙн„° нҷ•мһҘ(Data augmentation)н•ҳлҠ” кІғмқҙлӢӨ. ліё м—°кө¬м—җм„ңлҠ” нӣҲл ЁлҚ°мқҙн„° 1,973мһҘм—җ лҢҖн•ҙ нҡҢм „(Rotation), мўҢмҡ°мқҙлҸҷ(Width_shift), мғҒн•ҳмқҙ лҸҷ(Height _shift), мўҢмҡ°л°ҳм „(Horizontal_flip), мғҒн•ҳл°ҳм „(Vertical_flip)мқҳ лҚ°мқҙн„° нҷ•мһҘмқ„ мӢӨмӢңн•ҳмҳҖлӢӨ.
4.2 мқҙлҜём§Җ 분лҘҳ лӘЁлҚё н•ҷмҠө л°Ҹ нҸүк°Җ
4.2.1 нҠ№м„ұ추м¶ң(Feature extraction)
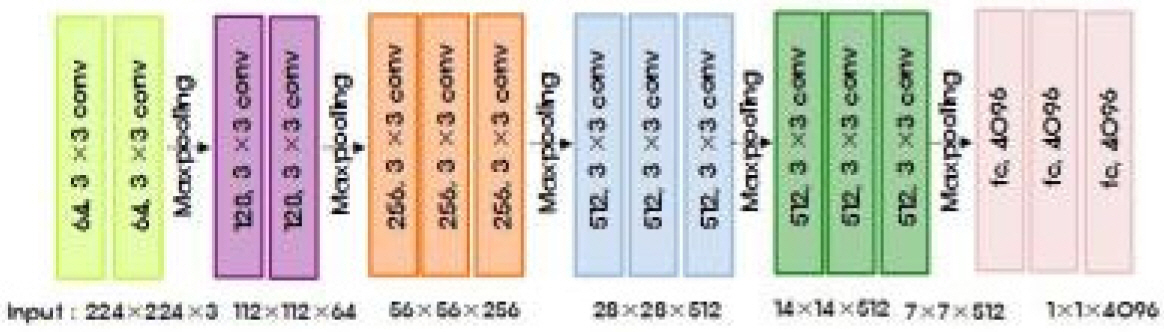
нҠ№м„ұ추м¶ңлӢЁкі„м—җм„ң мӮ¬мҡ©н•ң лӘЁлҚёмқҖ VGG16, VGG19, ResNet50, ResNet101мқҙлӢӨ. VGG16[15]мқҖ 2014л…„ ILSVRC м—җм„ң мӨҖмҡ°мҠ№н•ң лӘЁлҚёлЎң Fig. 6кіј к°ҷмқҙ 5к°ңмқҳ н’Җл§Ғмёөмқ„ нҸ¬н•Ён•ң 13к°ңмқҳ м»ЁліјлЈЁм…ҳмёөкіј 3к°ңмқҳ мҷ„м „м—°кІ°мёөмңјлЎң кө¬м„ұлҗҳм–ҙ мһҲмңјл©°, 3Г—3мқҳ к· мқјн•ң нҒ¬кё°лҘј к°Җ진 н•„н„°мҷҖ нҢЁл”©(Padding)мқ„ мқҙмҡ©н•ҙ мқҙлҜём§Җмқҳ нҒ¬кё°к°Җ мң м§Җлҗ мҲҳ мһҲлҸ„лЎқ м»ЁліјлЈЁм…ҳмқ„ мҲҳн–үн•ңлӢӨ. мқҙм „ CNN лӘЁлҚём—җ 비н•ҙ мһ‘мқҖ н•„н„°лҘј к№ҠмқҖ л„ӨнҠёмӣҢнҒ¬м—җм„ң л°ҳліөм ҒмңјлЎң мӮ¬мҡ©н•ҳм—¬ нҡЁкіјлҠ” лҸҷмқјн•ҳкІҢ н•ҳлҗҳ нҢҢлқјлҜён„° мҲҳлҘј м ҒкІҢ мӮ¬мҡ©н•ҳмҳҖлӢӨлҠ” нҠ№м§•мқҙ мһҲлӢӨ. VGG19лҠ” VGG16мқҳ м»ЁліјлЈЁм…ҳмёөмқ„ 16к°ңлЎң кө¬м„ұн•ң лӘЁлҚёмқҙлӢӨ.
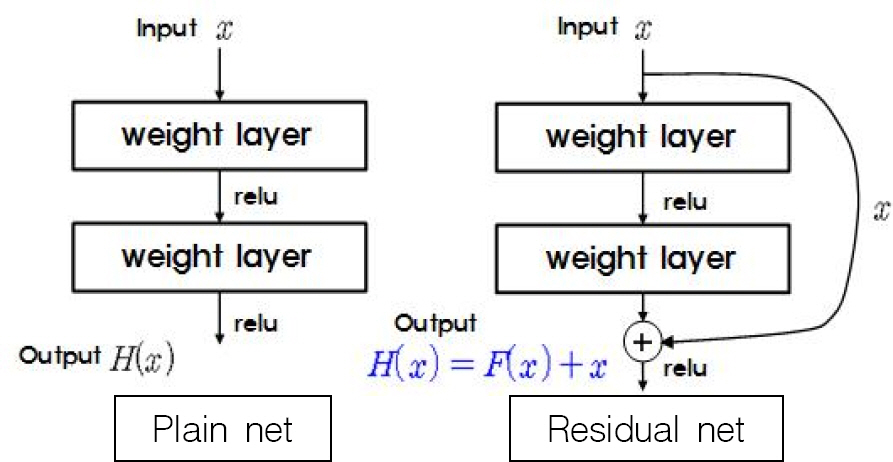
ResNet[16]мқҖ 2015л…„ ILSVRCм—җм„ң мҡ°мҠ№н•ң лӘЁлҚёлЎң кё°мЎҙмқҳ CNN 분야м—җ мһҲм—ҲлҚҳ н•ҷмҠөмёөмқҙ кіјлӢӨн•ҳкІҢ к№Ҡм–ҙм§Җл©ҙ нӣҲл Ё м •нҷ•лҸ„к°Җ л–Ём–ҙм§ҖлҠ” л¬ём ңлҘј Residual netмқ„ мӮ¬мҡ©н•ҳм—¬ н•ҙкІ°н–ҲлӢӨ. Fig. 7мқҖ Plain netкіј Residual netмқҳ м°ЁмқҙлҘј ліҙм—¬мЈјлҠ”лҚ° Plain netм—җм„ңлҠ” м¶ңл Ҙмқ„ H(x)лЎңл§Ң н‘ңнҳ„н•ҳкі мһҲм§Җл§Ң, Residual netм—җм„ңлҠ” мһ…л Ҙмқё xлҘј лӢӨмӢң м¶ңл Ҙмёөм—җ м ңкіөн•ҙ мӨҢмңјлЎңмҚЁ м¶ңл Ҙмқ„ H(x) = F(x) + xлЎң н‘ңнҳ„н•ҳкі мһҲлӢӨ. мҰү, мһ…л Ҙ xлҘј м ңкіөл°ӣкё° л•Ңл¬ём—җ мһ…В·м¶ңл Ҙ к°„мқҳ мҳӨм°Ё F(x)л§Ң 추к°ҖлЎң н•ҷмҠөн•ҳл©ҙ м¶ңл Ҙмқё H(x)лҘј м–»кІҢ лҗҳлҠ” кІғмқҙлӢӨ. мқҙлЎң мқён•ҙ H(x)м „мІҙлҘј н•ҷмҠөн•ҳлҠ” мқҙм „ CNN лӘЁлҚёл“Өм—җ 비н•ҙ н•ҷмҠөмёө к№ҠмқҙлҘј к№ҠкІҢ н• мҲҳ мһҲм—Ҳкі , к·ё мёөмқҳ мҲҳм—җ л”°лқј ліё м—°кө¬м—җм„ң мӮ¬мҡ©н•ң ResNet50, ResNet101 мҷём—җлҸ„ ResNet18, ResNet34, ResNet152 л“ұмқҙ мһҲлӢӨ.
к°Ғ лӘЁлҚёмқҳ н•ҳмқҙнҚјнҢҢлқјлҜён„°лҠ” Table 2мҷҖ к°ҷмқҙ л°°м№ҳ32, н•ҷмҠөм„ёлҢҖ 100, мҷ„м „м—°кІ°мёө 1к°ңмёө, л“ңлһҚм•„мӣғ(Drop out) 비мңЁ 50 %лЎң н•ҷмҠөн•ҳмҳҖмңјл©°, н•ҷмҠөлҘ мқ„ 10вҲ’4, 10вҲ’5, 10вҲ’6 л“ұмңјлЎң ліҖнҷ”мӢңнӮӨкі мөңмў… мҷ„м „м—°кІ°мёөмқҳ мң лӢӣмқ„ 512, 1024, 2048 л“ұмңјлЎң м§Җм •н•ҳл©ҙм„ң мӢӨн—ҳн•ҳмҳҖлӢӨ. мӢӨн—ҳ кІ°кіј мҡ°мҲҳн•ң н…ҢмҠӨнҠё м •нҷ•лҸ„лҘј м–»мқ„ мҲҳ мһҲм—ҲлҚҳ н•ҳмқҙнҚјнҢҢлқјлҜён„° к°’кіј к·ёл•Ң н•ҷмҠө кІ°кіјлЎң мғқм„ұлҗң нҢҢлқјлҜён„° к°’мқҖ 2лӢЁкі„ лӘЁлҚём—җм„ң лӢӨмӢң мӮ¬мҡ©н•ҳмҳҖлӢӨ. мқҙл•Ң кІҖмҰқмҶҗмӢӨ(Validation loss)мқҙ нӣҲл ЁмҶҗмӢӨ(Train loss)м—җ 비н•ҙ лҚ” мқҙмғҒ л–Ём–ҙм§Җм§Җ м•Ҡмқ„ л•ҢлҠ” кіјлҢҖм Ғн•©мқҙ л°ңмғқн•ң кІғмңјлЎң нҢҗлӢЁн•ҳм—¬ л“ңлһҚм•„мӣғ мёөмқ„ 2к°ң мёөмңјлЎң 추к°Җн•ҳкі , к°ҖмӨ‘м№ҳ к·ңм ң(Weight regularization) L1кіј L2лҘј м Ғмҡ©н•ҳмҳҖлӢӨ. L1мқҖ мҶҗмӢӨн•ЁмҲҳ к°’мқ„ м •мқҳн• л•Ң м—җлҹ¬ к°’м—җ к°ҖмӨ‘м№ҳ м ҲлҢҖк°’м—җ 비лЎҖн•ҳлҠ” к°’мқ„ 추к°Җн•ҳлҠ” кІғмқҙкі , L2лҠ” к°ҖмӨ‘м№ҳ м ңкіұм—җ 비лЎҖн•ҳлҠ” к°’мқ„ 추к°Җн•ҳлҠ” кІғмқёлҚ°, к°ҖмӨ‘м№ҳ к·ңм ңмқҳ м Ғмҡ©мқҖ лӘЁлҚёмқҳ кі м°Ён•ӯмқ„ лӮҳнғҖлӮҙлҠ” нҠ№м„ұмқ„ 0м—җ к°Җк№қкІҢ л§Ңл“Өм–ҙмӨҢмңјлЎңмҚЁ лӘЁлҚёмқ„ лӢЁмҲңнҷ”мӢңмјң кіјлҢҖм Ғн•©мқ„ мөңмҶҢнҷ”мӢңнӮЁлӢӨ[17]. мқҙл•ҢлҠ” мҶҗмӢӨн•ЁмҲҳ мөңмҙҲк°’мқҙ м»Өм§Җкё° л•Ңл¬ём—җ нӣҲл ЁмҶҗмӢӨмқҙ н•ҷмҠөм„ёлҢҖлҘј кұ°л“ӯн•ҳл©ҙм„ң 충분нһҲ мӨ„м–ҙ л“Ө мҲҳ мһҲлҸ„лЎқ н•ҷмҠөм„ёлҢҖлҘј 200мңјлЎң м Ғмҡ©н•ҳмҳҖлӢӨ. мӢӨн—ҳмқҖ н•ҳмқҙнҚјнҢҢлқјлҜён„°лҘј ліҖкІҪн•ҳл©ҙм„ң VGG16 6к°Җм§Җ, VGG19 9к°Җм§Җ, ResNet101 6к°Җм§Җ, ResNet50 10к°Җм§Җ мҙқ 31к°Җм§Җмқҳ кІҪмҡ°м—җ лҢҖн•ҙ мӢӨмӢңн•ҳмҳҖкі , лӘЁлҚёлі„лЎң м–»мқҖ к°ҖмһҘ лҶ’мқҖ н…ҢмҠӨнҠё м •нҷ•лҸ„лҠ” Table 2мҷҖ к°ҷмқҙ к°Ғк°Ғ VGG16 86.5 %, VGG19 84.5 %, ResNet101 79.5 %, ResNet50 79.0 % мҳҖлӢӨ.
TableВ 2.
Best results for each model in feature extraction
4.2.2 лҜём„ёмЎ°м •(Fine tuning)
лҜём„ёмЎ°м •лӢЁкі„м—җм„ңлҠ” 1лӢЁкі„м—җм„ң мҷ„м „м—°кІ°мёөмқ„ н•ҷмҠөмӢңмјң мҡ°мҲҳн•ң н…ҢмҠӨнҠё м •нҷ•лҸ„лҘј лӮҳнғҖлӮё лӘЁлҚёл“Өмқ„ м„ нғқн•ҳм—¬ м»ЁліјлЈЁм…ҳмёөмқҳ л§Ҳм§Җл§ү 2вҲј3к°ңмёөмқ„ мһ¬н•ҷмҠөнҶ лЎқ м„Өм •н•ҳкі , н•ҷмҠөлҘ мқ„ 10вҲ’4, 10вҲ’5, 10вҲ’6 л“ұмңјлЎң ліҖнҷ”мӢңнӮӨл©ҙм„ң н•ҷмҠөм„ёлҢҖ 100к№Ңм§Җ н•ҷмҠөмӢңмјң м„ұлҠҘмқҙ н–ҘмғҒлҗҳлҠ”м§Җ нҷ•мқён•ҳмҳҖлӢӨ. мқҙмІҳлҹј мҷ„м „м—°кІ°мёөмқ„ лЁјм Җ н•ҷмҠө нӣ„ м»ЁліјлЈЁм…ҳмёөмқ„ н•ҷмҠөмӢңнӮҙмңјлЎңмҚЁ 비көҗм Ғ мһ‘мқҖ лҚ°мқҙн„°м„ёнҠёлЎңлҸ„ нҒ° мҳӨм°Ёмқҳ м „нҢҢм—Ҷмқҙ м»ЁліјлЈЁм…ҳмёөмқ„ н•ҷмҠөмӢңнӮ¬ мҲҳ мһҲлӢӨ[14]. лҜём„ёмЎ°м • нӣ„ н…ҢмҠӨнҠё м •нҷ•лҸ„лҠ” VGG16мқҖ 3к°ңмқҳ м»ЁліјлЈЁм…ҳмёөмқ„ н•ҷмҠөлҘ 10вҲ’4лЎң н•ҷмҠөн•ҳмҳҖмқ„ л•Ң 89.5 %, VGG19 м—ӯмӢң 3к°ңмқҳ м»ЁліјлЈЁм…ҳмёөмқ„ н•ҷмҠөлҘ 10вҲ’5лЎң н•ҷмҠөн•ҳмҳҖмқ„ л•Ң 89.0 %лҘј лӢ¬м„ұн•ҳмҳҖмңјл©°, ResNet101мқҖ 2к°ңмқҳ м»ЁліјлЈЁм…ҳмёөмқ„ н•ҷмҠөлҘ 10вҲ’6мңјлЎң н•ҷмҠөн•ҳмҳҖмқ„ л•Ң 86.0 %, ResNet50 м—ӯмӢң лҸҷмқј мЎ°кұҙм—җм„ң 81.0 %лЎң лӘЁлҚёлі„лЎң 2.0вҲј6.5 %к°Җ н–ҘмғҒлҗҳм—ҲлӢӨ. лӘЁлҚёлі„ нҠ№м„ұ추м¶ңлӢЁкі„мҷҖ лҜём„ёмЎ°м •лӢЁкі„м—җм„ңмқҳ н…ҢмҠӨнҠё м •нҷ•лҸ„мқҳ м°ЁмқҙлҠ” Table 3м—җм„ң нҷ•мқён• мҲҳ мһҲлӢӨ.
4.2.3 м•ҷмғҒлё”(Ensemble)
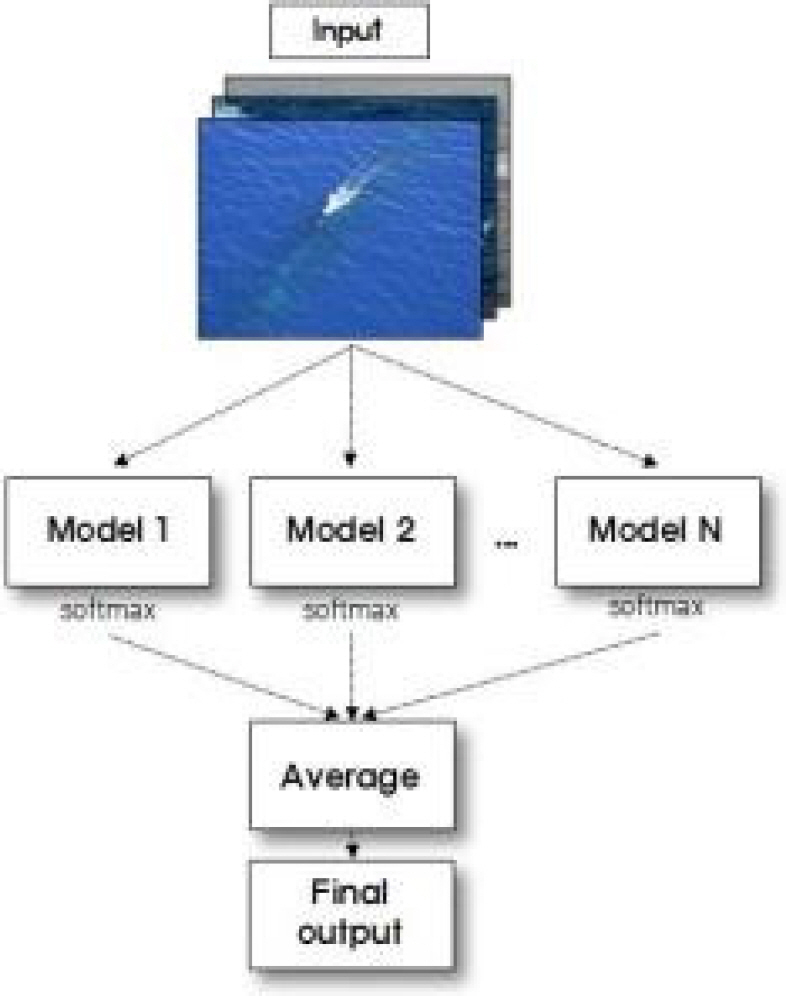
м•ҷмғҒлё”лӢЁкі„лҠ” м—¬лҹ¬ к°ңмқҳ лӢӨлҘё лӘЁлҚёмқҳ мҳҲмёЎк°’мқ„ кІ°н•©н•ҳм—¬ лҚ” мўӢмқҖ м„ұлҠҘмқ„ м–»лҠ” кІғмқ„ лӘ©н‘ңлЎң н•ңлӢӨ. ліё м—°кө¬м—җм„ңлҠ” лҜём„ёмЎ°м •лӢЁкі„м—җм„ң мҡ°мҲҳн•ң кІ°кіјлҘј к°Җ진 лӘЁлҚёл“Өмқ„ лі‘л ¬лЎң кө¬м„ұн•ҳмҳҖкі , мқҙлҘј нҶөн•ҙ м—¬лҹ¬ к°ңмқҳ м„ңлЎң лӢӨлҘё лӘЁлҚёл“Өмқҳ мҳҲмёЎмқ„ кұ°м№ң к°’мқ„ Fig. 8кіј к°ҷмқҙ нҸүк· н•ҳм—¬ мөңмў… нҸүк°Җн•ңлӢӨ.
мқҙ мӢӨн—ҳмқҖ Table 4мҷҖ к°ҷмқҙ VGG16, VGG19, ResNet50, ResNet101мқҳ 4к°ңмқҳ лӘЁлҚёмқ„ мЎ°н•©н• мҲҳ мһҲлҠ” мҙқ 13к°Җм§Җм—җ лҢҖн•ҳм—¬ мҲҳн–үн•ҳмҳҖкі , к·ё кІ°кіјлЎң VGG16, VGG19, ResNet101мқҳ 3к°ң лӘЁлҚёмқ„ мЎ°н•©н•ң кІҪмҡ°мҷҖ 4к°ңмқҳ лӘЁлҚё лӘЁл‘җлҘј мЎ°н•©н•ң кІҪмҡ°м—җм„ңмқҳ н…ҢмҠӨнҠё м •нҷ•лҸ„к°Җ 91.5 %лЎң к°ҖмһҘ лҶ’м•ҳмңјл©°, лӘЁлҚёмқҳ ліөмһЎлҸ„лҘј кі л Өн•ҳм—¬ 3к°ңмқҳ лӘЁлҚёмқ„ мЎ°н•©н•ң кІҪмҡ°лҘј мөңм Ғмқҳ лӘЁлҚёлЎң нҸүк°Җн•ҳмҳҖлӢӨ. 2к°ңмқҳ лӘЁлҚёмқ„ мЎ°н•©н•ҳмҳҖмқ„ кІҪмҡ°м—җлҠ” лӢЁмқј лӘЁлҚёмқҳ н…ҢмҠӨнҠё м •нҷ•лҸ„ліҙлӢӨ мҡ°мҲҳн•ң м •нҷ•лҸ„лҘј лӢ¬м„ұн•ҳм§Җ лӘ»н•ҳмҳҖлӢӨ. к·ёлҹ¬лӮҳ 3к°ңмқҳ лӘЁлҚёмқ„ мЎ°н•©н•ҳмҳҖмқ„ кІҪмҡ°м—җлҠ” VGG16, VGG19 лҢҖ비 м„ұлҠҘмқҙ лӮ®мқҖ ResNetмқ„ мЎ°н•©н•ҳмҳҖмқҢм—җлҸ„ ResNet50 90.5 % ResNet101 91.5 %лЎң м„ұлҠҘмқҙ н–ҘмғҒлҗЁмқ„ нҷ•мқён•ҳмҳҖлӢӨ. мқҙлҠ” ResNetмқҙ VGG16кіј VGG19к°Җ 추м¶ңн•ҙ лӮҙм§Җ лӘ»н•ҳлҠ” нҠ№м„ұмқ„ 추м¶ңн•ҙ лӮҙкё° л•Ңл¬ёмқё кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ. 4к°ңмқҳ лӘЁлҚё лӘЁл‘җлҘј мЎ°н•©н•ҳмҳҖмқ„ л•Ң м„ұлҠҘмқҙ н–ҘмғҒлҗҳм§Җ м•ҠмқҖ мқҙмң лҠ” лӮҳлЁём§Җ 3к°ңмқҳ лӘЁлҚём—җ 비н•ҳм—¬ ResNet50м—җм„ңмқҳ н…ҢмҠӨнҠё м •нҷ•лҸ„к°Җ 81.0 %лЎң лӢӨмҶҢ лӮ®кі , м„ұлҠҘмқҙ лӮ®мқҖ лӘЁлҚёмқҙлқј н•ҳлҚ”лқјлҸ„ лӢӨм–‘н•ң лӘЁлҚёмқ„ м•ҷмғҒлё” н• кІҪмҡ° м„ұлҠҘмқҙ н–ҘмғҒлҗҳлҠ” кІҪмҡ°к°Җ мһҲм§Җл§Ң, мқҙлҜё ResNe50кіј мң мӮ¬н•ң кө¬мЎ°мқё ResNet101мқҙ нҸ¬н•Ёлҗҳм–ҙ мһҲкё° л•Ңл¬ём—җ ResNet50мқҙ кө¬мЎ°мқҳ лӢӨм–‘м„ұ мёЎл©ҙм—җм„ң кё°м—¬н•ҳм§Җ лӘ»н•ң кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ.
TableВ 4.
Results for various model's ensemble
мөңм Ғмқҳ лӘЁлҚём—җм„ң нҒҙлһҳмҠӨлі„ н…ҢмҠӨнҠё м •нҷ•лҸ„лҠ” мһ мҲҳн•Ёмқҙ 91.2 %мҳҖмңјл©°, к№ғлҢҖл¶Җмқҙ 77.2 %, л“ұл¶Җн‘ң 98.2 %, мҶҢнҳ• м–ҙм„ В·ліҙнҠё 100 %мҳҖлӢӨ. мһ мҲҳн•Ёмқҙ лӢӨлҘё н‘ңм ҒмңјлЎң мҳӨ분лҘҳлҗң мқҙлҜём§ҖлҠ” Fig. 9мҷҖ к°ҷкі , мҳӨ분лҘҳлҗң мқҙлҜём§ҖмҷҖ м •мғҒ분лҘҳлҗң мқҙлҜём§Җк°„мқҳ лҡңл ·н•ң нҠ№м„ұ м°ЁмқҙлҠ” м°ҫмқ„ мҲҳ м—Ҷм—ҲлӢӨ. к№ғлҢҖл¶Җмқҙк°Җ лӢӨлҘё нҒҙлһҳмҠӨм—җ 비н•ҙ м •нҷ•лҸ„к°Җ лӮ®мқҖ мқҙмң лҳҗн•ң лӢӨлҘё нҒҙлһҳмҠӨм—җ 비н•ҙм„ңлҸ„ нҳ„м Җн•ҳкІҢ л¶ҖмЎұн•ң лҚ°мқҙн„° л•Ңл¬ёмқё кІғмңјлЎң нҢҗлӢЁлҗңлӢӨ. мқҙлҠ” ліҙлӢӨ л§ҺмқҖ лҚ°мқҙн„° нҷ•ліҙлҘј нҶөн•ҙ к°ңм„ лҗ мҲҳ мһҲмқ„ кІғмқҙлқј нҢҗлӢЁлҗңлӢӨ.

кІ° лЎ
ліё м—°кө¬м—җм„ңлҠ” н•ңл°ҳлҸ„м—җм„ң нҷңлҸҷн•ҳкі мһҲлҠ” л¶Ғн•ң л°Ҹ мЈјліҖкөӯ мһ мҲҳн•Ём—җ лҢҖн•ң 비мқҢн–Ҙ нғҗм§ҖмңЁмқ„ н–ҘмғҒмӢңнӮӨкё° мң„н•ҙ CNN лӘЁлҚёмқ„ нҷңмҡ©н•ҳм—¬ мһ мҲҳн•Ё л§ҲмҠӨнҠёмҷҖ мҲҳмғҒн•Ём—җм„ң н•ӯн•ҙ мӨ‘ мң мӮ¬н•ң н‘ңм ҒмңјлЎң мӢқлі„лҗ мҲҳ мһҲлҠ” к№ғлҢҖл¶Җмқҙ, л“ұл¶Җн‘ң, мҶҢнҳ• м–ҙм„ В·ліҙнҠём—җ лҢҖн•ң 분лҘҳлҘј 진н–үн•ҳмҳҖлӢӨ. мқҙл•Ң мөңлҢҖн•ң мӣҗкұ°лҰ¬м—җм„ңл¶Җн„° н‘ңм Ғмқ„ 분лҘҳн•ҳлҠ” кё°лҠҘмқ„ кө¬нҳ„н•ҳкё° мң„н•ҙ мһ‘мқҖ н‘ңм Ғмқ„ нҸ¬н•Ён•ҳм—¬ н•ҷмҠөн•ҳмҳҖкі , лӘЁлҚёмқҳ м„ұлҠҘмқ„ к·№лҢҖнҷ”н•ҳкё° мң„н•ҙ нҠ№м„ұ추м¶ң, лҜём„ёмЎ°м •, м•ҷмғҒлё”мқ„ лӢЁкі„м ҒмңјлЎң 진н–үн•ҳл©ҙм„ң лӢӨм–‘н•ң н•ҳмқҙнҚјнҢҢлқјлҜён„°мҷҖ м—¬лҹ¬ кІҪмҡ°мқҳ м•ҷмғҒлё” лӘЁлҚёмқ„ мӢӨн—ҳн•ҳмҳҖлӢӨ. кІ°кіјм ҒмңјлЎң VGG16, VGG19, ResNet50, ResNet101 4к°Җм§Җ лӘЁлҚё м „л¶ҖлҘј м•ҷмғҒлё” н•ҳмҳҖмқ„ л•ҢмҷҖ VGG16, VGG19, ResNet101 лӘЁлҚёмқ„ м•ҷмғҒлё” н•ҳмҳҖмқ„ л•Ң 91.5 %мқҳ м •нҷ•лҸ„лҘј лӢ¬м„ұн•ҳмҳҖлӢӨ. мқҙлҠ” лӢЁмқјлӘЁлҚём—җм„ң мҷ„м „м—°кІ°мёөл§Ң мһ¬н•ҷмҠөн•ң лӘЁлҚёмқҳ мөңкі н…ҢмҠӨнҠё м •нҷ•лҸ„мқё 86.5 % лҢҖ비 5.0 % н–ҘмғҒлҗң к°’мқҙл©°, м»ЁліјлЈЁм…ҳмёөмқҳ мқјл¶Җк№Ңм§Җ лҜём„ёмЎ°м •н•ң лӘЁлҚёмқҳ мөңкі н…ҢмҠӨнҠё м •нҷ•лҸ„мқё 89.5 % лҢҖ비 2.0 % н–ҘмғҒ лҗң к°’мқҙлӢӨ. м•ҷмғҒлё” мӢӨн—ҳмқ„ нҶөн•ҙ м„ұлҠҘмқҙ лӮ®мқҖ лӘЁлҚёмқҙлқј н•ҳлҚ”лқјлҸ„ м„ұлҠҘмқҙ мҡ°мҲҳн•ң лӘЁлҚёкіј лі‘н•©н•ЁмңјлЎңмҚЁ лӘЁлҚё м „мІҙмқҳ м„ұлҠҘмқ„ н–ҘмғҒмӢңнӮ¬ мҲҳ мһҲмқҢмқ„ нҷ•мқён•ҳмҳҖлӢӨ. лҳҗн•ң мқҙкІғмқҖ лӘЁлҚёмқҳ кө¬мЎ°к°Җ кё°мЎҙ лӘЁлҚёкіј лӢӨлҘј л•Ң нҡЁкіјк°Җ нҷ•мӢӨн•Ёмқ„ м•Ң мҲҳ мһҲм—ҲлӢӨ.
ліё м—°кө¬мқҳ м ңн•ңмӮ¬н•ӯмқҖ ліҙлӢӨ лӢӨм–‘н•ң CNN лӘЁлҚёмқ„ мӮ¬мҡ©н•ҳм§Җ лӘ»н•ҳмҳҖлӢӨлҠ” м җмқҙлӢӨ. ліё м—°кө¬м—җм„ң мӮ¬мҡ©н•ң лӘЁлҚё мҷём—җлҸ„ Inception_V3, DenseNet л“ұ нҷңмҡ©н• мҲҳ мһҲлҠ” лӘЁлҚёмқҙ лӢӨм–‘н•ҳм§Җл§Ң к·ёлҹ¬н•ң лӘЁлҚёл“Өмқ„ лӢӨм–‘н•ң н•ҳмқҙнҚјнҢҢлқјлҜён„°лЎң н•ҷмҠөмқ„ мӢңлҸ„н•ҳмҳҖмқҢм—җлҸ„ 1н•ҷмҠөм„ёлҢҖм—җм„ңл¶Җн„° кІҖмҰқ м •нҷ•лҸ„к°Җ нҒ¬кІҢ м Җн•ҳлҗҳкі н…ҢмҠӨнҠё м •нҷ•лҸ„ лҳҗн•ң лӮ®мқҖ л¬ём ңлҘј ліҙмҳҖкі , к°ҖмӨ‘м№ҳ к·ңм ң, л“ңлһҚм•„мӣғ мёө мҲҳ мЎ°м Ҳ л“ұмқҳ мЎ°м№ҳм—җлҸ„ к°ңм„ лҗҳм§Җ м•Ҡм•ҳлӢӨ. мқҙлҠ” н•ҷмҠөн•ҙм•ј н• лҚ°мқҙн„°лҠ” лӢЁмҲңн•ңлҚ° 비н•ҙ лӘЁлҚёмқҙ ліөмһЎн•ҳм—¬ кіјлҢҖм Ғн•©мқҙ л°ңмғқн•ң кІғмңјлЎң м¶”м •лҗңлӢӨ. мҷ„м „м—°кІ°мёө мң лӢӣ мҲҳлҘј 512лЎң кө¬м„ұн•ҳмҳҖмқ„ л•Ңмқҳ VGG16, Inception_V3, DenseNetмқҳ нҢҢлқјлҜён„°мҲҳлҘј нҷ•мқён•ҙ ліҙм•ҳмқ„ л•Ң VGG16 2мІң8л°ұл§Ңм—¬к°ң(Trainable: мІң3л°ұл§Ңм—¬к°ң, Non-trainable: мІң5л°ұл§Ңм—¬к°ң), Inception_V3 4мІң8л°ұл§Ңм—¬к°ң(Trainable: 2мІң6л°ұл§Ңм—¬к°ң, Non-trainable: 2мІң2л°ұл§Ңм—¬к°ң), DenseNet 3мІң3л°ұл§Ңм—¬к°ң(Trainable: 2мІң6л°ұл§Ңм—¬к°ң, Non-trainable: 7л°ұл§Ңм—¬к°ң)лЎң VGG16м—җ 비н•ҙ Inception_V3мҷҖ DenseNetмқҳ лӘЁлҚё нҢҢлқјлҜён„° мҲҳк°Җ м»Ө кіјлҢҖм Ғн•©мқҙ л°ңмғқн•ҳкё° мү¬мҡҙ мЎ°кұҙмһ„мқ„ м•Ң мҲҳ мһҲм—ҲлӢӨ. мқҙлҹ¬н•ң лӘЁлҚёл“Өмқҳ кё°ліё кө¬мЎ°лҠ” мң мӮ¬н•ҳкІҢ м„Өкі„н•ҳлҗҳ к№ҠмқҙлҘј мЎ°м Ҳн•ҳм—¬ н•ҷмҠөн•ңлӢӨл©ҙ кІҖмҰқ/н…ҢмҠӨнҠё м •нҷ•лҸ„к°Җ н–ҘмғҒлҗ мҲҳлҸ„ мһҲмңјлҰ¬лқј кё°лҢҖлҗҳм§Җл§Ң ліё м—°кө¬м—җм„ңлҠ” лі„лҸ„лЎң 진н–үн•ҳм§Җ м•Ҡм•ҳлӢӨ. 추нӣ„м—җлҠ” м§ҖмҶҚм Ғмқё лҚ°мқҙн„° нҷ•ліҙ, 추к°Җм Ғмқё лӘЁлҚёкіј мөңм Ғмқҳ н•ҳмқҙнҚјнҢҢлқјлҜён„° нғҗмғү л“ұмқ„ нҶөн•ҙ ліҙлӢӨ м •нҷ•лҸ„к°Җ н–ҘмғҒлҗң лӘЁлҚёмқ„ кө¬м¶•н•ҙ лӮҳк°Җм•ј н• кІғмқҙлӢӨ.




